 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Livelihood Indicators from Crowdsourced Street Level Images
Jun 27, 2020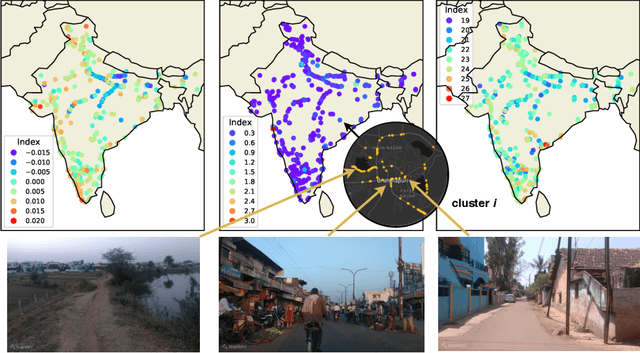
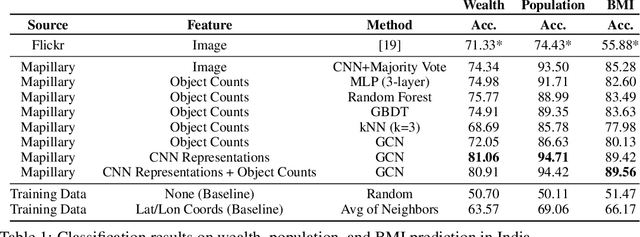
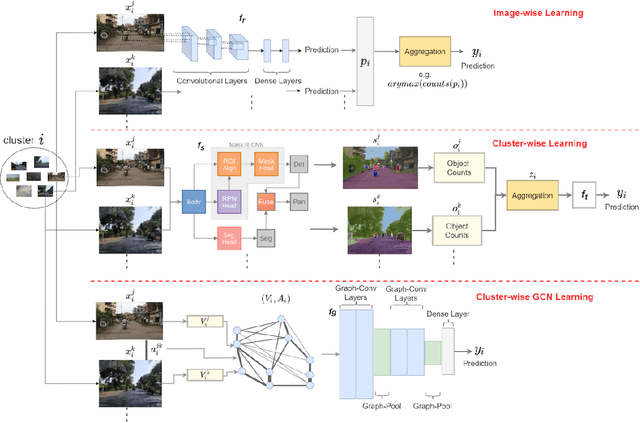
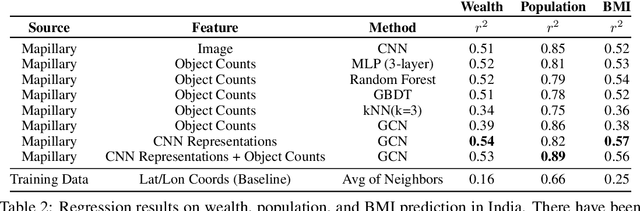
Major decisions from governments and other large organizations rely on measurements of the populace's well-being, but making such measurements at a broad scale is expensive and thus infrequent in much of the developing world. We propose an inexpensive, scalable, and interpretable approach to predict key livelihood indicators from public crowd-sourced street-level imagery. Such imagery can be cheaply collected and more frequently updated compared to traditional surveying methods, while containing plausibly relevant information for a range of livelihood indicators. We propose two approaches to learn from the street-level imagery. First method creates multihousehold cluster representations by detecting informative objects and the second method uses a graph-based approach that leverages the inherent structure between images. By visualizing what features are important to a model and how they are used, we can help end-user organizations understand the models and offer an alternate approach for index estimation that uses cheaply obtained roadway features. By comparing our results against ground data collected in nationally-representative household surveys, we show our approach can be used to accurately predict indicators of poverty, population, and health across India.
A Free Lunch in Generating Datasets: Building a VQG and VQA System with Attention and Humans in the Loop
Nov 30, 2019

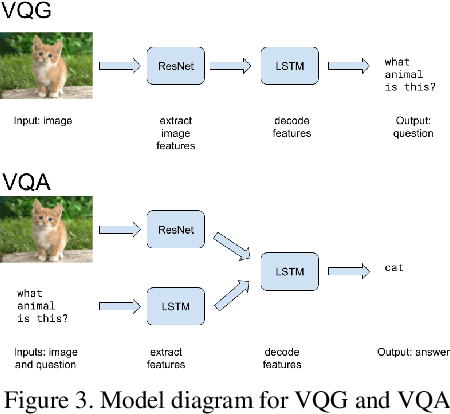
Despite their importance in training artificial intelligence systems, large datasets remain challenging to acquire. For example, the ImageNet dataset required fourteen million labels of basic human knowledge, such as whether an image contains a chair. Unfortunately, this knowledge is so simple that it is tedious for human annotators but also tacit enough such that they are necessary. However, human collaborative efforts for tasks like labeling massive amounts of data are costly, inconsistent, and prone to failure, and this method does not resolve the issue of the resulting dataset being static in nature. What if we asked people questions they want to answer and collected their responses as data? This would mean we could gather data at a much lower cost, and expanding a dataset would simply become a matter of asking more questions. We focus on the task of Visual Question Answering (VQA) and propose a system that uses Visual Question Generation (VQG) to produce questions, asks them to social media users, and collects their responses. We present two models that can then parse clean answers from the noisy human responses significantly better than our baselines, with the goal of eventually incorporating the answers into a Visual Question Answering (VQA) dataset. By demonstrating how our system can collect large amounts of data at little to no cost, we envision similar systems being used to improve performance on other tasks in the future.