 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors
Paper and Code
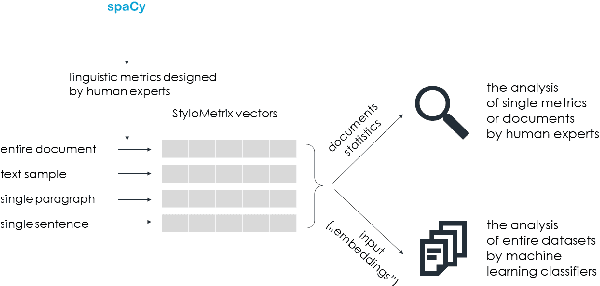
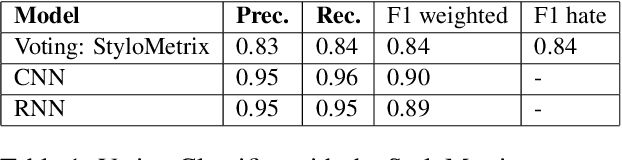
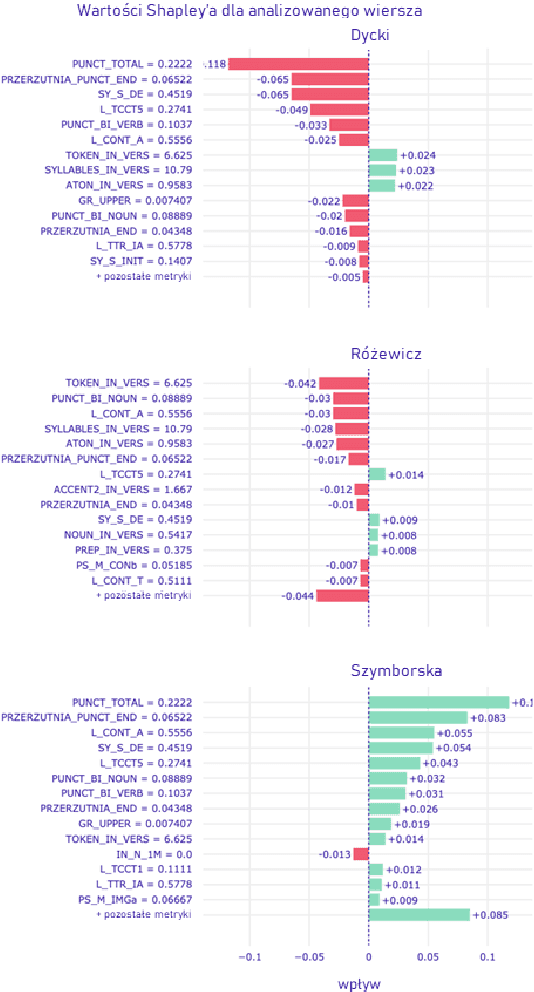
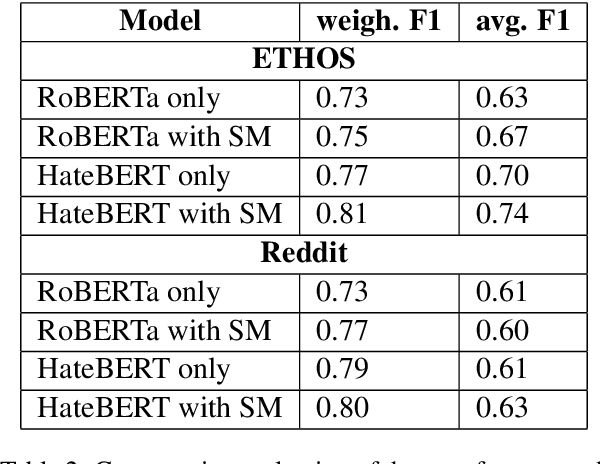
This work aims to provide an overview on the open-source multilanguage tool called StyloMetrix. It offers stylometric text representations that cover various aspects of grammar, syntax and lexicon. StyloMetrix covers four languages: Polish as the primary language, English, Ukrainian and Russian. The normalized output of each feature can become a fruitful course for machine learning models and a valuable addition to the embeddings layer for any deep learning algorithm. We strive to provide a concise, but exhaustive overview on the application of the StyloMetrix vectors as well as explain the sets of the developed linguistic features. The experiments have shown promising results in supervised content classification with simple algorithms as Random Forest Classifier, Voting Classifier, Logistic Regression and others. The deep learning assessments have unveiled the usefulness of the StyloMetrix vectors at enhancing an embedding layer extracted from Transformer architectures. The StyloMetrix has proven itself to be a formidable source for the machine learning and deep learning algorithms to execute different classification tasks.