 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Privacy to Generalization: Linear Max-Information Bounds for DP-SGD
May 25, 2026Understanding the relationship between generalization and privacy remains a central challenge in modern machine learning theory, particularly for deep networks trained by variants of differentially private stochastic gradient descent (DP-SGD). In this work we make progress on this persistent open problem by proving a finite-sample bound on the approximate max-information of DP-SGD that exhibits scaling properties comparable with (Dwork et al, 2015)'s classic result for $ε$-differentially private algorithms, namely at most linear in the dataset size. From our result we obtain a general-purpose PAC-Bayes generalization bound in which the necessary prior distribution can be learned by DP-SGD, as well as a generalization bound for DP-SGD-trained models themselves, with a complexity term that is fully explicit and controlled by the optimization hyperparameters.
Federated Learning with Unlabeled Clients: Personalization Can Happen in Low Dimensions
May 21, 2025Personalized federated learning has emerged as a popular approach to training on devices holding statistically heterogeneous data, known as clients. However, most existing approaches require a client to have labeled data for training or finetuning in order to obtain their own personalized model. In this paper we address this by proposing FLowDUP, a novel method that is able to generate a personalized model using only a forward pass with unlabeled data. The generated model parameters reside in a low-dimensional subspace, enabling efficient communication and computation. FLowDUP's learning objective is theoretically motivated by our new transductive multi-task PAC-Bayesian generalization bound, that provides performance guarantees for unlabeled clients. The objective is structured in such a way that it allows both clients with labeled data and clients with only unlabeled data to contribute to the training process. To supplement our theoretical results we carry out a thorough experimental evaluation of FLowDUP, demonstrating strong empirical performance on a range of datasets with differing sorts of statistically heterogeneous clients. Through numerous ablation studies, we test the efficacy of the individual components of the method.
Fast Rate Bounds for Multi-Task and Meta-Learning with Different Sample Sizes
May 21, 2025We present new fast-rate generalization bounds for multi-task and meta-learning in the unbalanced setting, i.e. when the tasks have training sets of different sizes, as is typically the case in real-world scenarios. Previously, only standard-rate bounds were known for this situation, while fast-rate bounds were limited to the setting where all training sets are of equal size. Our new bounds are numerically computable as well as interpretable, and we demonstrate their flexibility in handling a number of cases where they give stronger guarantees than previous bounds. Besides the bounds themselves, we also make conceptual contributions: we demonstrate that the unbalanced multi-task setting has different statistical properties than the balanced situation, specifically that proofs from the balanced situation do not carry over to the unbalanced setting. Additionally, we shed light on the fact that the unbalanced situation allows two meaningful definitions of multi-task risk, depending on whether if all tasks should be considered equally important or if sample-rich tasks should receive more weight than sample-poor ones.
Deep Multi-Task Learning Has Low Amortized Intrinsic Dimensionality
Jan 31, 2025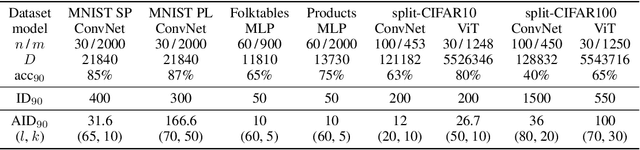
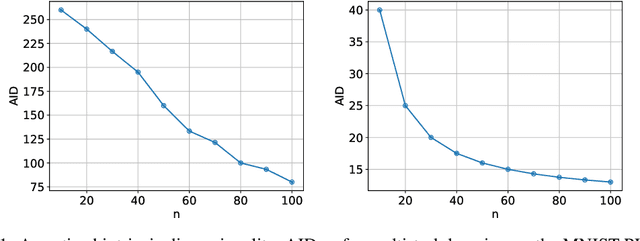


Deep learning methods are known to generalize well from training to future data, even in an overparametrized regime, where they could easily overfit. One explanation for this phenomenon is that even when their *ambient dimensionality*, (i.e. the number of parameters) is large, the models' *intrinsic dimensionality* is small, i.e. their learning takes place in a small subspace of all possible weight configurations. In this work, we confirm this phenomenon in the setting of *deep multi-task learning*. We introduce a method to parametrize multi-task network directly in the low-dimensional space, facilitated by the use of *random expansions* techniques. We then show that high-accuracy multi-task solutions can be found with much smaller intrinsic dimensionality (fewer free parameters) than what single-task learning requires. Subsequently, we show that the low-dimensional representations in combination with *weight compression* and *PAC-Bayesian* reasoning lead to the first *non-vacuous generalization bounds* for deep multi-task networks.
