 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining United Nations General Assembly Debates
Jun 19, 2024


This project explores the application of Natural Language Processing (NLP) techniques to analyse United Nations General Assembly (UNGA) speeches. Using NLP allows for the efficient processing and analysis of large volumes of textual data, enabling the extraction of semantic patterns, sentiment analysis, and topic modelling. Our goal is to deliver a comprehensive dataset and a tool (interface with descriptive statistics and automatically extracted topics) from which political scientists can derive insights into international relations and have the opportunity to have a nuanced understanding of global diplomatic discourse.
Interpretable Machine Learning for Survival Analysis
Mar 15, 2024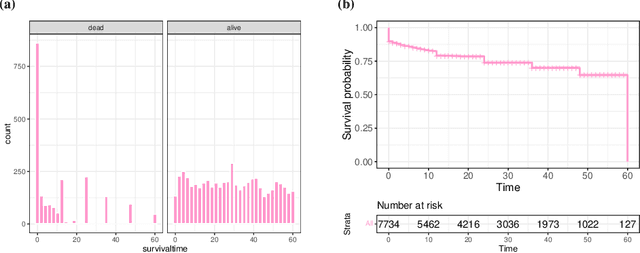
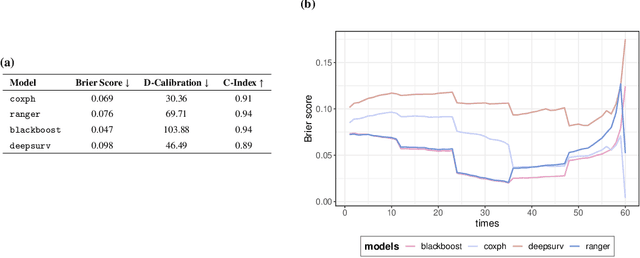
With the spread and rapid advancement of black box machine learning models, the field of interpretable machine learning (IML) or explainable artificial intelligence (XAI) has become increasingly important over the last decade. This is particularly relevant for survival analysis, where the adoption of IML techniques promotes transparency, accountability and fairness in sensitive areas, such as clinical decision making processes, the development of targeted therapies, interventions or in other medical or healthcare related contexts. More specifically, explainability can uncover a survival model's potential biases and limitations and provide more mathematically sound ways to understand how and which features are influential for prediction or constitute risk factors. However, the lack of readily available IML methods may have deterred medical practitioners and policy makers in public health from leveraging the full potential of machine learning for predicting time-to-event data. We present a comprehensive review of the limited existing amount of work on IML methods for survival analysis within the context of the general IML taxonomy. In addition, we formally detail how commonly used IML methods, such as such as individual conditional expectation (ICE), partial dependence plots (PDP), accumulated local effects (ALE), different feature importance measures or Friedman's H-interaction statistics can be adapted to survival outcomes. An application of several IML methods to real data on data on under-5 year mortality of Ghanaian children from the Demographic and Health Surveys (DHS) Program serves as a tutorial or guide for researchers, on how to utilize the techniques in practice to facilitate understanding of model decisions or predictions.
survex: an R package for explaining machine learning survival models
Aug 30, 2023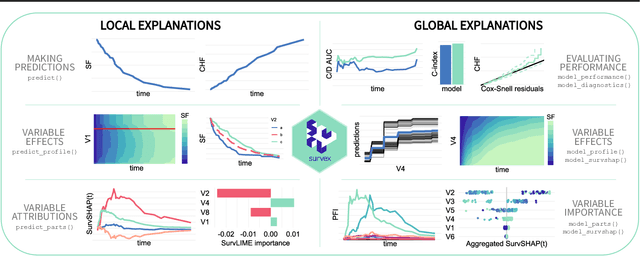
Due to their flexibility and superior performance, machine learning models frequently complement and outperform traditional statistical survival models. However, their widespread adoption is hindered by a lack of user-friendly tools to explain their internal operations and prediction rationales. To tackle this issue, we introduce the survex R package, which provides a cohesive framework for explaining any survival model by applying explainable artificial intelligence techniques. The capabilities of the proposed software encompass understanding and diagnosing survival models, which can lead to their improvement. By revealing insights into the decision-making process, such as variable effects and importances, survex enables the assessment of model reliability and the detection of biases. Thus, transparency and responsibility may be promoted in sensitive areas, such as biomedical research and healthcare applications.
