 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Video Frame Interpolation with integrated Difficulty Pre-Assessment
Apr 25, 2023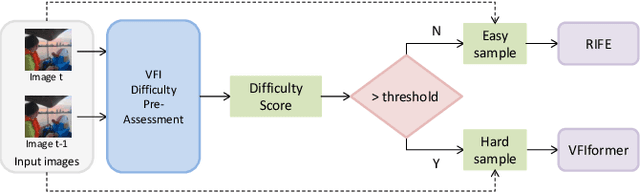
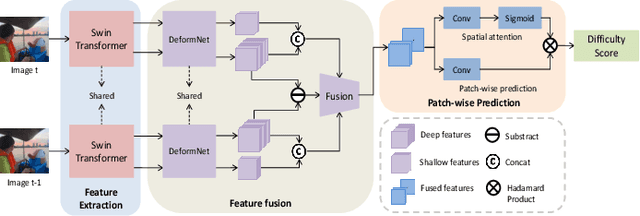
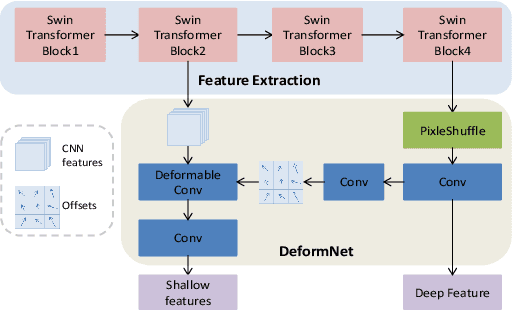
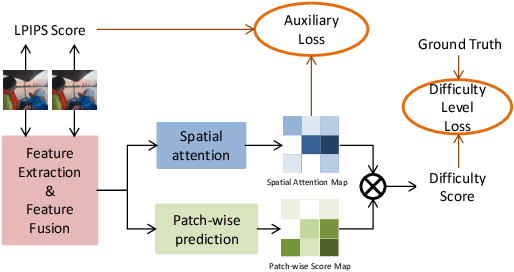
Video frame interpolation(VFI) has witnessed great progress in recent years. While existing VFI models still struggle to achieve a good trade-off between accuracy and efficiency: fast models often have inferior accuracy; accurate models typically run slowly. However, easy samples with small motion or clear texture can achieve competitive results with simple models and do not require heavy computation. In this paper, we present an integrated pipeline which combines difficulty assessment with video frame interpolation. Specifically, it firstly leverages a pre-assessment model to measure the interpolation difficulty level of input frames, and then dynamically selects an appropriate VFI model to generate interpolation results. Furthermore, a large-scale VFI difficulty assessment dataset is collected and annotated to train our pre-assessment model. Extensive experiments show that easy samples pass through fast models while difficult samples inference with heavy models, and our proposed pipeline can improve the accuracy-efficiency trade-off for VFI.
A Unified Pyramid Recurrent Network for Video Frame Interpolation
Nov 07, 2022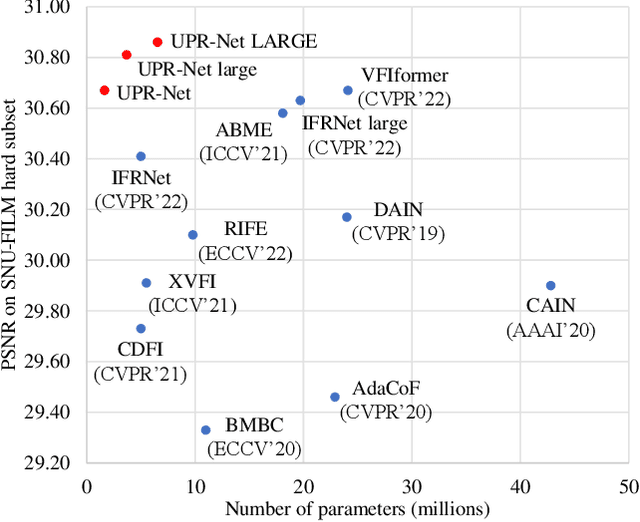
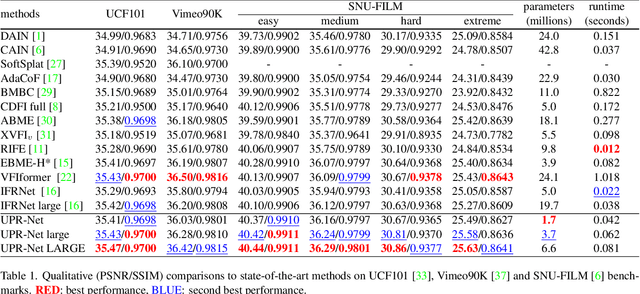
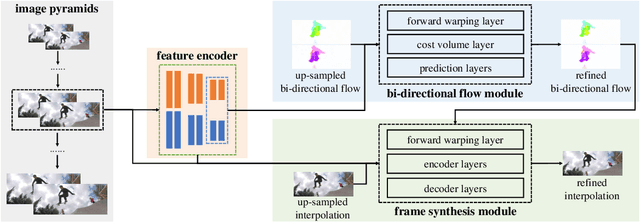
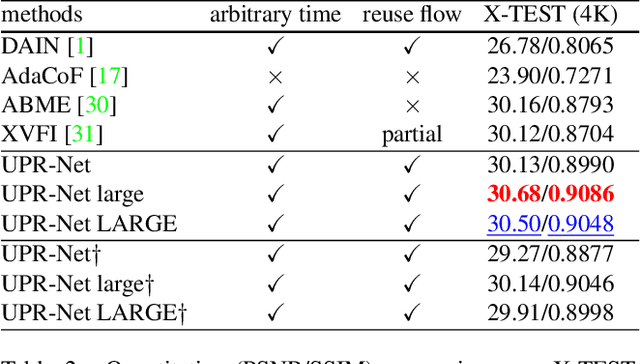
Flow-guide synthesis provides a common framework for frame interpolation, where optical flow is typically estimated by a pyramid network, and then leveraged to guide a synthesis network to generate intermediate frames between input frames. In this paper, we present UPR-Net, a novel Unified Pyramid Recurrent Network for frame interpolation. Cast in a flexible pyramid framework, UPR-Net exploits lightweight recurrent modules for both bi-directional flow estimation and intermediate frame synthesis. At each pyramid level, it leverages estimated bi-directional flow to generate forward-warped representations for frame synthesis; across pyramid levels, it enables iterative refinement for both optical flow and intermediate frame. In particular, we show that our iterative synthesis can significantly improve the robustness of frame interpolation on large motion cases. Despite being extremely lightweight (1.7M parameters), UPR-Net achieves excellent performance on a large range of benchmarks. Code will be available soon.
