 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Harmful Erotic Content Detection through Coreference-Driven Contextual Analysis
Oct 22, 2023


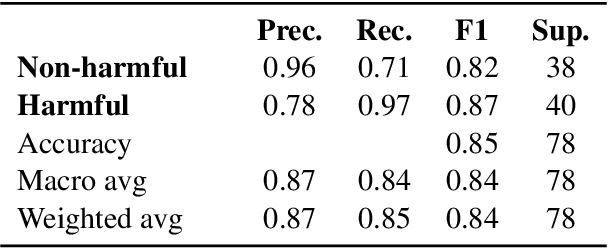
Adult content detection still poses a great challenge for automation. Existing classifiers primarily focus on distinguishing between erotic and non-erotic texts. However, they often need more nuance in assessing the potential harm. Unfortunately, the content of this nature falls beyond the reach of generative models due to its potentially harmful nature. Ethical restrictions prohibit large language models (LLMs) from analyzing and classifying harmful erotics, let alone generating them to create synthetic datasets for other neural models. In such instances where data is scarce and challenging, a thorough analysis of the structure of such texts rather than a large model may offer a viable solution. Especially given that harmful erotic narratives, despite appearing similar to harmless ones, usually reveal their harmful nature first through contextual information hidden in the non-sexual parts of the narrative. This paper introduces a hybrid neural and rule-based context-aware system that leverages coreference resolution to identify harmful contextual cues in erotic content. Collaborating with professional moderators, we compiled a dataset and developed a classifier capable of distinguishing harmful from non-harmful erotic content. Our hybrid model, tested on Polish text, demonstrates a promising accuracy of 84% and a recall of 80%. Models based on RoBERTa and Longformer without explicit usage of coreference chains achieved significantly weaker results, underscoring the importance of coreference resolution in detecting such nuanced content as harmful erotics. This approach also offers the potential for enhanced visual explainability, supporting moderators in evaluating predictions and taking necessary actions to address harmful content.
StyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors
Sep 22, 2023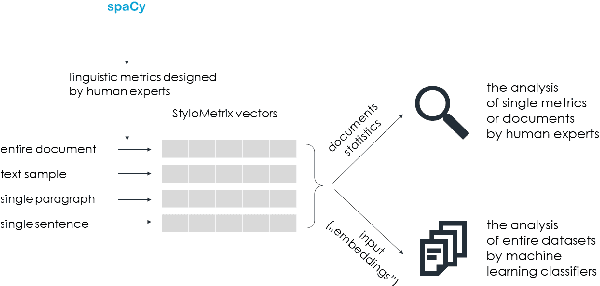
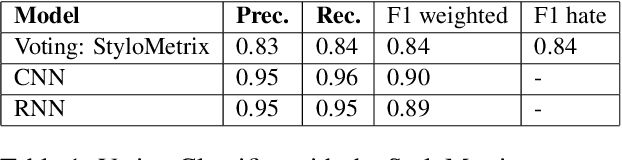
This work aims to provide an overview on the open-source multilanguage tool called StyloMetrix. It offers stylometric text representations that cover various aspects of grammar, syntax and lexicon. StyloMetrix covers four languages: Polish as the primary language, English, Ukrainian and Russian. The normalized output of each feature can become a fruitful course for machine learning models and a valuable addition to the embeddings layer for any deep learning algorithm. We strive to provide a concise, but exhaustive overview on the application of the StyloMetrix vectors as well as explain the sets of the developed linguistic features. The experiments have shown promising results in supervised content classification with simple algorithms as Random Forest Classifier, Voting Classifier, Logistic Regression and others. The deep learning assessments have unveiled the usefulness of the StyloMetrix vectors at enhancing an embedding layer extracted from Transformer architectures. The StyloMetrix has proven itself to be a formidable source for the machine learning and deep learning algorithms to execute different classification tasks.
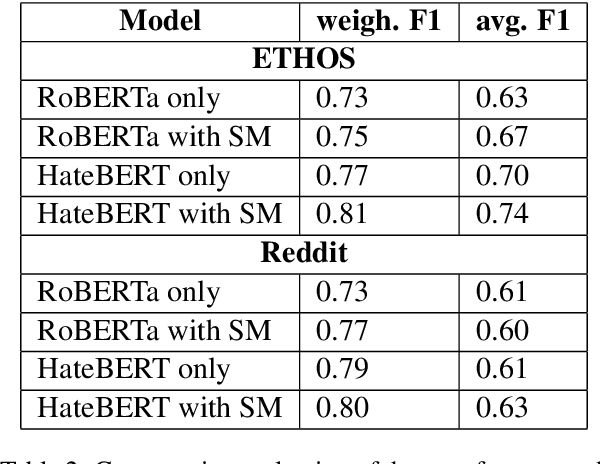
BAN-PL: a Novel Polish Dataset of Banned Harmful and Offensive Content from Wykop.pl web service
Aug 23, 2023


Advances in automated detection of offensive language online, including hate speech and cyberbullying, require improved access to publicly available datasets comprising social media content. In this paper, we introduce BAN-PL, the first open dataset in the Polish language that encompasses texts flagged as harmful and subsequently removed by professional moderators. The dataset encompasses a total of 691,662 pieces of content from a popular social networking service, Wykop, often referred to as the "Polish Reddit", including both posts and comments, and is evenly distributed into two distinct classes: "harmful" and "neutral". We provide a comprehensive description of the data collection and preprocessing procedures, as well as highlight the linguistic specificity of the data. The BAN-PL dataset, along with advanced preprocessing scripts for, i.a., unmasking profanities, will be publicly available.
The Grammar and Syntax Based Corpus Analysis Tool For The Ukrainian Language
May 22, 2023



This paper provides an overview of a text mining tool the StyloMetrix developed initially for the Polish language and further extended for English and recently for Ukrainian. The StyloMetrix is built upon various metrics crafted manually by computational linguists and researchers from literary studies to analyze grammatical, stylistic, and syntactic patterns. The idea of constructing the statistical evaluation of syntactic and grammar features is straightforward and familiar for the languages like English, Spanish, German, and others; it is yet to be developed for low-resource languages like Ukrainian. We describe the StyloMetrix pipeline and provide some experiments with this tool for the text classification task. We also describe our package's main limitations and the metrics' evaluation procedure.