Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble based discriminative models for Visual Dialog Challenge 2018
Paper and Code
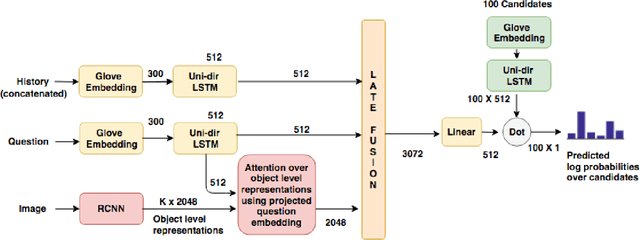

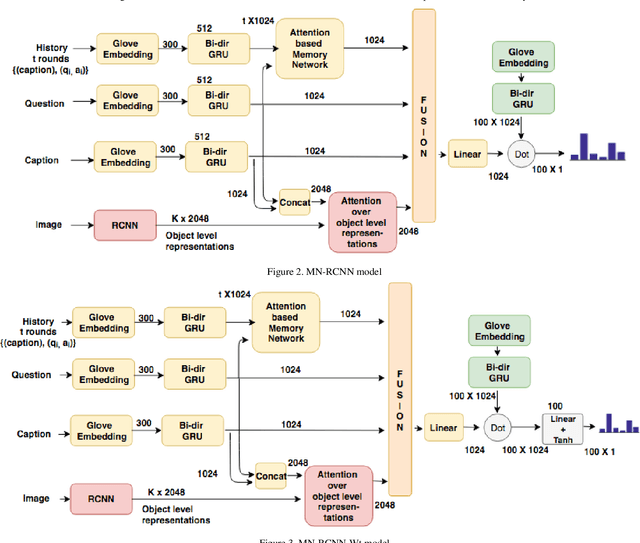
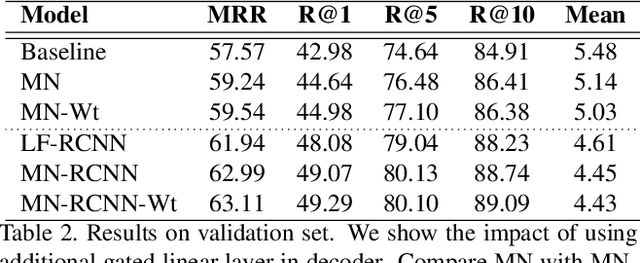
This manuscript describes our approach for the Visual Dialog Challenge 2018. We use an ensemble of three discriminative models with different encoders and decoders for our final submission. Our best performing model on 'test-std' split achieves the NDCG score of 55.46 and the MRR value of 63.77, securing third position in the challenge.
* Rankings: https://visualdialog.org/challenge/2018#winners
View paper on