 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistil the informative essence of loop detector data set: Is network-level traffic forecasting hungry for more data?
Paper and Code
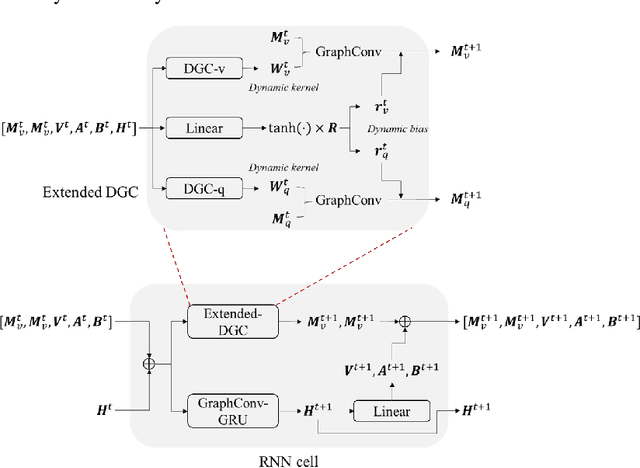
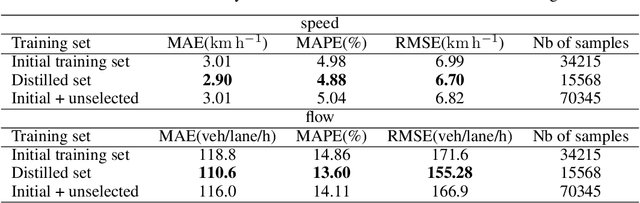
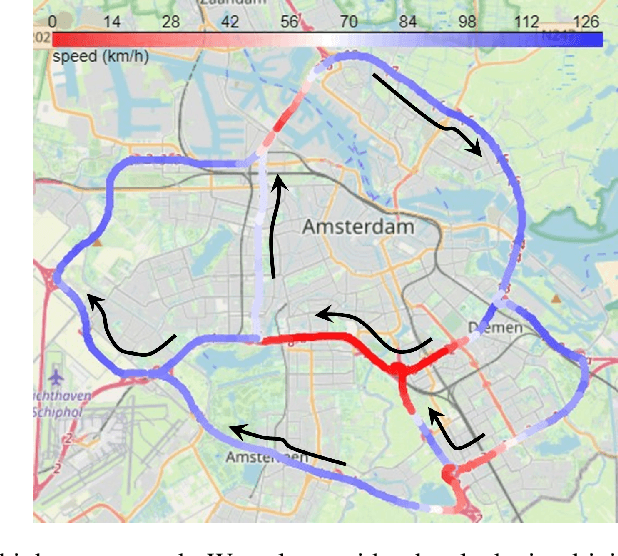
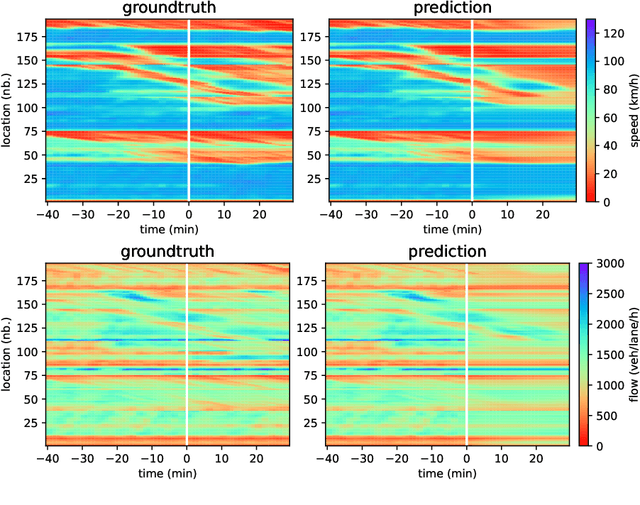
Network-level traffic condition forecasting has been intensively studied for decades. Although prediction accuracy has been continuously improved with emerging deep learning models and ever-expanding traffic data, traffic forecasting still faces many challenges in practice. These challenges include the robustness of data-driven models, the inherent unpredictability of traffic dynamics, and whether further improvement of traffic forecasting requires more sensor data. In this paper, we focus on this latter question and particularly on data from loop detectors. To answer this, we propose an uncertainty-aware traffic forecasting framework to explore how many samples of loop data are truly effective for training forecasting models. Firstly, the model design combines traffic flow theory with graph neural networks, ensuring the robustness of prediction and uncertainty quantification. Secondly, evidential learning is employed to quantify different sources of uncertainty in a single pass. The estimated uncertainty is used to "distil" the essence of the dataset that sufficiently covers the information content. Results from a case study of a highway network around Amsterdam show that, from 2018 to 2021, more than 80\% of the data during daytime can be removed. The remaining 20\% samples have equal prediction power for training models. This result suggests that indeed large traffic datasets can be subdivided into significantly smaller but equally informative datasets. From these findings, we conclude that the proposed methodology proves valuable in evaluating large traffic datasets' true information content. Further extensions, such as extracting smaller, spatially non-redundant datasets, are possible with this method.