 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-semi-supervised Learning to Learn from NoisyLabeled Data
Paper and Code
Nov 03, 2020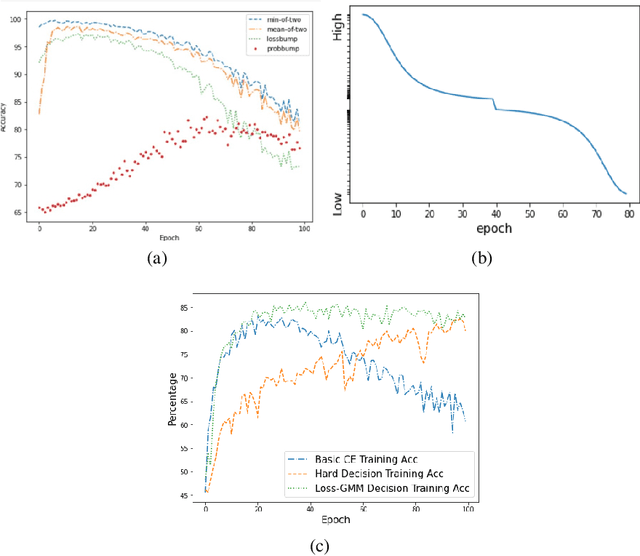
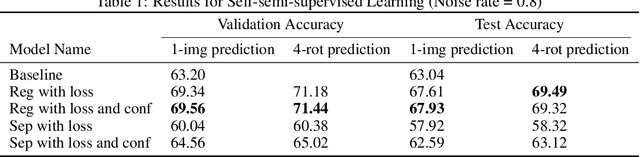
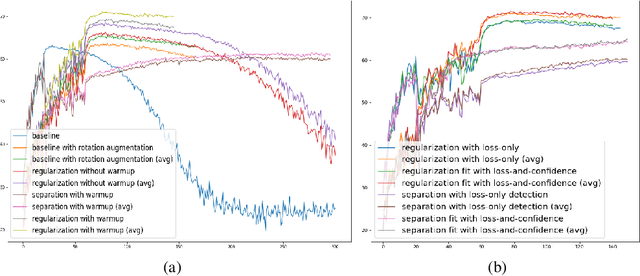
The remarkable success of today's deep neural networks highly depends on a massive number of correctly labeled data. However, it is rather costly to obtain high-quality human-labeled data, leading to the active research area of training models robust to noisy labels. To achieve this goal, on the one hand, many papers have been dedicated to differentiating noisy labels from clean ones to increase the generalization of DNN. On the other hand, the increasingly prevalent methods of self-semi-supervised learning have been proven to benefit the tasks when labels are incomplete. By 'semi' we regard the wrongly labeled data detected as un-labeled data; by 'self' we choose a self-supervised technique to conduct semi-supervised learning. In this project, we designed methods to more accurately differentiate clean and noisy labels and borrowed the wisdom of self-semi-supervised learning to train noisy labeled data.