 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAN-PL: a Novel Polish Dataset of Banned Harmful and Offensive Content from Wykop.pl web service
Paper and Code

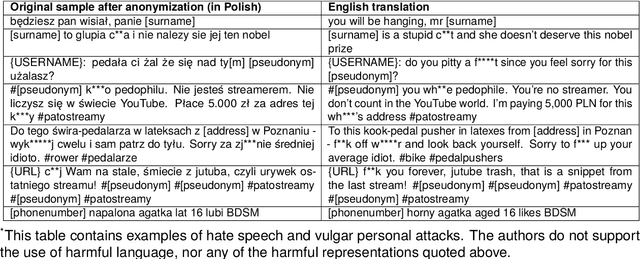


Advances in automated detection of offensive language online, including hate speech and cyberbullying, require improved access to publicly available datasets comprising social media content. In this paper, we introduce BAN-PL, the first open dataset in the Polish language that encompasses texts flagged as harmful and subsequently removed by professional moderators. The dataset encompasses a total of 691,662 pieces of content from a popular social networking service, Wykop, often referred to as the "Polish Reddit", including both posts and comments, and is evenly distributed into two distinct classes: "harmful" and "neutral". We provide a comprehensive description of the data collection and preprocessing procedures, as well as highlight the linguistic specificity of the data. The BAN-PL dataset, along with advanced preprocessing scripts for, i.a., unmasking profanities, will be publicly available.