 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLuM: A Family of Polish Large Language Models
Nov 05, 2025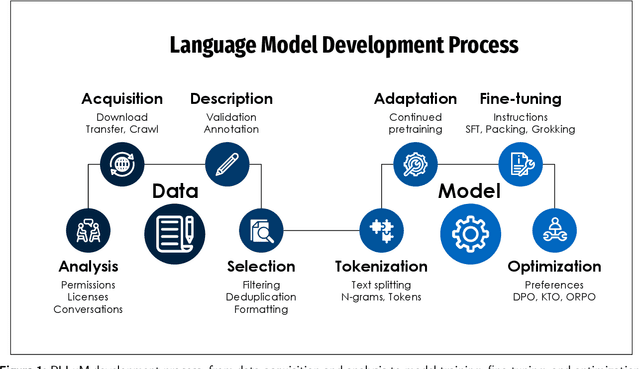
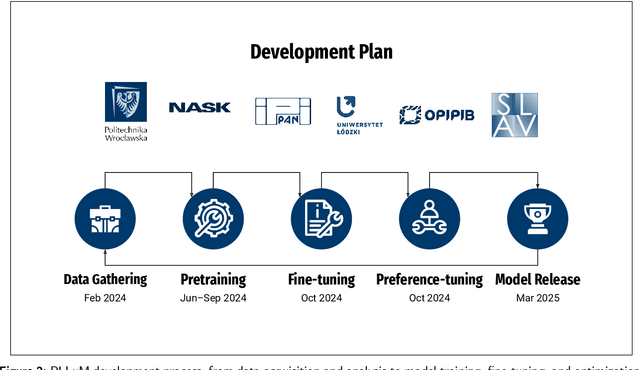

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Behind Closed Words: Creating and Investigating the forePLay Annotated Dataset for Polish Erotic Discourse
Dec 23, 2024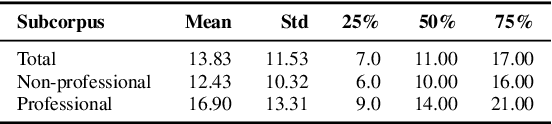
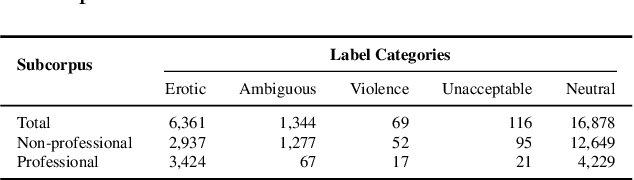

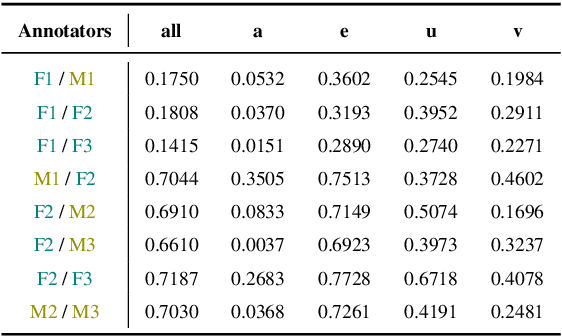
The surge in online content has created an urgent demand for robust detection systems, especially in non-English contexts where current tools demonstrate significant limitations. We present forePLay, a novel Polish language dataset for erotic content detection, featuring over 24k annotated sentences with a multidimensional taxonomy encompassing ambiguity, violence, and social unacceptability dimensions. Our comprehensive evaluation demonstrates that specialized Polish language models achieve superior performance compared to multilingual alternatives, with transformer-based architectures showing particular strength in handling imbalanced categories. The dataset and accompanying analysis establish essential frameworks for developing linguistically-aware content moderation systems, while highlighting critical considerations for extending such capabilities to morphologically complex languages.
StyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors
Sep 22, 2023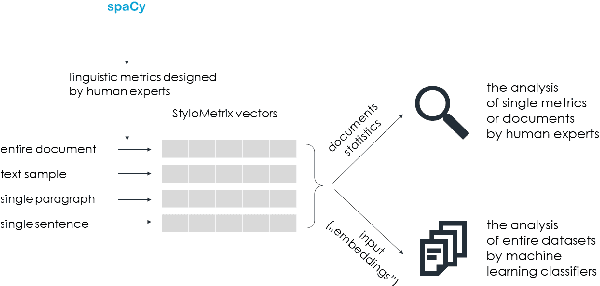
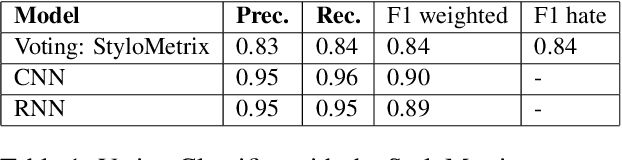
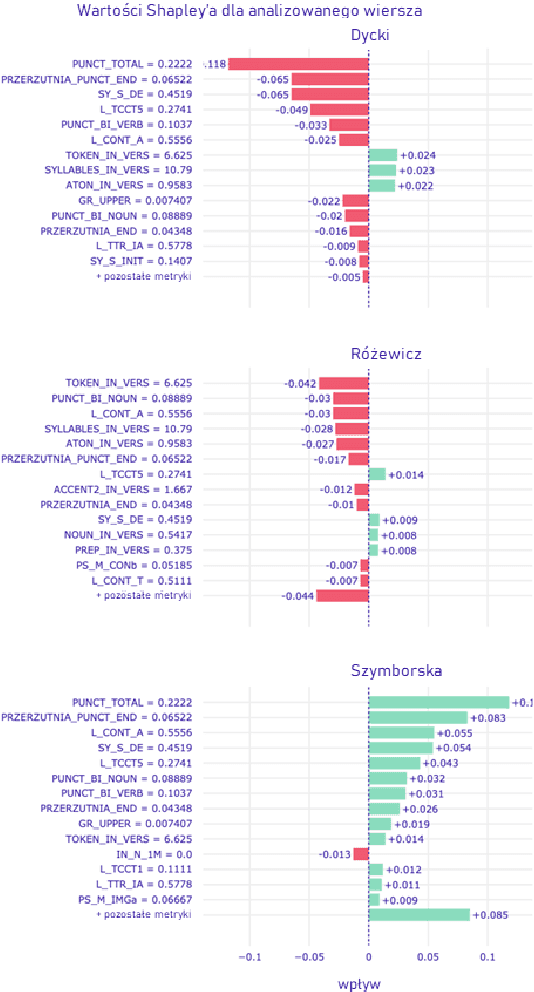
This work aims to provide an overview on the open-source multilanguage tool called StyloMetrix. It offers stylometric text representations that cover various aspects of grammar, syntax and lexicon. StyloMetrix covers four languages: Polish as the primary language, English, Ukrainian and Russian. The normalized output of each feature can become a fruitful course for machine learning models and a valuable addition to the embeddings layer for any deep learning algorithm. We strive to provide a concise, but exhaustive overview on the application of the StyloMetrix vectors as well as explain the sets of the developed linguistic features. The experiments have shown promising results in supervised content classification with simple algorithms as Random Forest Classifier, Voting Classifier, Logistic Regression and others. The deep learning assessments have unveiled the usefulness of the StyloMetrix vectors at enhancing an embedding layer extracted from Transformer architectures. The StyloMetrix has proven itself to be a formidable source for the machine learning and deep learning algorithms to execute different classification tasks.
BAN-PL: a Novel Polish Dataset of Banned Harmful and Offensive Content from Wykop.pl web service
Aug 23, 2023Advances in automated detection of offensive language online, including hate speech and cyberbullying, require improved access to publicly available datasets comprising social media content. In this paper, we introduce BAN-PL, the first open dataset in the Polish language that encompasses texts flagged as harmful and subsequently removed by professional moderators. The dataset encompasses a total of 691,662 pieces of content from a popular social networking service, Wykop, often referred to as the "Polish Reddit", including both posts and comments, and is evenly distributed into two distinct classes: "harmful" and "neutral". We provide a comprehensive description of the data collection and preprocessing procedures, as well as highlight the linguistic specificity of the data. The BAN-PL dataset, along with advanced preprocessing scripts for, i.a., unmasking profanities, will be publicly available.