 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThere and Back Again: On the relation between noises, images, and their inversions in diffusion models
Oct 31, 2024Denoising Diffusion Probabilistic Models (DDPMs) achieve state-of-the-art performance in synthesizing new images from random noise, but they lack meaningful latent space that encodes data into features. Recent DDPM-based editing techniques try to mitigate this issue by inverting images back to their approximated staring noise. In this work, we study the relation between the initial Gaussian noise, the samples generated from it, and their corresponding latent encodings obtained through the inversion procedure. First, we interpret their spatial distance relations to show the inaccuracy of the DDIM inversion technique by localizing latent representations manifold between the initial noise and generated samples. Then, we demonstrate the peculiar relation between initial Gaussian noise and its corresponding generations during diffusion training, showing that the high-level features of generated images stabilize rapidly, keeping the spatial distance relationship between noises and generations consistent throughout the training.
Low-Rank Continual Personalization of Diffusion Models
Oct 07, 2024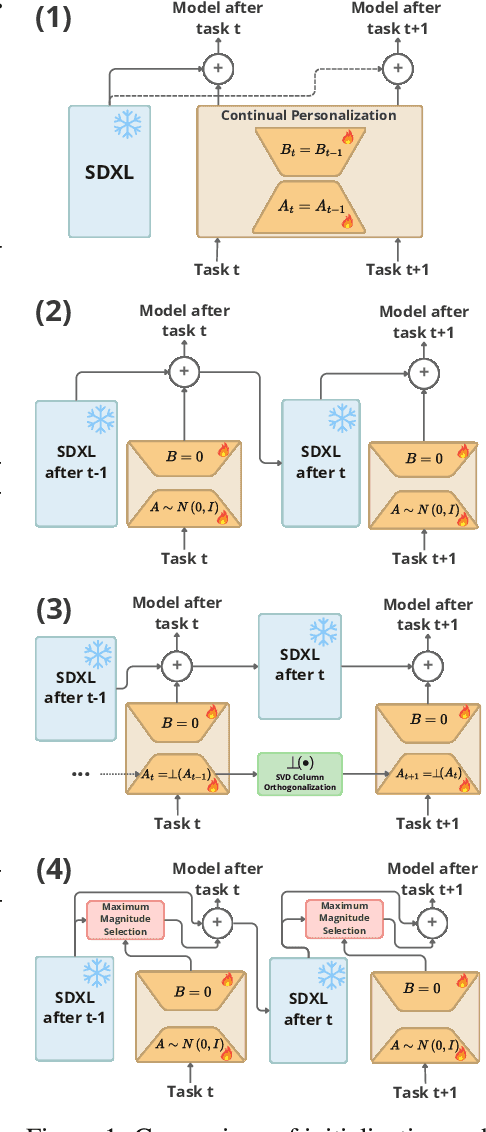
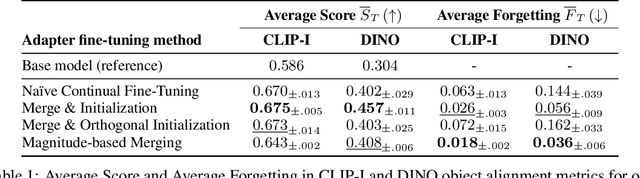
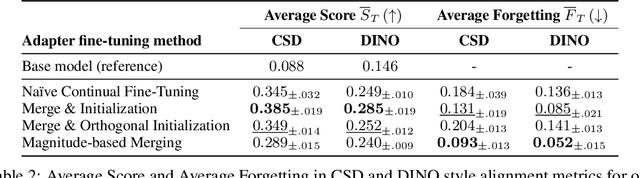
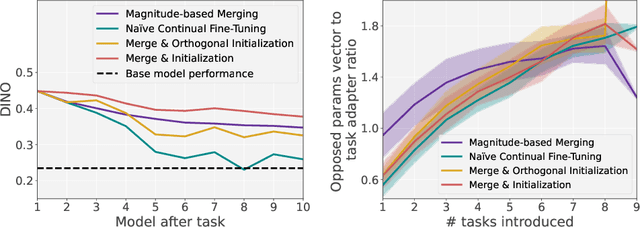
Recent personalization methods for diffusion models, such as Dreambooth, allow fine-tuning pre-trained models to generate new concepts. However, applying these techniques across multiple tasks in order to include, e.g., several new objects or styles, leads to mutual interference between their adapters. While recent studies attempt to mitigate this issue by combining trained adapters across tasks after fine-tuning, we adopt a more rigorous regime and investigate the personalization of large diffusion models under a continual learning scenario, where such interference leads to catastrophic forgetting of previous knowledge. To that end, we evaluate the na\"ive continual fine-tuning of customized models and compare this approach with three methods for consecutive adapters' training: sequentially merging new adapters, merging orthogonally initialized adapters, and updating only relevant parameters according to the task. In our experiments, we show that the proposed approaches mitigate forgetting when compared to the na\"ive approach.