 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocietal AI Research Has Become Less Interdisciplinary
Jun 11, 2025As artificial intelligence (AI) systems become deeply embedded in everyday life, calls to align AI development with ethical and societal values have intensified. Interdisciplinary collaboration is often championed as a key pathway for fostering such engagement. Yet it remains unclear whether interdisciplinary research teams are actually leading this shift in practice. This study analyzes over 100,000 AI-related papers published on ArXiv between 2014 and 2024 to examine how ethical values and societal concerns are integrated into technical AI research. We develop a classifier to identify societal content and measure the extent to which research papers express these considerations. We find a striking shift: while interdisciplinary teams remain more likely to produce societally-oriented research, computer science-only teams now account for a growing share of the field's overall societal output. These teams are increasingly integrating societal concerns into their papers and tackling a wide range of domains - from fairness and safety to healthcare and misinformation. These findings challenge common assumptions about the drivers of societal AI and raise important questions. First, what are the implications for emerging understandings of AI safety and governance if most societally-oriented research is being undertaken by exclusively technical teams? Second, for scholars in the social sciences and humanities: in a technical field increasingly responsive to societal demands, what distinctive perspectives can we still offer to help shape the future of AI?
StyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors
Sep 22, 2023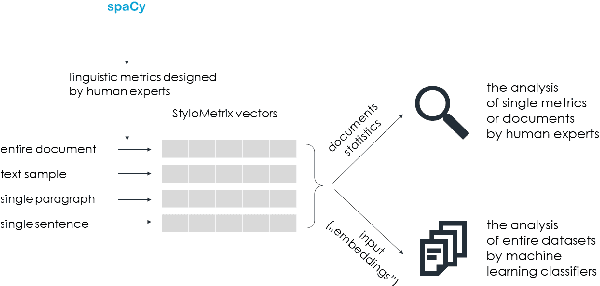
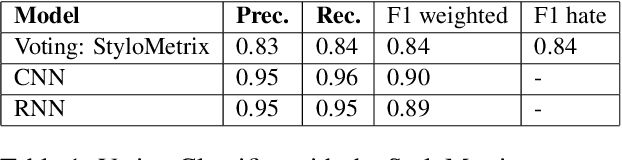
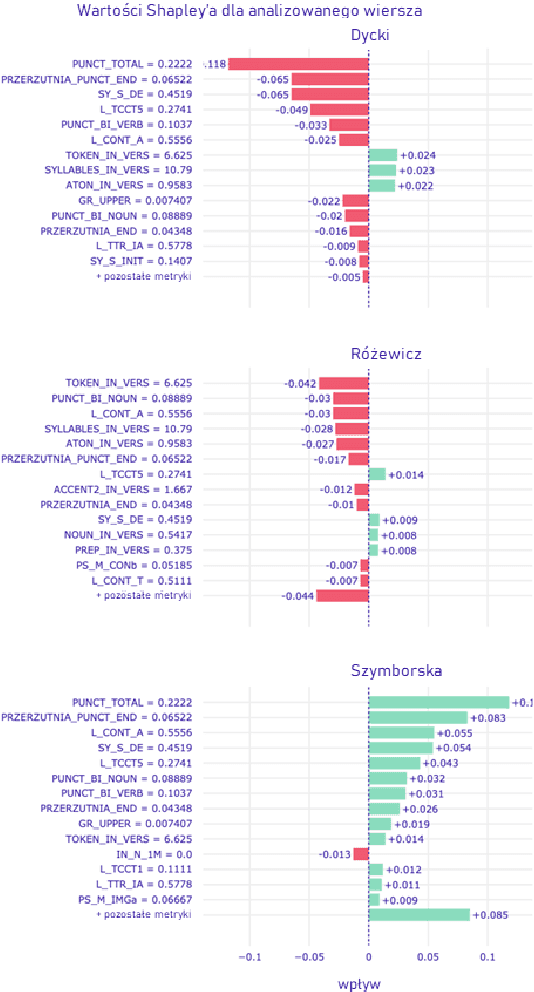
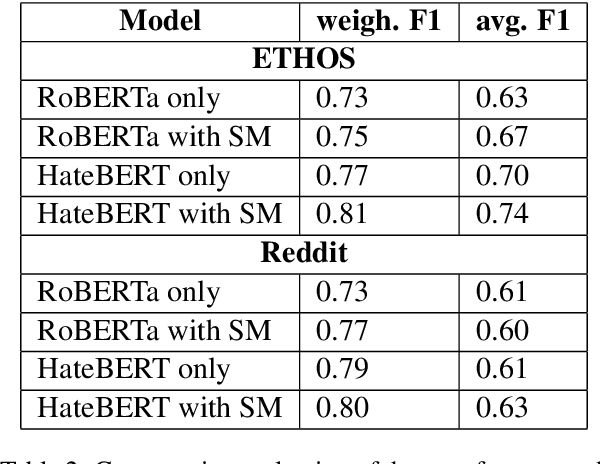
This work aims to provide an overview on the open-source multilanguage tool called StyloMetrix. It offers stylometric text representations that cover various aspects of grammar, syntax and lexicon. StyloMetrix covers four languages: Polish as the primary language, English, Ukrainian and Russian. The normalized output of each feature can become a fruitful course for machine learning models and a valuable addition to the embeddings layer for any deep learning algorithm. We strive to provide a concise, but exhaustive overview on the application of the StyloMetrix vectors as well as explain the sets of the developed linguistic features. The experiments have shown promising results in supervised content classification with simple algorithms as Random Forest Classifier, Voting Classifier, Logistic Regression and others. The deep learning assessments have unveiled the usefulness of the StyloMetrix vectors at enhancing an embedding layer extracted from Transformer architectures. The StyloMetrix has proven itself to be a formidable source for the machine learning and deep learning algorithms to execute different classification tasks.
The Grammar and Syntax Based Corpus Analysis Tool For The Ukrainian Language
May 22, 2023



This paper provides an overview of a text mining tool the StyloMetrix developed initially for the Polish language and further extended for English and recently for Ukrainian. The StyloMetrix is built upon various metrics crafted manually by computational linguists and researchers from literary studies to analyze grammatical, stylistic, and syntactic patterns. The idea of constructing the statistical evaluation of syntactic and grammar features is straightforward and familiar for the languages like English, Spanish, German, and others; it is yet to be developed for low-resource languages like Ukrainian. We describe the StyloMetrix pipeline and provide some experiments with this tool for the text classification task. We also describe our package's main limitations and the metrics' evaluation procedure.