 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant Set Clustering and Pooling for Multi-View 3D Object Recognition
Paper and Code
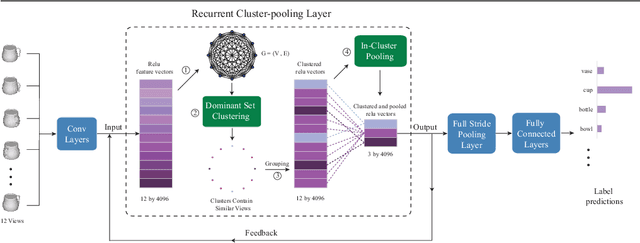
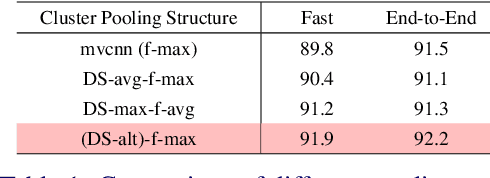
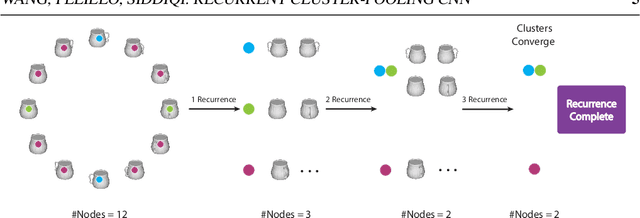
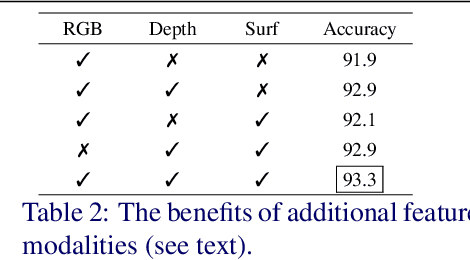
View based strategies for 3D object recognition have proven to be very successful. The state-of-the-art methods now achieve over 90% correct category level recognition performance on appearance images. We improve upon these methods by introducing a view clustering and pooling layer based on dominant sets. The key idea is to pool information from views which are similar and thus belong to the same cluster. The pooled feature vectors are then fed as inputs to the same layer, in a recurrent fashion. This recurrent clustering and pooling module, when inserted in an off-the-shelf pretrained CNN, boosts performance for multi-view 3D object recognition, achieving a new state of the art test set recognition accuracy of 93.8% on the ModelNet 40 database. We also explore a fast approximate learning strategy for our cluster-pooling CNN, which, while sacrificing end-to-end learning, greatly improves its training efficiency with only a slight reduction of recognition accuracy to 93.3%. Our implementation is available at https://github.com/fate3439/dscnn.