 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision-Language Models Respect Contextual Integrity in Location Disclosure?
Feb 04, 2026Vision-language models (VLMs) have demonstrated strong performance in image geolocation, a capability further sharpened by frontier multimodal large reasoning models (MLRMs). This poses a significant privacy risk, as these widely accessible models can be exploited to infer sensitive locations from casually shared photos, often at street-level precision, potentially surpassing the level of detail the sharer consented or intended to disclose. While recent work has proposed applying a blanket restriction on geolocation disclosure to combat this risk, these measures fail to distinguish valid geolocation uses from malicious behavior. Instead, VLMs should maintain contextual integrity by reasoning about elements within an image to determine the appropriate level of information disclosure, balancing privacy and utility. To evaluate how well models respect contextual integrity, we introduce VLM-GEOPRIVACY, a benchmark that challenges VLMs to interpret latent social norms and contextual cues in real-world images and determine the appropriate level of location disclosure. Our evaluation of 14 leading VLMs shows that, despite their ability to precisely geolocate images, the models are poorly aligned with human privacy expectations. They often over-disclose in sensitive contexts and are vulnerable to prompt-based attacks. Our results call for new design principles in multimodal systems to incorporate context-conditioned privacy reasoning.
Didactic to Constructive: Turning Expert Solutions into Learnable Reasoning
Feb 02, 2026Improving the reasoning capabilities of large language models (LLMs) typically relies either on the model's ability to sample a correct solution to be reinforced or on the existence of a stronger model able to solve the problem. However, many difficult problems remain intractable for even current frontier models, preventing the extraction of valid training signals. A promising alternative is to leverage high-quality expert human solutions, yet naive imitation of this data fails because it is fundamentally out of distribution: expert solutions are typically didactic, containing implicit reasoning gaps intended for human readers rather than computational models. Furthermore, high-quality expert solutions are expensive, necessitating generalizable sample-efficient training methods. We propose Distribution Aligned Imitation Learning (DAIL), a two-step method that bridges the distributional gap by first transforming expert solutions into detailed, in-distribution reasoning traces and then applying a contrastive objective to focus learning on expert insights and methodologies. We find that DAIL can leverage fewer than 1000 high-quality expert solutions to achieve 10-25% pass@k gains on Qwen2.5-Instruct and Qwen3 models, improve reasoning efficiency by 2x to 4x, and enable out-of-domain generalization.
GeoRC: A Benchmark for Geolocation Reasoning Chains
Jan 29, 2026Vision Language Models (VLMs) are good at recognizing the global location of a photograph -- their geolocation prediction accuracy rivals the best human experts. But many VLMs are startlingly bad at explaining which image evidence led to their prediction, even when their location prediction is correct. The reasoning chains produced by VLMs frequently hallucinate scene attributes to support their location prediction (e.g. phantom writing, imagined infrastructure, misidentified flora). In this paper, we introduce the first benchmark for geolocation reasoning chains. We focus on the global location prediction task in the popular GeoGuessr game which draws from Google Street View spanning more than 100 countries. We collaborate with expert GeoGuessr players, including the reigning world champion, to produce 800 ground truth reasoning chains for 500 query scenes. These expert reasoning chains address hundreds of different discriminative visual attributes such as license plate shape, architecture, and soil properties to name just a few. We evaluate LLM-as-a-judge and VLM-as-a-judge strategies for scoring VLM-generated reasoning chains against our expert reasoning chains and find that Qwen 3 LLM-as-a-judge correlates best with human scoring. Our benchmark reveals that while large, closed-source VLMs such as Gemini and GPT 5 rival human experts at prediction locations, they still lag behind human experts when it comes to producing auditable reasoning chains. Open weights VLMs such as Llama and Qwen catastrophically fail on our benchmark -- they perform only slightly better than a baseline in which an LLM hallucinates a reasoning chain with oracle knowledge of the photo location but no visual information at all. We believe the gap between human experts and VLMs on this task points to VLM limitations at extracting fine-grained visual attributes from high resolution images.
Language Models can Self-Improve at State-Value Estimation for Better Search
Mar 04, 2025



Collecting ground truth task completion rewards or human demonstrations for multi-step reasoning tasks is often cost-prohibitive and time-consuming, especially in interactive domains like web tasks. To address this bottleneck, we present self-taught lookahead, a self-supervised method that leverages state-transition dynamics to train a value model capable of effectively guiding language model-controlled search. We find that moderately sized (8 billion parameters) open-weight value models improved with self-taught lookahead can match the performance of using a frontier LLM such as gpt-4o as the value model. Furthermore, we find that self-taught lookahead improves performance by 20% while reducing costs 37x compared to previous LLM-based tree search, without relying on ground truth rewards.
Granular Privacy Control for Geolocation with Vision Language Models
Jul 06, 2024

