 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow vehicles change lanes after encountering crashes: Empirical analysis and modeling
Jan 13, 2026When a traffic crash occurs, following vehicles need to change lanes to bypass the obstruction. We define these maneuvers as post crash lane changes. In such scenarios, vehicles in the target lane may refuse to yield even after the lane change has already begun, increasing the complexity and crash risk of post crash LCs. However, the behavioral characteristics and motion patterns of post crash LCs remain unknown. To address this gap, we construct a post crash LC dataset by extracting vehicle trajectories from drone videos captured after crashes. Our empirical analysis reveals that, compared to mandatory LCs (MLCs) and discretionary LCs (DLCs), post crash LCs exhibit longer durations, lower insertion speeds, and higher crash risks. Notably, 79.4% of post crash LCs involve at least one instance of non yielding behavior from the new follower, compared to 21.7% for DLCs and 28.6% for MLCs. Building on these findings, we develop a novel trajectory prediction framework for post crash LCs. At its core is a graph based attention module that explicitly models yielding behavior as an auxiliary interaction aware task. This module is designed to guide both a conditional variational autoencoder and a Transformer based decoder to predict the lane changer's trajectory. By incorporating the interaction aware module, our model outperforms existing baselines in trajectory prediction performance by more than 10% in both average displacement error and final displacement error across different prediction horizons. Moreover, our model provides more reliable crash risk analysis by reducing false crash rates and improving conflict prediction accuracy. Finally, we validate the model's transferability using additional post crash LC datasets collected from different sites.
Distil the informative essence of loop detector data set: Is network-level traffic forecasting hungry for more data?
Oct 31, 2023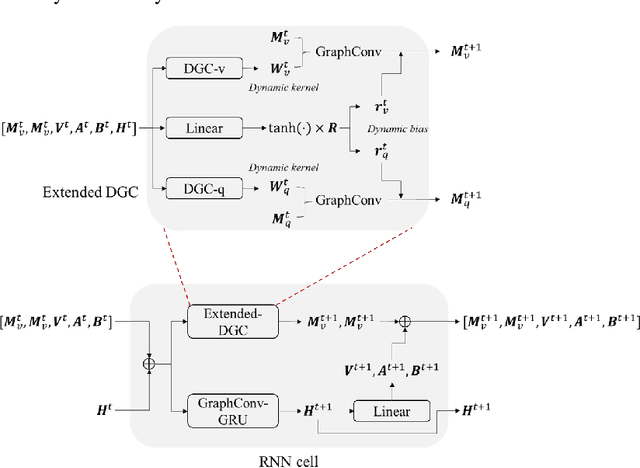
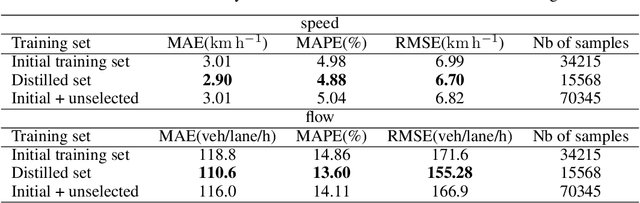
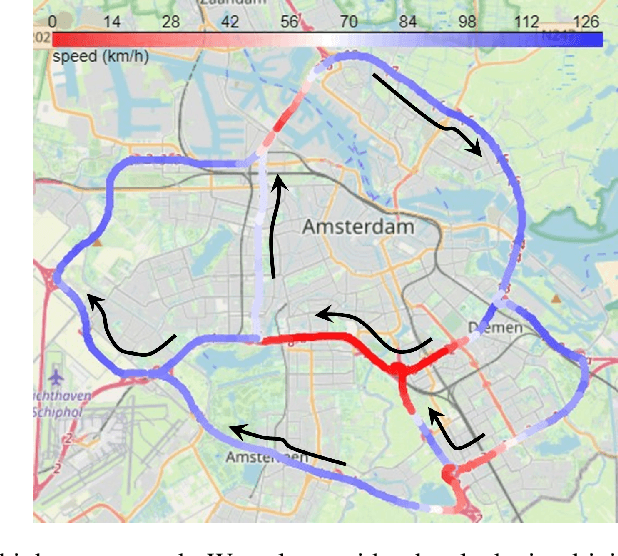
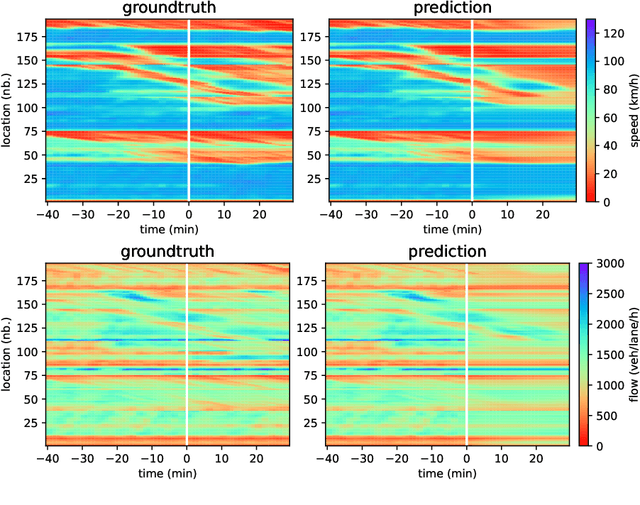
Network-level traffic condition forecasting has been intensively studied for decades. Although prediction accuracy has been continuously improved with emerging deep learning models and ever-expanding traffic data, traffic forecasting still faces many challenges in practice. These challenges include the robustness of data-driven models, the inherent unpredictability of traffic dynamics, and whether further improvement of traffic forecasting requires more sensor data. In