 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Free Lunch in Generating Datasets: Building a VQG and VQA System with Attention and Humans in the Loop
Nov 30, 2019

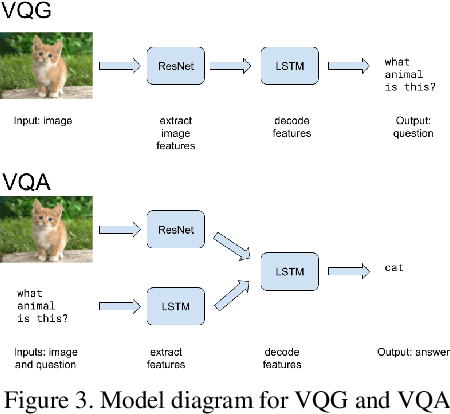
Despite their importance in training artificial intelligence systems, large datasets remain challenging to acquire. For example, the ImageNet dataset required fourteen million labels of basic human knowledge, such as whether an image contains a chair. Unfortunately, this knowledge is so simple that it is tedious for human annotators but also tacit enough such that they are necessary. However, human collaborative efforts for tasks like labeling massive amounts of data are costly, inconsistent, and prone to failure, and this method does not resolve the issue of the resulting dataset being static in nature. What if we asked people questions they want to answer and collected their responses as data? This would mean we could gather data at a much lower cost, and expanding a dataset would simply become a matter of asking more questions. We focus on the task of Visual Question Answering (VQA) and propose a system that uses Visual Question Generation (VQG) to produce questions, asks them to social media users, and collects their responses. We present two models that can then parse clean answers from the noisy human responses significantly better than our baselines, with the goal of eventually incorporating the answers into a Visual Question Answering (VQA) dataset. By demonstrating how our system can collect large amounts of data at little to no cost, we envision similar systems being used to improve performance on other tasks in the future.