 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Reinforcement Learning for Dexterous Manipulation
Jan 24, 2023Existing learning approaches to dexterous manipulation use demonstrations or interactions with the environment to train black-box neural networks that provide little control over how the robot learns the skills or how it would perform post training. These approaches pose significant challenges when implemented on physical platforms given that, during initial stages of training, the robot's behavior could be erratic and potentially harmful to its own hardware, the environment, or any humans in the vicinity. A potential way to address these limitations is to add constraints during learning that restrict and guide the robot's behavior during training as well as roll outs. Inspired by the success of constrained approaches in other domains, we investigate the effects of adding position-based constraints to a 24-DOF robot hand learning to perform object relocation using Constrained Policy Optimization. We find that a simple geometric constraint can ensure the robot learns to move towards the object sooner than without constraints. Further, training with this constraint requires a similar number of samples as its unconstrained counterpart to master the skill. These findings shed light on how simple constraints can help robots achieve sensible and safe behavior quickly and ease concerns surrounding hardware deployment. We also investigate the effects of the strictness of these constraints and report findings that provide insights into how different degrees of strictness affect learning outcomes. Our code is available at https://github.com/GT-STAR-Lab/constrained-rl-dexterous-manipulation.
Evaluating the Effectiveness of Corrective Demonstrations and a Low-Cost Sensor for Dexterous Manipulation
Apr 15, 2022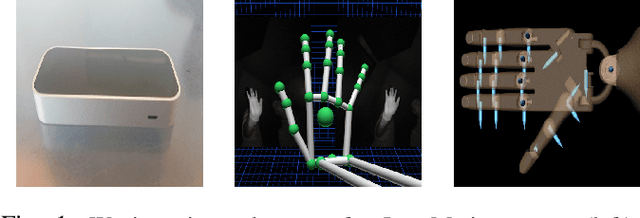


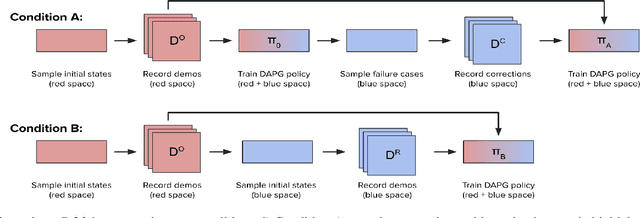
Imitation learning is a promising approach to help robots acquire dexterous manipulation capabilities without the need for a carefully-designed reward or a significant computational effort. However, existing imitation learning approaches require sophisticated data collection infrastructure and struggle to generalize beyond the training distribution. One way to address this limitation is to gather additional data that better represents the full operating conditions. In this work, we investigate characteristics of such additional demonstrations and their impact on performance. Specifically, we study the effects of corrective and randomly-sampled additional demonstrations on learning a policy that guides a five-fingered robot hand through a pick-and-place task. Our results suggest that corrective demonstrations considerably outperform randomly-sampled demonstrations, when the proportion of additional demonstrations sampled from the full task distribution is larger than the number of original demonstrations sampled from a restrictive training distribution. Conversely, when the number of original demonstrations are higher than that of additional demonstrations, we find no significant differences between corrective and randomly-sampled additional demonstrations. These results provide insights into the inherent trade-off between the effort required to collect corrective demonstrations and their relative benefits over randomly-sampled demonstrations. Additionally, we show that inexpensive vision-based sensors, such as LeapMotion, can be used to dramatically reduce the cost of providing demonstrations for dexterous manipulation tasks. Our code is available at https://github.com/GT-STAR-Lab/corrective-demos-dexterous-manipulation.