 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Automated Mislabel Detection in Real World Vision Datasets
Dec 02, 2023Major advancements in computer vision can primarily be attributed to the use of labeled datasets. However, acquiring labels for datasets often results in errors which can harm model performance. Recent works have proposed methods to automatically identify mislabeled images, but developing strategies to effectively implement them in real world datasets has been sparsely explored. Towards improved data-centric methods for cleaning real world vision datasets, we first conduct more than 200 experiments carefully benchmarking recently developed automated mislabel detection methods on multiple datasets under a variety of synthetic and real noise settings with varying noise levels. We compare these methods to a Simple and Efficient Mislabel Detector (SEMD) that we craft, and find that SEMD performs similarly to or outperforms prior mislabel detection approaches. We then apply SEMD to multiple real world computer vision datasets and test how dataset size, mislabel removal strategy, and mislabel removal amount further affect model performance after retraining on the cleaned data. With careful design of the approach, we find that mislabel removal leads per-class performance improvements of up to 8% of a retrained classifier in smaller data regimes.
Advancing Humor-Focused Sentiment Analysis through Improved Contextualized Embeddings and Model Architecture
Nov 23, 2020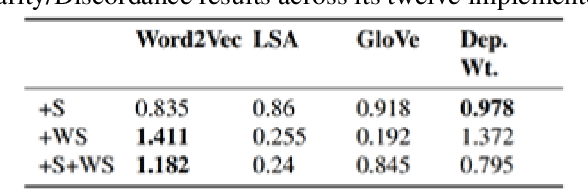
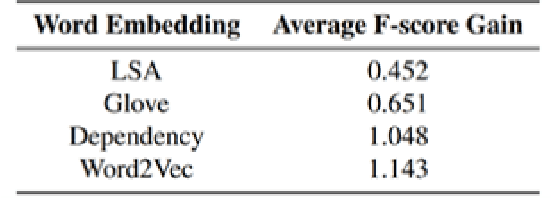
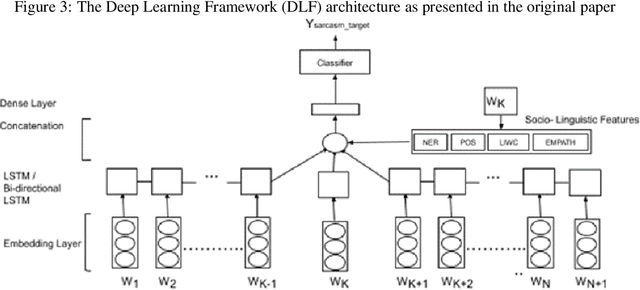
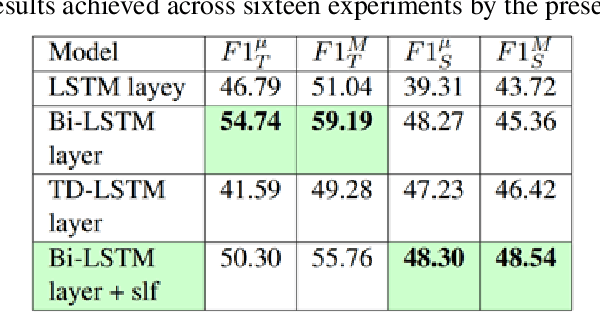
Humor is a natural and fundamental component of human interactions. When correctly applied, humor allows us to express thoughts and feelings conveniently and effectively, increasing interpersonal affection, likeability, and trust. However, understanding the use of humor is a computationally challenging task from the perspective of humor-aware language processing models. As language models become ubiquitous through virtual-assistants and IOT devices, the need to develop humor-aware models rises exponentially. To further improve the state-of-the-art capacity to perform this particular sentiment-analysis task we must explore models that incorporate contextualized and nonverbal elements in their design. Ideally, we seek architectures accepting non-verbal elements as additional embedded inputs to the model, alongside the original sentence-embedded input. This survey thus analyses the current state of research in techniques for improved contextualized embedding incorporating nonverbal information, as well as newly proposed deep architectures to improve context retention on top of popular word-embeddings methods.