 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Motion Synthesis: Masked Audio-Text Conditioned Spatio-Temporal Transformers
Sep 03, 2024Our research presents a novel motion generation framework designed to produce whole-body motion sequences conditioned on multiple modalities simultaneously, specifically text and audio inputs. Leveraging Vector Quantized Variational Autoencoders (VQVAEs) for motion discretization and a bidirectional Masked Language Modeling (MLM) strategy for efficient token prediction, our approach achieves improved processing efficiency and coherence in the generated motions. By integrating spatial attention mechanisms and a token critic we ensure consistency and naturalness in the generated motions. This framework expands the possibilities of motion generation, addressing the limitations of existing approaches and opening avenues for multimodal motion synthesis.
MAGMA: Music Aligned Generative Motion Autodecoder
Sep 03, 2023Mapping music to dance is a challenging problem that requires spatial and temporal coherence along with a continual synchronization with the music's progression. Taking inspiration from large language models, we introduce a 2-step approach for generating dance using a Vector Quantized-Variational Autoencoder (VQ-VAE) to distill motion into primitives and train a Transformer decoder to learn the correct sequencing of these primitives. We also evaluate the importance of music representations by comparing naive music feature extraction using Librosa to deep audio representations generated by state-of-the-art audio compression algorithms. Additionally, we train variations of the motion generator using relative and absolute positional encodings to determine the effect on generated motion quality when generating arbitrarily long sequence lengths. Our proposed approach achieve state-of-the-art results in music-to-motion generation benchmarks and enables the real-time generation of considerably longer motion sequences, the ability to chain multiple motion sequences seamlessly, and easy customization of motion sequences to meet style requirements.
Learning to regulate 3D head shape by removing occluding hair from in-the-wild images
Aug 25, 2022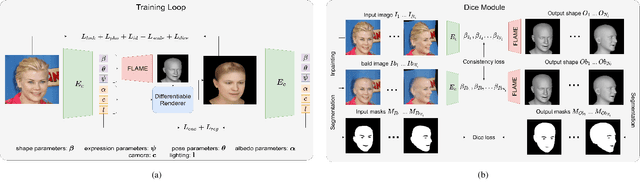
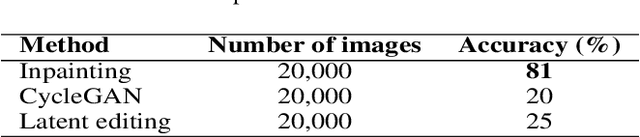
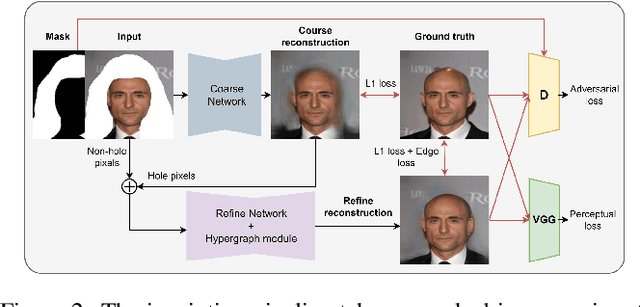
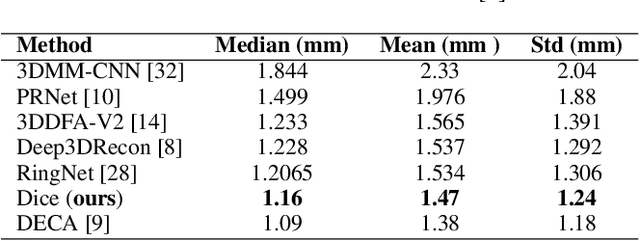
Recent 3D face reconstruction methods reconstruct the entire head compared to earlier approaches which only model the face. Although these methods accurately reconstruct facial features, they do not explicitly regulate the upper part of the head. Extracting information about this part of the head is challenging due to varying degrees of occlusion by hair. We present a novel approach for modeling the upper head by removing occluding hair and reconstructing the skin, revealing information about the head shape. We introduce three objectives: 1) a dice consistency loss that enforces similarity between the overall head shape of the source and rendered image, 2) a scale consistency loss to ensure that head shape is accurately reproduced even if the upper part of the head is not visible, and 3) a 71 landmark detector trained using a moving average loss function to detect additional landmarks on the head. These objectives are used to train an encoder in an unsupervised manner to regress FLAME parameters from in-the-wild input images. Our unsupervised 3DMM model achieves state-of-the-art results on popular benchmarks and can be used to infer the head shape, facial features, and textures for direct use in animation or avatar creation.