 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmixing the Crowd: Learning Mixture-to-Set Speaker Embeddings for Enrollment-Free Target Speech Extraction
Apr 03, 2026Personalized or target speech extraction (TSE) typically needs a clean enrollment -- hard to obtain in real-world crowded environments. We remove the essential need for enrollment by predicting, from the mixture itself, a small set of per-speaker embeddings that serve as the control signal for extraction. Our model maps a noisy mixture directly to a small set of candidate speaker embeddings trained to align with a strong single-speaker speaker-embedding space via permutation-invariant teacher supervision. On noisy LibriMix, the resulting embeddings form a structured and clusterable identity space, outperforming WavLM+K-means and separation-derived embeddings in standard clustering metrics. Conditioning these embeddings into multiple extraction back-ends consistently improves objective quality and intelligibility, and generalizes to real DNS-Challenge recordings.
Interpreting A Pre-trained Model Is A Key For Model Architecture Optimization: A Case Study On Wav2Vec 2.0
Apr 07, 2021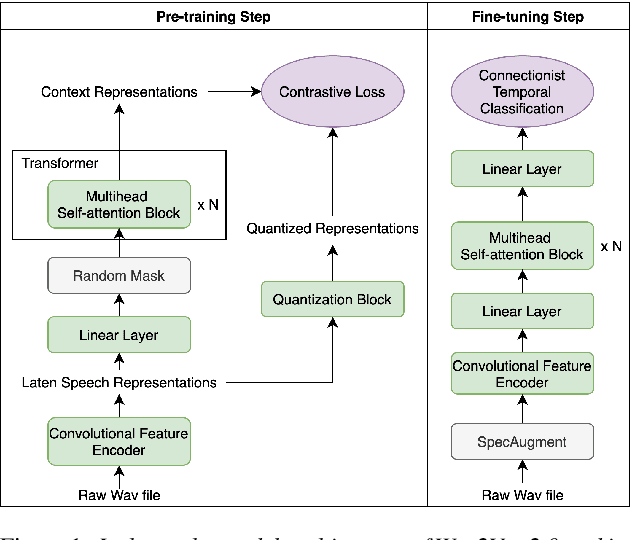
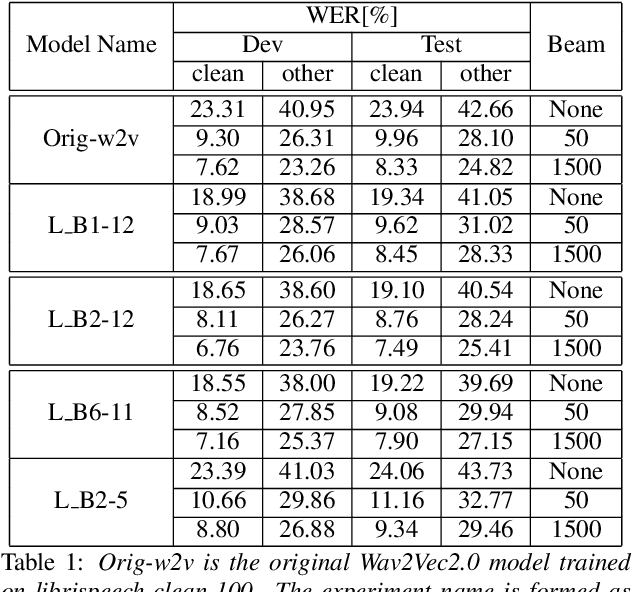
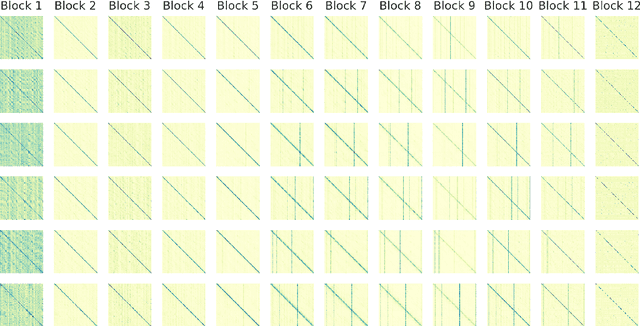
A deep Transformer model with good evaluation score does not mean each subnetwork (a.k.a transformer block) learns reasonable representation. Diagnosing abnormal representation and avoiding it can contribute to achieving a better evaluation score. We propose an innovative perspective for analyzing attention patterns: summarize block-level patterns and assume abnormal patterns contribute negative influence. We leverage Wav2Vec 2.0 as a research target and analyze a pre-trained model's pattern. All experiments leverage Librispeech-100-clean as training data. Through avoiding diagnosed abnormal ones, our custom Wav2Vec 2.0 outperforms the original version about 4.8% absolute word error rate (WER) on test-clean with viterbi decoding. Our version is still 0.9% better when decoding with a 4-gram language model. Moreover, we identify that avoiding abnormal patterns is the main contributor for performance boosting.