this paper, we focus on this latter question and particularly on data from loop detectors. To answer this, we propose an uncertainty-aware traffic forecasting framework to explore how many samples of loop data are truly effective for training forecasting models. Firstly, the model design combines traffic flow theory with graph neural networks, ensuring the robustness of prediction and uncertainty quantification. Secondly, evidential learning is employed to quantify different sources of uncertainty in a single pass. The estimated uncertainty is used to "distil" the essence of the dataset that sufficiently covers the information content. Results from a case study of a highway network around Amsterdam show that, from 2018 to 2021, more than 80\% of the data during daytime can be removed. The remaining 20\% samples have equal prediction power for training models. This result suggests that indeed large traffic datasets can be subdivided into significantly smaller but equally informative datasets. From these findings, we conclude that the proposed methodology proves valuable in evaluating large traffic datasets' true information content. Further extensions, such as extracting smaller, spatially non-redundant datasets, are possible with this method.
Large Car-following Data Based on Lyft level-5 Open Dataset: Following Autonomous Vehicles vs. Human-driven Vehicles
May 30, 2023Car-Following (CF), as a fundamental driving behaviour, has significant influences on the safety and efficiency of traffic flow. Investigating how human drivers react differently when following autonomous vs. human-driven vehicles (HV) is thus critical for mixed traffic flow. Research in this field can be expedited with trajectory datasets collected by Autonomous Vehicles (AVs). However, trajectories collected by AVs are noisy and not readily applicable for studying CF behaviour. This paper extracts and enhances two categories of CF data, HV-following-AV (H-A) and HV-following-HV (H-H), from the open Lyft level-5 dataset. First, CF pairs are selected based on specific rules. Next, the quality of raw data is assessed by anomaly analysis. Then, the raw CF data is corrected and enhanced via motion planning, Kalman filtering, and wavelet denoising. As a result, 29k+ H-A and 42k+ H-H car-following segments are obtained, with a total driving distance of 150k+ km. A diversity assessment shows that the processed data cover complete CF regimes for calibrating CF models. This open and ready-to-use dataset provides the opportunity to investigate the CF behaviours of following AVs vs. HVs from real-world data. It can further facilitate studies on exploring the impact of AVs on mixed urban traffic.