 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAFL: Federated Averaging Can Be Both Asynchronous and Communication-Efficient
Paper and Code
Jun 22, 2022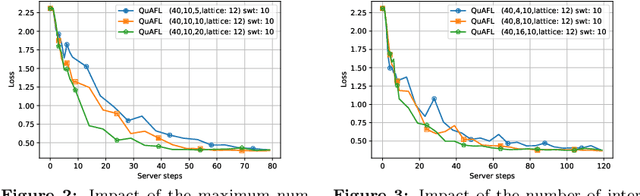
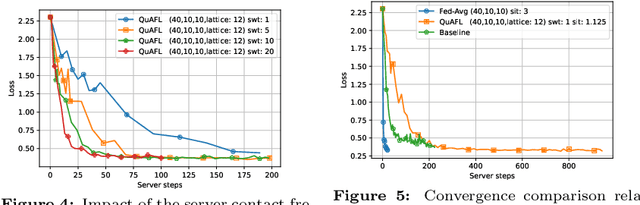
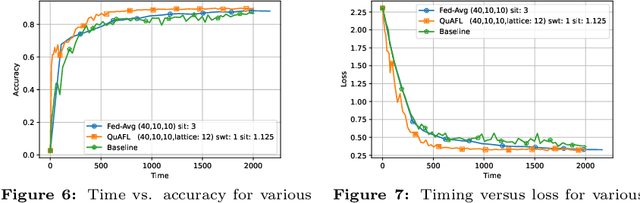
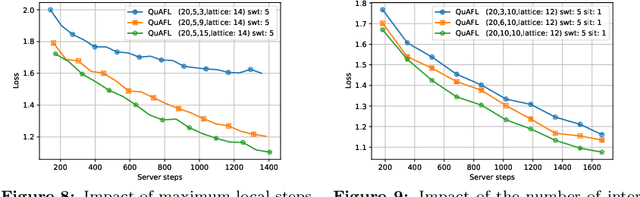
Federated Learning (FL) is an emerging paradigm to enable the large-scale distributed training of machine learning models, while still providing privacy guarantees. In this work, we jointly address two of the main practical challenges when scaling federated optimization to large node counts: the need for tight synchronization between the central authority and individual computing nodes, and the large communication cost of transmissions between the central server and clients. Specifically, we present a new variant of the classic federated averaging (FedAvg) algorithm, which supports both asynchronous communication and communication compression. We provide a new analysis technique showing that, in spite of these system relaxations, our algorithm essentially matches the best known bounds for FedAvg, under reasonable parameter settings. On the experimental side, we show that our algorithm ensures fast practical convergence for standard federated tasks.