Refining Automatic Speech Recognition System for older adults
Nov 17, 2020
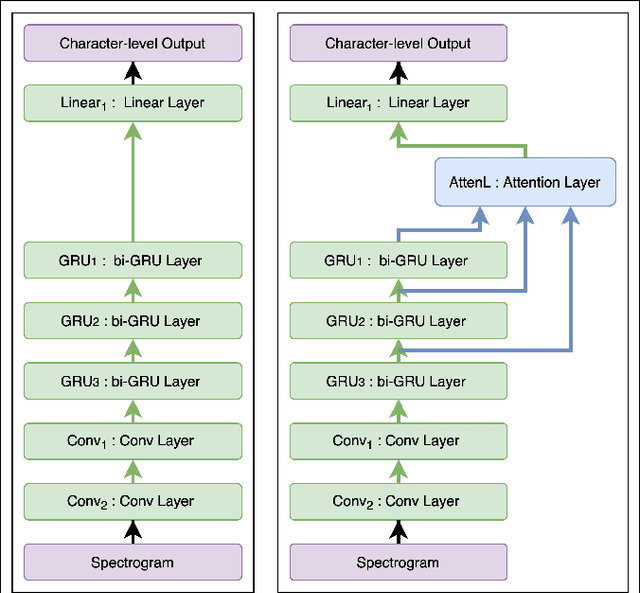
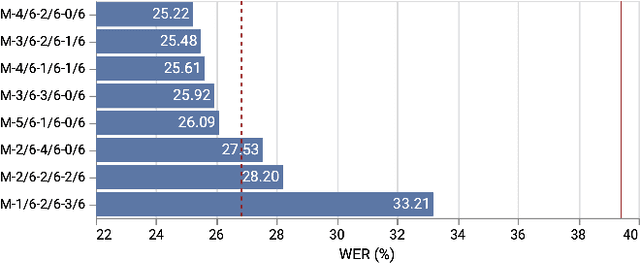
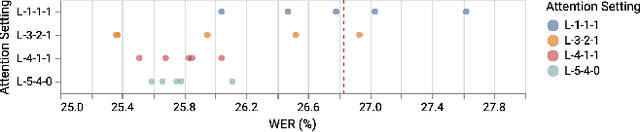
Building a high quality automatic speech recognition (ASR) system with limited training data has been a challenging task particularly for a narrow target population. Open-sourced ASR systems, trained on sufficient data from adults, are susceptible on seniors' speech due to acoustic mismatch between adults and seniors. With 12 hours of training data, we attempt to develop an ASR system for socially isolated seniors (80+ years old) with possible cognitive impairments. We experimentally identify that ASR for the adult population performs poorly on our target population and transfer learning (TL) can boost the system's performance. Standing on the fundamental idea of TL, tuning model parameters, we further improve the system by leveraging an attention mechanism to utilize the model's intermediate information. Our approach achieves 1.58% absolute improvements over the TL model.