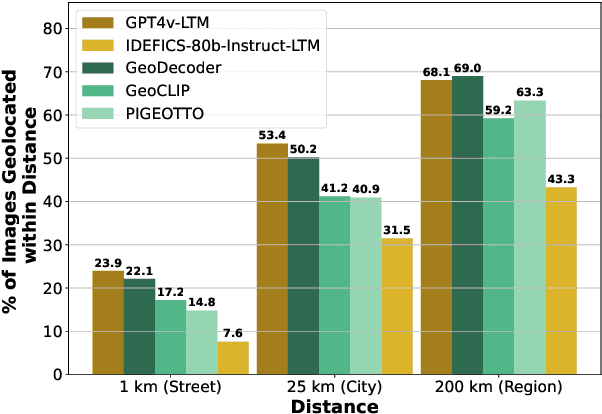
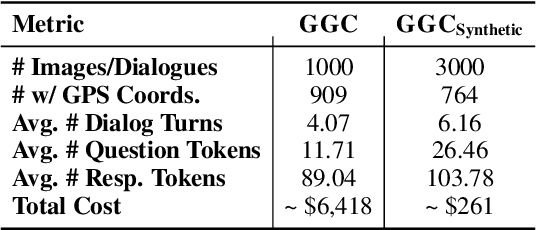
Vision Language Models (VLMs) are rapidly advancing in their capability to answer information-seeking questions. As these models are widely deployed in consumer applications, they could lead to new privacy risks due to emergent abilities to identify people in photos, geolocate images, etc. As we demonstrate, somewhat surprisingly, current open-source and proprietary VLMs are very capable image geolocators, making widespread geolocation with VLMs an immediate privacy risk, rather than merely a theoretical future concern. As a first step to address this challenge, we develop a new benchmark, GPTGeoChat, to test the ability of VLMs to moderate geolocation dialogues with users. We collect a set of 1,000 image geolocation conversations between in-house annotators and GPT-4v, which are annotated with the granularity of location information revealed at each turn. Using this new dataset, we evaluate the ability of various VLMs to moderate GPT-4v geolocation conversations by determining when too much location information has been revealed. We find that custom fine-tuned models perform on par with prompted API-based models when identifying leaked location information at the country or city level; however, fine-tuning on supervised data appears to be needed to accurately moderate finer granularities, such as the name of a restaurant or building.
Can Language Models be Instructed to Protect Personal Information?
Oct 03, 2023



Large multimodal language models have proven transformative in numerous applications. However, these models have been shown to memorize and leak pre-training data, raising serious user privacy and information security concerns. While data leaks should be prevented, it is also crucial to examine the trade-off between the privacy protection and model utility of proposed approaches. In this paper, we introduce PrivQA -- a multimodal benchmark to assess this privacy/utility trade-off when a model is instructed to protect specific categories of personal information in a simulated scenario. We also propose a technique to iteratively self-moderate responses, which significantly improves privacy. However, through a series of red-teaming experiments, we find that adversaries can also easily circumvent these protections with simple jailbreaking methods through textual and/or image inputs. We believe PrivQA has the potential to support the development of new models with improved privacy protections, as well as the adversarial robustness of these protections. We release the entire PrivQA dataset at https://llm-access-control.github.io/.
Human-in-the-loop Evaluation for Early Misinformation Detection: A Case Study of COVID-19 Treatments
Dec 19, 2022We present a human-in-the-loop evaluation framework for fact-checking novel misinformation claims and identifying social media messages that violate relevant policies. Our approach extracts structured representations of check-worthy claims, which are aggregated and ranked for review. Stance classifiers are then used to identify tweets supporting novel misinformation claims, which are further reviewed to determine whether they violate relevant policies. To demonstrate the feasibility of our approach, we develop a baseline system based on modern NLP methods for human-in-the-loop fact-checking in the domain of COVID-19 treatments. Using our baseline system, we show that human fact-checkers can identify 124 tweets per hour that violate Twitter's policies on COVID-19 misinformation. We will make our code, data, and detailed annotation guidelines available to support the evaluation of human-in-the-loop systems that identify novel misinformation directly from raw user-generated content.