Exploration of Rashomon Set Assists Explanations for Medical Data
Aug 22, 2023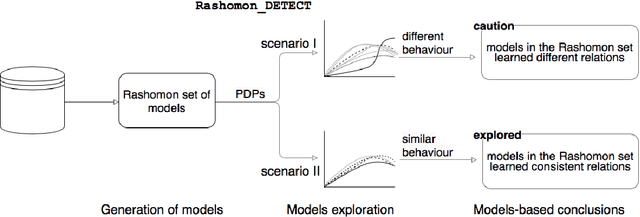
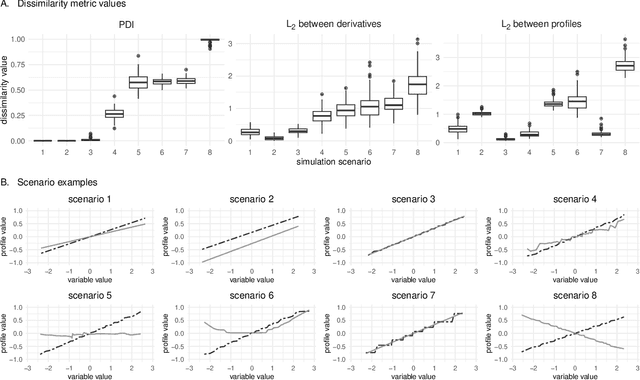
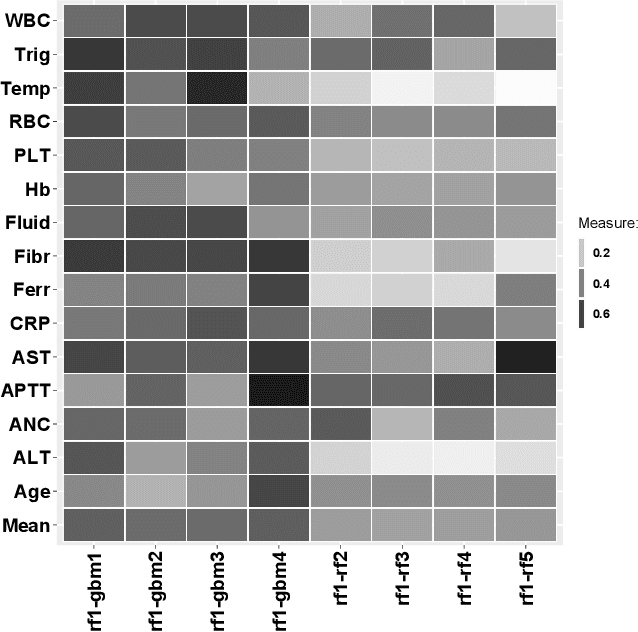
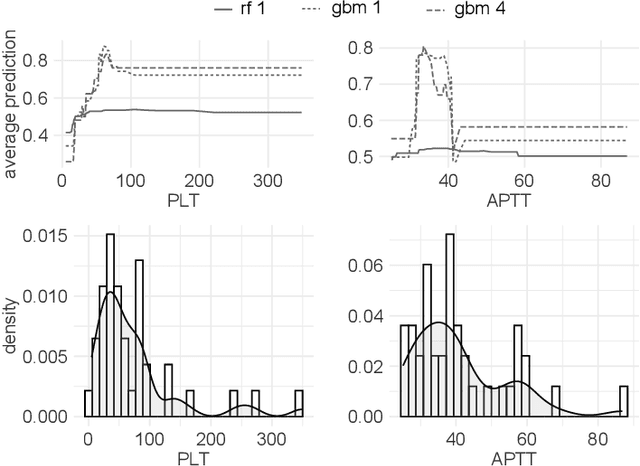
The machine learning modeling process conventionally culminates in selecting a single model that maximizes a selected performance metric. However, this approach leads to abandoning a more profound analysis of slightly inferior models. Particularly in medical and healthcare studies, where the objective extends beyond predictions to valuable insight generation, relying solely on performance metrics can result in misleading or incomplete conclusions. This problem is particularly pertinent when dealing with a set of models with performance close to maximum one, known as $\textit{Rashomon set}$. Such a set can be numerous and may contain models describing the data in a different way, which calls for comprehensive analysis. This paper introduces a novel process to explore Rashomon set models, extending the conventional modeling approach. The cornerstone is the identification of the most different models within the Rashomon set, facilitated by the introduced $\texttt{Rashomon_DETECT}$ algorithm. This algorithm compares profiles illustrating prediction dependencies on variable values generated by eXplainable Artificial Intelligence (XAI) techniques. To quantify differences in variable effects among models, we introduce the Profile Disparity Index (PDI) based on measures from functional data analysis. To illustrate the effectiveness of our approach, we showcase its application in predicting survival among hemophagocytic lymphohistiocytosis (HLH) patients - a foundational case study. Additionally, we benchmark our approach on other medical data sets, demonstrating its versatility and utility in various contexts.
HADES: Homologous Automated Document Exploration and Summarization
Feb 25, 2023



This paper introduces HADES, a novel tool for automatic comparative documents with similar structures. HADES is designed to streamline the work of professionals dealing with large volumes of documents, such as policy documents, legal acts, and scientific papers. The tool employs a multi-step pipeline that begins with processing PDF documents using topic modeling, summarization, and analysis of the most important words for each topic. The process concludes with an interactive web app with visualizations that facilitate the comparison of the documents. HADES has the potential to significantly improve the productivity of professionals dealing with high volumes of documents, reducing the time and effort required to complete tasks related to comparative document analysis. Our package is publically available on GitHub.
