 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMHQA-ICL: Multimodal In-context Learning for Hybrid Question Answering over Text, Tables and Images
Paper and Code
Sep 09, 2023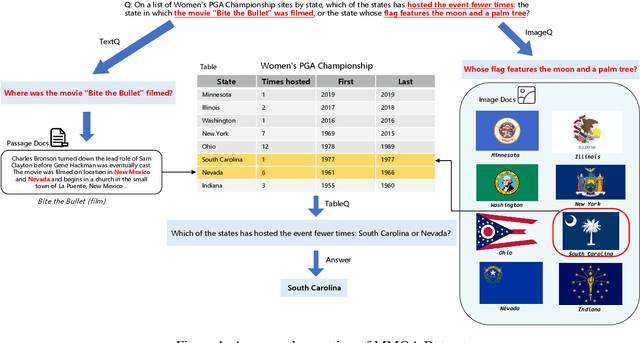
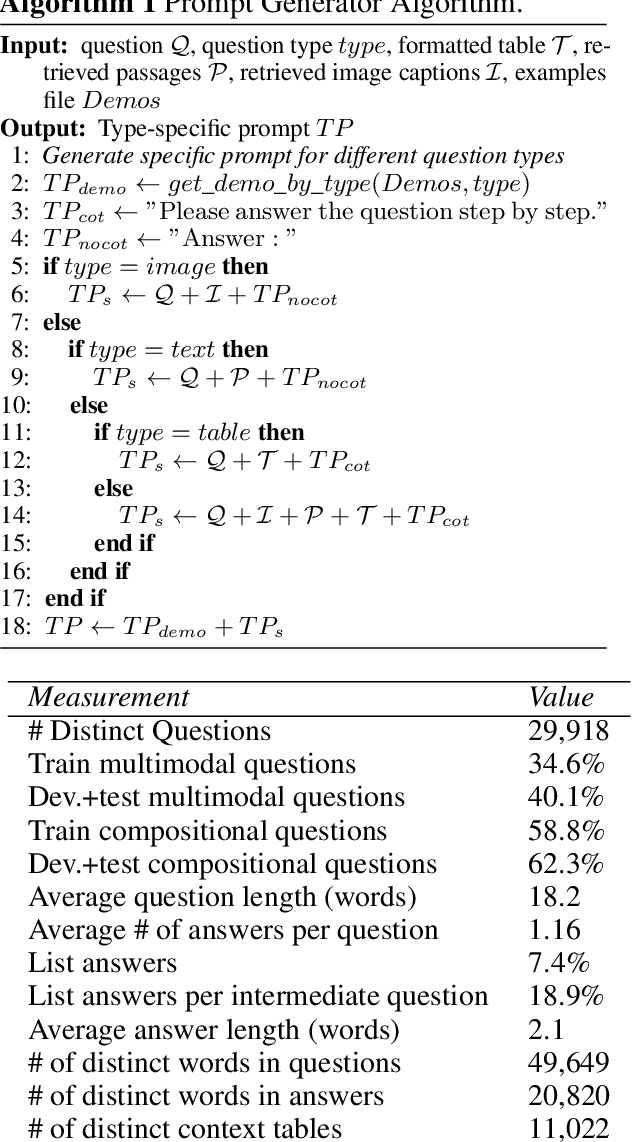
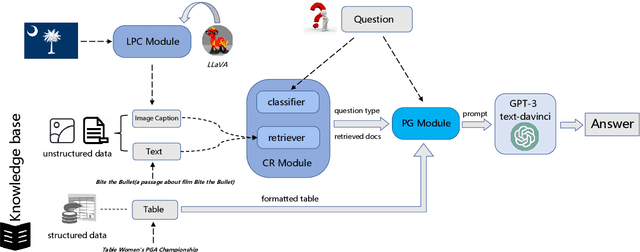

In the real world, knowledge often exists in a multimodal and heterogeneous form. Addressing the task of question answering with hybrid data types, including text, tables, and images, is a challenging task (MMHQA). Recently, with the rise of large language models (LLM), in-context learning (ICL) has become the most popular way to solve QA problems. We propose MMHQA-ICL framework for addressing this problems, which includes stronger heterogeneous data retriever and an image caption module. Most importantly, we propose a Type-specific In-context Learning Strategy for MMHQA, enabling LLMs to leverage their powerful performance in this task. We are the first to use end-to-end LLM prompting method for this task. Experimental results demonstrate that our framework outperforms all baselines and methods trained on the full dataset, achieving state-of-the-art results under the few-shot setting on the MultimodalQA dataset.