 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipper: A Multi-Tower Decoder Architecture for Fusing Modalities
Paper and Code
May 29, 2024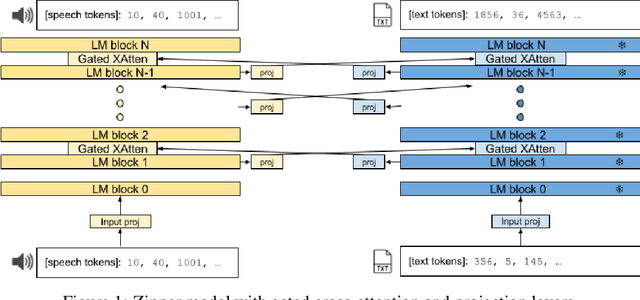


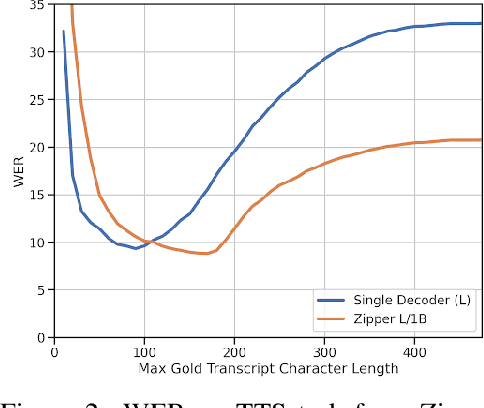
Integrating multiple generative foundation models, especially those trained on different modalities, into something greater than the sum of its parts poses significant challenges. Two key hurdles are the availability of aligned data (concepts that contain similar meaning but is expressed differently in different modalities), and effectively leveraging unimodal representations in cross-domain generative tasks, without compromising their original unimodal capabilities. We propose Zipper, a multi-tower decoder architecture that addresses these concerns by using cross-attention to flexibly compose multimodal generative models from independently pre-trained unimodal decoders. In our experiments fusing speech and text modalities, we show the proposed architecture performs very competitively in scenarios with limited aligned text-speech data. We also showcase the flexibility of our model to selectively maintain unimodal (e.g., text-to-text generation) generation performance by freezing the corresponding modal tower (e.g. text). In cross-modal tasks such as automatic speech recognition (ASR) where the output modality is text, we show that freezing the text backbone results in negligible performance degradation. In cross-modal tasks such as text-to-speech generation (TTS) where the output modality is speech, we show that using a pre-trained speech backbone results in superior performance to the baseline.