 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Signals: Understanding Model Disagreement in Multimodal Empathy Detection
May 20, 2025Multimodal models play a key role in empathy detection, but their performance can suffer when modalities provide conflicting cues. To understand these failures, we examine cases where unimodal and multimodal predictions diverge. Using fine-tuned models for text, audio, and video, along with a gated fusion model, we find that such disagreements often reflect underlying ambiguity, as evidenced by annotator uncertainty. Our analysis shows that dominant signals in one modality can mislead fusion when unsupported by others. We also observe that humans, like models, do not consistently benefit from multimodal input. These insights position disagreement as a useful diagnostic signal for identifying challenging examples and improving empathy system robustness.
Benchmarking LLM Code Generation for Audio Programming with Visual Dataflow Languages
Sep 01, 2024



Node-based programming languages are increasingly popular in media arts coding domains. These languages are designed to be accessible to users with limited coding experience, allowing them to achieve creative output without an extensive programming background. Using LLM-based code generation to further lower the barrier to creative output is an exciting opportunity. However, the best strategy for code generation for visual node-based programming languages is still an open question. In particular, such languages have multiple levels of representation in text, each of which may be used for code generation. In this work, we explore the performance of LLM code generation in audio programming tasks in visual programming languages at multiple levels of representation. We explore code generation through metaprogramming code representations for these languages (i.e., coding the language using a different high-level text-based programming language), as well as through direct node generation with JSON. We evaluate code generated in this way for two visual languages for audio programming on a benchmark set of coding problems. We measure both correctness and complexity of the generated code. We find that metaprogramming results in more semantically correct generated code, given that the code is well-formed (i.e., is syntactically correct and runs). We also find that prompting for richer metaprogramming using randomness and loops led to more complex code.
An Empirical Study of Automated Mislabel Detection in Real World Vision Datasets
Dec 02, 2023Major advancements in computer vision can primarily be attributed to the use of labeled datasets. However, acquiring labels for datasets often results in errors which can harm model performance. Recent works have proposed methods to automatically identify mislabeled images, but developing strategies to effectively implement them in real world datasets has been sparsely explored. Towards improved data-centric methods for cleaning real world vision datasets, we first conduct more than 200 experiments carefully benchmarking recently developed automated mislabel detection methods on multiple datasets under a variety of synthetic and real noise settings with varying noise levels. We compare these methods to a Simple and Efficient Mislabel Detector (SEMD) that we craft, and find that SEMD performs similarly to or outperforms prior mislabel detection approaches. We then apply SEMD to multiple real world computer vision datasets and test how dataset size, mislabel removal strategy, and mislabel removal amount further affect model performance after retraining on the cleaned data. With careful design of the approach, we find that mislabel removal leads per-class performance improvements of up to 8% of a retrained classifier in smaller data regimes.
Dynamic Social Media Monitoring for Fast-Evolving Online Discussions
Feb 24, 2021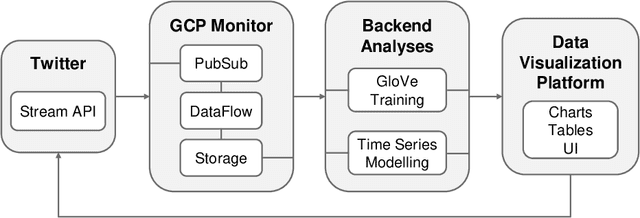
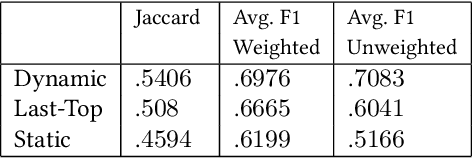
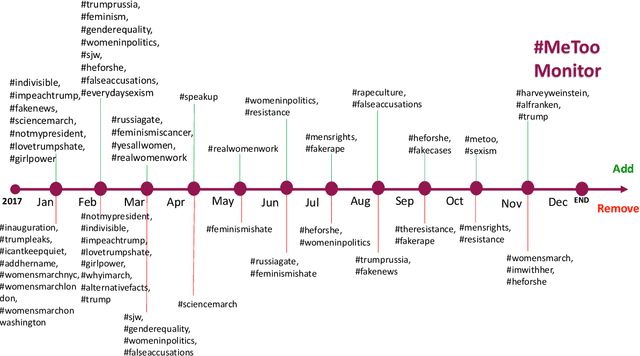
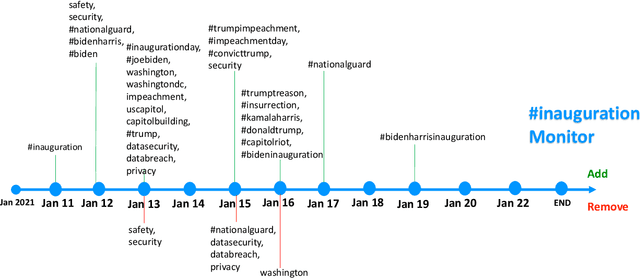
Tracking and collecting fast-evolving online discussions provides vast data for studying social media usage and its role in people's public lives. However, collecting social media data using a static set of keywords fails to satisfy the growing need to monitor dynamic conversations and to study fast-changing topics. We propose a dynamic keyword search method to maximize the coverage of relevant information in fast-evolving online discussions. The method uses word embedding models to represent the semantic relations between keywords and predictive models to forecast the future time series. We also implement a visual user interface to aid in the decision-making process in each round of keyword updates. This allows for both human-assisted tracking and fully-automated data collection. In simulations using historical #MeToo data in 2017, our human-assisted tracking method outperforms the traditional static baseline method significantly, with 37.1% higher F-1 score than traditional static monitors in tracking the top trending keywords. We conduct a contemporary case study to cover dynamic conversations about the recent Presidential Inauguration and to test the dynamic data collection system. Our case studies reflect the effectiveness of our process and also points to the potential challenges in future deployment.
Finding Social Media Trolls: Dynamic Keyword Selection Methods for Rapidly-Evolving Online Debates
Nov 16, 2019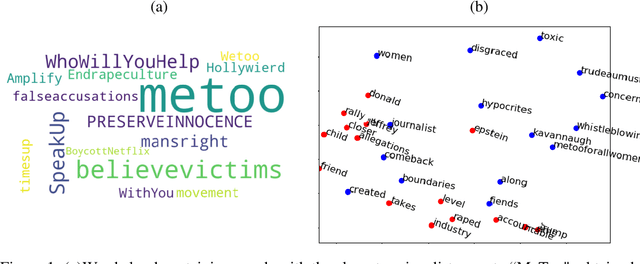

Online harassment is a significant social problem. Prevention of online harassment requires rapid detection of harassing, offensive, and negative social media posts. In this paper, we propose the use of word embedding models to identify offensive and harassing social media messages in two aspects: detecting fast-changing topics for more effective data collection and representing word semantics in different domains. We demonstrate with preliminary results that using the GloVe (Global Vectors for Word Representation) model facilitates the discovery of new and relevant keywords to use for data collection and trolling detection. Our paper concludes with a discussion of a research agenda to further develop and test word embedding models for identification of social media harassment and trolling.