 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting A Pre-trained Model Is A Key For Model Architecture Optimization: A Case Study On Wav2Vec 2.0
Paper and Code
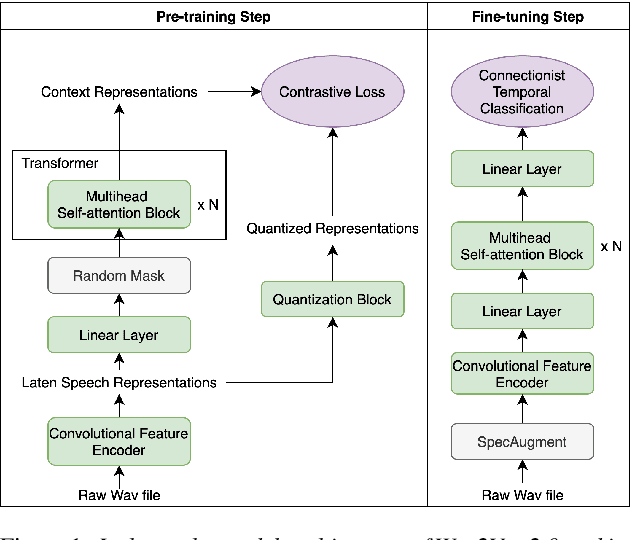
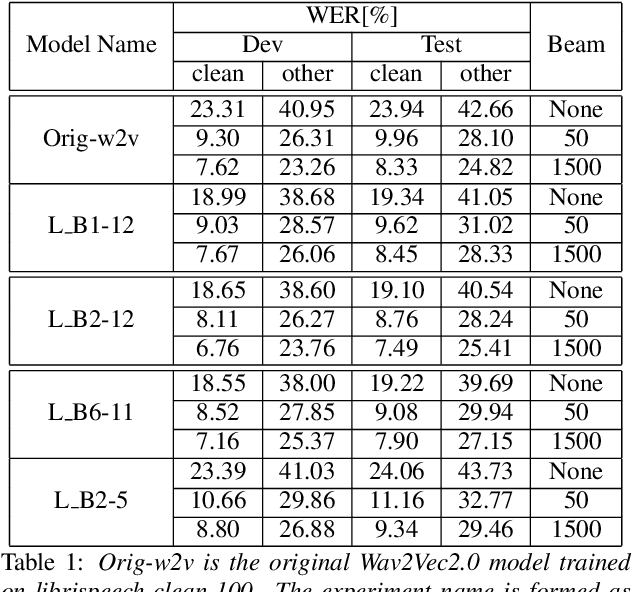
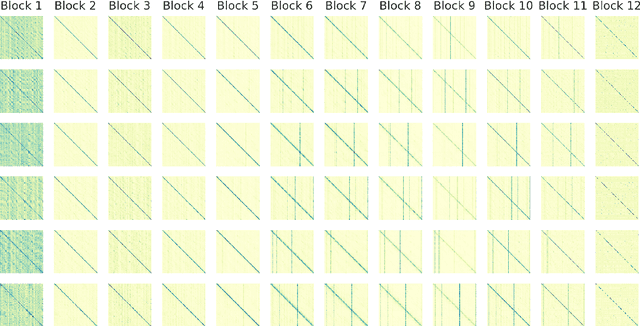
A deep Transformer model with good evaluation score does not mean each subnetwork (a.k.a transformer block) learns reasonable representation. Diagnosing abnormal representation and avoiding it can contribute to achieving a better evaluation score. We propose an innovative perspective for analyzing attention patterns: summarize block-level patterns and assume abnormal patterns contribute negative influence. We leverage Wav2Vec 2.0 as a research target and analyze a pre-trained model's pattern. All experiments leverage Librispeech-100-clean as training data. Through avoiding diagnosed abnormal ones, our custom Wav2Vec 2.0 outperforms the original version about 4.8% absolute word error rate (WER) on test-clean with viterbi decoding. Our version is still 0.9% better when decoding with a 4-gram language model. Moreover, we identify that avoiding abnormal patterns is the main contributor for performance boosting.