Pixel-by-pixel Mean Opinion Score for No-Reference Image Quality Assessment
Jun 14, 2022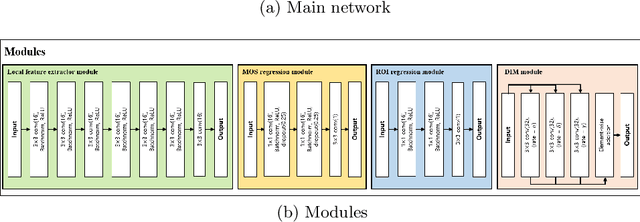
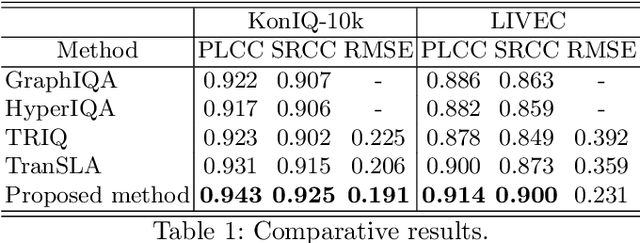
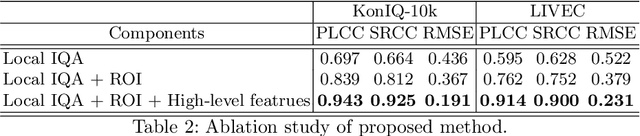
Deep-learning based techniques have contributed to the remarkable progress in the field of automatic image quality assessment (IQA). Existing IQA methods are designed to measure the quality of an image in terms of Mean Opinion Score (MOS) at the image-level (i.e. the whole image) or at the patch-level (dividing the image into multiple units and measuring quality of each patch). Some applications may require assessing the quality at the pixel-level (i.e. MOS value for each pixel), however, this is not possible in case of existing techniques as the spatial information is lost owing to their network structures. This paper proposes an IQA algorithm that can measure the MOS at the pixel-level, in addition to the image-level MOS. The proposed algorithm consists of three core parts, namely: i) Local IQA; ii) Region of Interest (ROI) prediction; iii) High-level feature embedding. The Local IQA part outputs the MOS at the pixel-level, or pixel-by-pixel MOS - we term it 'pMOS'. The ROI prediction part outputs weights that characterize the relative importance of region when calculating the image-level IQA. The high-level feature embedding part extracts high-level image features which are then embedded into the Local IQA part. In other words, the proposed algorithm yields three outputs: the pMOS which represents MOS for each pixel, the weights from the ROI indicating the relative importance of region, and finally the image-level MOS that is obtained by the weighted sum of pMOS and ROI values. The image-level MOS thus obtained by utilizing pMOS and ROI weights shows superior performance compared to the existing popular IQA techniques. In addition, visualization results indicate that predicted pMOS and ROI outputs are reasonably aligned with the general principles of the human visual system (HVS).