 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Simple Siamese Network for High-Resolution Video Quality Assessment
Mar 04, 2025In the research of video quality assessment (VQA), two-branch network has emerged as a promising solution. It decouples VQA with separate technical and aesthetic branches to measure the perception of low-level distortions and high-level semantics respectively. However, we argue that while technical and aesthetic perspectives are complementary, the technical perspective itself should be measured in semantic-aware manner. We hypothesize that existing technical branch struggles to perceive the semantics of high-resolution videos, as it is trained on local mini-patches sampled from videos. This issue can be hidden by apparently good results on low-resolution videos, but indeed becomes critical for high-resolution VQA. This work introduces SiamVQA, a simple but effective Siamese network for highre-solution VQA. SiamVQA shares weights between technical and aesthetic branches, enhancing the semantic perception ability of technical branch to facilitate technical-quality representation learning. Furthermore, it integrates a dual cross-attention layer for fusing technical and aesthetic features. SiamVQA achieves state-of-the-art accuracy on high-resolution benchmarks, and competitive results on lower-resolution benchmarks. Codes will be available at: https://github.com/srcn-ivl/SiamVQA
Unified Arbitrary-Time Video Frame Interpolation and Prediction
Mar 04, 2025Video frame interpolation and prediction aim to synthesize frames in-between and subsequent to existing frames, respectively. Despite being closely-related, these two tasks are traditionally studied with different model architectures, or same architecture but individually trained weights. Furthermore, while arbitrary-time interpolation has been extensively studied, the value of arbitrary-time prediction has been largely overlooked. In this work, we present uniVIP - unified arbitrary-time Video Interpolation and Prediction. Technically, we firstly extend an interpolation-only network for arbitrary-time interpolation and prediction, with a special input channel for task (interpolation or prediction) encoding. Then, we show how to train a unified model on common triplet frames. Our uniVIP provides competitive results for video interpolation, and outperforms existing state-of-the-arts for video prediction. Codes will be available at: https://github.com/srcn-ivl/uniVIP
Pixel-by-pixel Mean Opinion Score for No-Reference Image Quality Assessment
Jun 14, 2022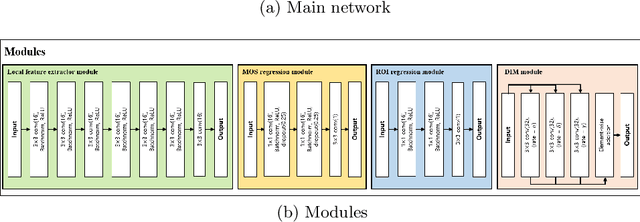
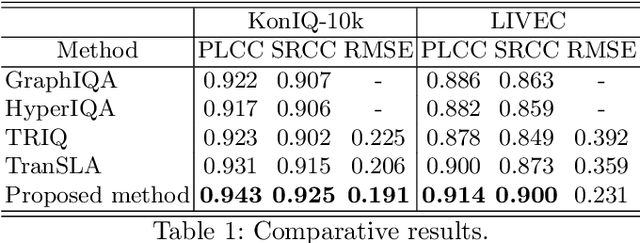
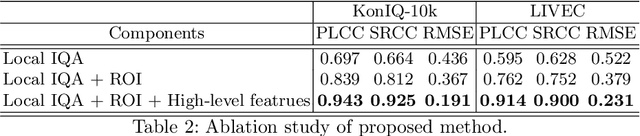
Deep-learning based techniques have contributed to the remarkable progress in the field of automatic image quality assessment (IQA). Existing IQA methods are designed to measure the quality of an image in terms of Mean Opinion Score (MOS) at the image-level (i.e. the whole image) or at the patch-level (dividing the image into multiple units and measuring quality of each patch). Some applications may require assessing the quality at the pixel-level (i.e. MOS value for each pixel), however, this is not possible in case of existing techniques as the spatial information is lost owing to their network structures. This paper proposes an IQA algorithm that can measure the MOS at the pixel-level, in addition to the image-level MOS. The proposed algorithm consists of three core parts, namely: i) Local IQA; ii) Region of Interest (ROI) prediction; iii) High-level feature embedding. The Local IQA part outputs the MOS at the pixel-level, or pixel-by-pixel MOS - we term it 'pMOS'. The ROI prediction part outputs weights that characterize the relative importance of region when calculating the image-level IQA. The high-level feature embedding part extracts high-level image features which are then embedded into the Local IQA part. In other words, the proposed algorithm yields three outputs: the pMOS which represents MOS for each pixel, the weights from the ROI indicating the relative importance of region, and finally the image-level MOS that is obtained by the weighted sum of pMOS and ROI values. The image-level MOS thus obtained by utilizing pMOS and ROI weights shows superior performance compared to the existing popular IQA techniques. In addition, visualization results indicate that predicted pMOS and ROI outputs are reasonably aligned with the general principles of the human visual system (HVS).