 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval and Localization with Observation Constraints
Aug 19, 2021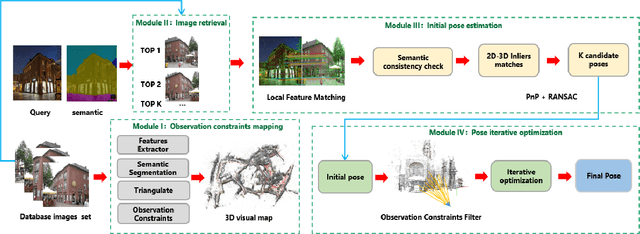
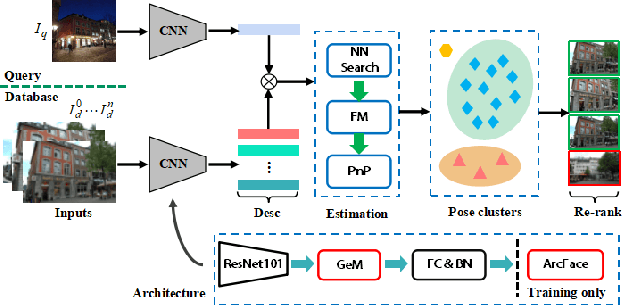

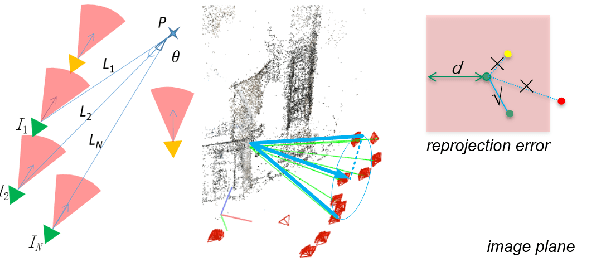
Accurate visual re-localization is very critical to many artificial intelligence applications, such as augmented reality, virtual reality, robotics and autonomous driving. To accomplish this task, we propose an integrated visual re-localization method called RLOCS by combining image retrieval, semantic consistency and geometry verification to achieve accurate estimations. The localization pipeline is designed as a coarse-to-fine paradigm. In the retrieval part, we cascade the architecture of ResNet101-GeM-ArcFace and employ DBSCAN followed by spatial verification to obtain a better initial coarse pose. We design a module called observation constraints, which combines geometry information and semantic consistency for filtering outliers. Comprehensive experiments are conducted on open datasets, including retrieval on R-Oxford5k and R-Paris6k, semantic segmentation on Cityscapes, localization on Aachen Day-Night and InLoc. By creatively modifying separate modules in the total pipeline, our method achieves many performance improvements on the challenging localization benchmarks.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Visual Localization Using Semantic Segmentation and Depth Prediction
May 25, 2020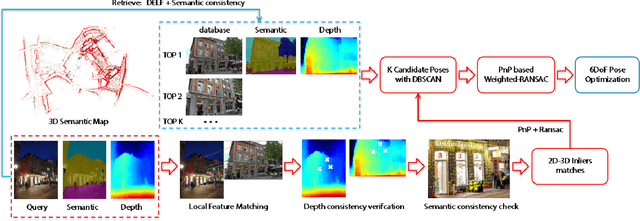


In this paper, we propose a monocular visual localization pipeline leveraging semantic and depth cues. We apply semantic consistency evaluation to rank the image retrieval results and a practical clustering technique to reject estimation outliers. In addition, we demonstrate a substantial performance boost achieved with a combination of multiple feature extractors. Furthermore, by using depth prediction with a deep neural network, we show that a significant amount of falsely matched keypoints are identified and eliminated. The proposed pipeline outperforms most of the existing approaches at the Long-Term Visual Localization benchmark 2020.