Climate Policy Tracker: Pipeline for automated analysis of public climate policies
Nov 10, 2022



The number of standardized policy documents regarding climate policy and their publication frequency is significantly increasing. The documents are long and tedious for manual analysis, especially for policy experts, lawmakers, and citizens who lack access or domain expertise to utilize data analytics tools. Potential consequences of such a situation include reduced citizen governance and involvement in climate policies and an overall surge in analytics costs, rendering less accessibility for the public. In this work, we use a Latent Dirichlet Allocation-based pipeline for the automatic summarization and analysis of 10-years of national energy and climate plans (NECPs) for the period from 2021 to 2030, established by 27 Member States of the European Union. We focus on analyzing policy framing, the language used to describe specific issues, to detect essential nuances in the way governments frame their climate policies and achieve climate goals. The methods leverage topic modeling and clustering for the comparative analysis of policy documents across different countries. It allows for easier integration in potential user-friendly applications for the development of theories and processes of climate policy. This would further lead to better citizen governance and engagement over climate policies and public policy research.
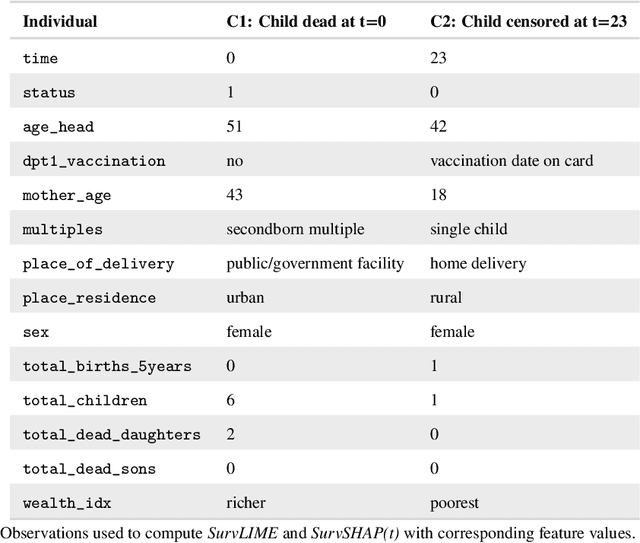
SurvSHAP(t): Time-dependent explanations of machine learning survival models
Aug 23, 2022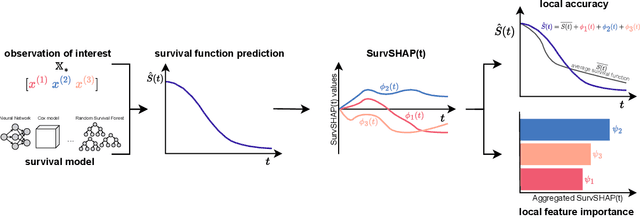
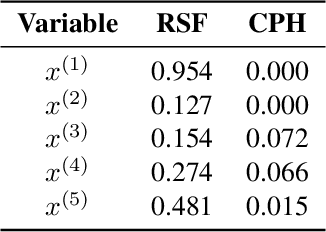
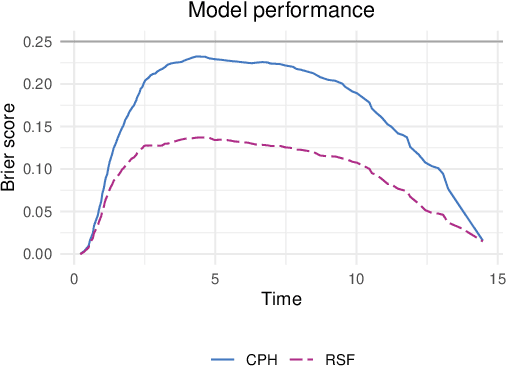

Machine and deep learning survival models demonstrate similar or even improved time-to-event prediction capabilities compared to classical statistical learning methods yet are too complex to be interpreted by humans. Several model-agnostic explanations are available to overcome this issue; however, none directly explain the survival function prediction. In this paper, we introduce SurvSHAP(t), the first time-dependent explanation that allows for interpreting survival black-box models. It is based on SHapley Additive exPlanations with solid theoretical foundations and a broad adoption among machine learning practitioners. The proposed methods aim to enhance precision diagnostics and support domain experts in making decisions. Experiments on synthetic and medical data confirm that SurvSHAP(t) can detect variables with a time-dependent effect, and its aggregation is a better determinant of the importance of variables for a prediction than SurvLIME. SurvSHAP(t) is model-agnostic and can be applied to all models with functional output. We provide an accessible implementation of time-dependent explanations in Python at http://github.com/MI2DataLab/survshap .