DP-KAN: Differentially Private Kolmogorov-Arnold Networks
Jul 17, 2024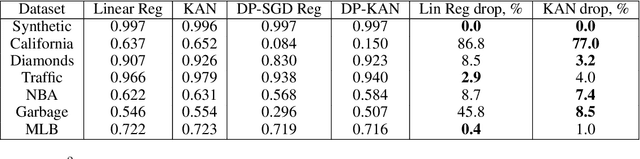

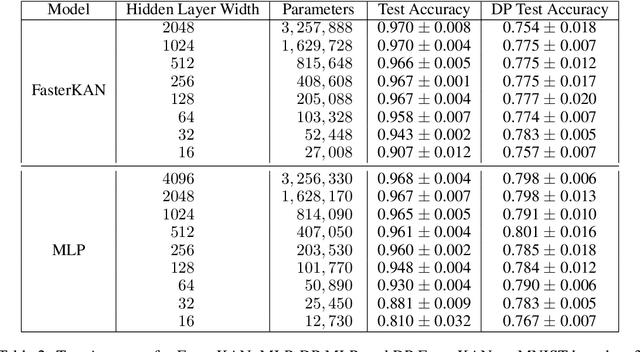
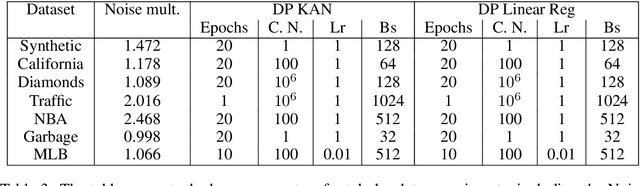
We study the Kolmogorov-Arnold Network (KAN), recently proposed as an alternative to the classical Multilayer Perceptron (MLP), in the application for differentially private model training. Using the DP-SGD algorithm, we demonstrate that KAN can be made private in a straightforward manner and evaluated its performance across several datasets. Our results indicate that the accuracy of KAN is not only comparable with MLP but also experiences similar deterioration due to privacy constraints, making it suitable for differentially private model training.
More Flexible PAC-Bayesian Meta-Learning by Learning Learning Algorithms
Feb 06, 2024We introduce a new framework for studying meta-learning methods using PAC-Bayesian theory. Its main advantage over previous work is that it allows for more flexibility in how the transfer of knowledge between tasks is realized. For previous approaches, this could only happen indirectly, by means of learning prior distributions over models. In contrast, the new generalization bounds that we prove express the process of meta-learning much more directly as learning the learning algorithm that should be used for future tasks. The flexibility of our framework makes it suitable to analyze a wide range of meta-learning mechanisms and even design new mechanisms. Other than our theoretical contributions we also show empirically that our framework improves the prediction quality in practical meta-learning mechanisms.
PeFLL: A Lifelong Learning Approach to Personalized Federated Learning
Jun 08, 2023Personalized federated learning (pFL) has emerged as a popular approach to dealing with the challenge of statistical heterogeneity between the data distributions of the participating clients. Instead of learning a single global model, pFL aims to learn an individual model for each client while still making use of the data available at other clients. In this work, we present PeFLL, a new pFL approach rooted in lifelong learning that performs well not only on clients present during its training phase, but also on any that may emerge in the future. PeFLL learns to output client specific models by jointly training an embedding network and a hypernetwork. The embedding network learns to represent clients in a latent descriptor space in a way that reflects their similarity to each other. The hypernetwork learns a mapping from this latent space to the space of possible client models. We demonstrate experimentally that PeFLL produces models of superior accuracy compared to previous methods, especially for clients not seen during training, and that it scales well to large numbers of clients. Moreover, generating a personalized model for a new client is efficient as no additional fine-tuning or optimization is required by either the client or the server. We also present theoretical results supporting PeFLL in the form of a new PAC-Bayesian generalization bound for lifelong learning and we prove the convergence of our proposed optimization procedure.
QuAFL: Federated Averaging Can Be Both Asynchronous and Communication-Efficient
Jun 22, 2022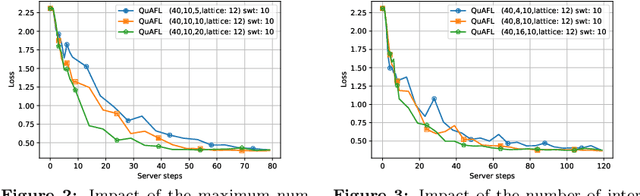
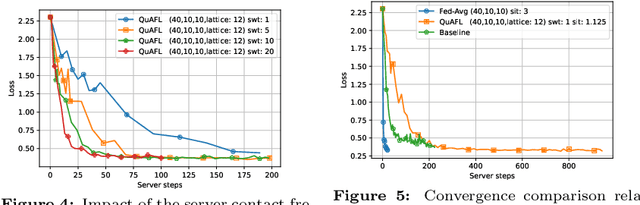
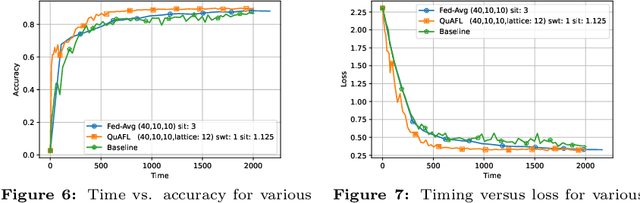
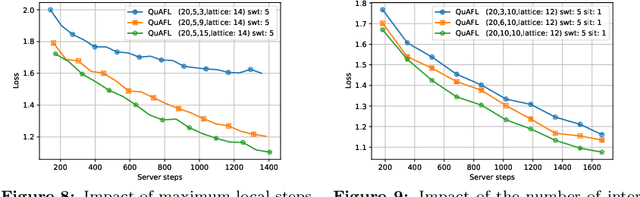
Federated Learning (FL) is an emerging paradigm to enable the large-scale distributed training of machine learning models, while still providing privacy guarantees. In this work, we jointly address two of the main practical challenges when scaling federated optimization to large node counts: the need for tight synchronization between the central authority and individual computing nodes, and the large communication cost of transmissions between the central server and clients. Specifically, we present a new variant of the classic federated averaging (FedAvg) algorithm, which supports both asynchronous communication and communication compression. We provide a new analysis technique showing that, in spite of these system relaxations, our algorithm essentially matches the best known bounds for FedAvg, under reasonable parameter settings. On the experimental side, we show that our algorithm ensures fast practical convergence for standard federated tasks.