 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCore: Simple Fingerprint Construction for Differentiating Homologous and Piracy Models
Paper and Code
Nov 01, 2024
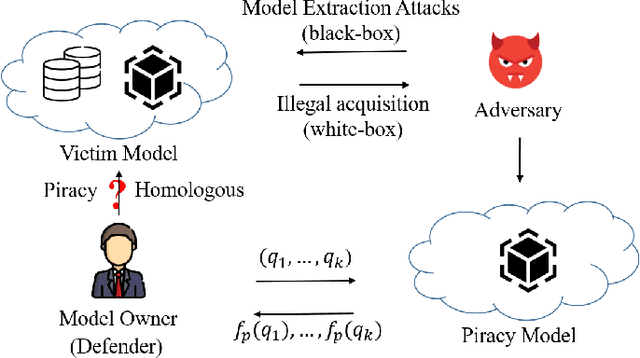

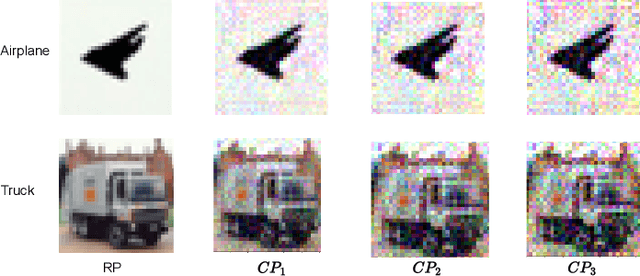
As intellectual property rights, the copyright protection of deep models is becoming increasingly important. Existing work has made many attempts at model watermarking and fingerprinting, but they have ignored homologous models trained with similar structures or training datasets. We highlight challenges in efficiently querying black-box piracy models to protect model copyrights without misidentifying homologous models. To address these challenges, we propose a novel method called DeepCore, which discovers that the classification confidence of the model is positively correlated with the distance of the predicted sample from the model decision boundary and piracy models behave more similarly at high-confidence classified sample points. Then DeepCore constructs core points far away from the decision boundary by optimizing the predicted confidence of a few sample points and leverages behavioral discrepancies between piracy and homologous models to identify piracy models. Finally, we design different model identification methods, including two similarity-based methods and a clustering-based method to identify piracy models using models' predictions of core points. Extensive experiments show the effectiveness of DeepCore in identifying various piracy models, achieving lower missed and false identification rates, and outperforming state-of-the-art methods.