 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Paper and Code
Aug 20, 2023
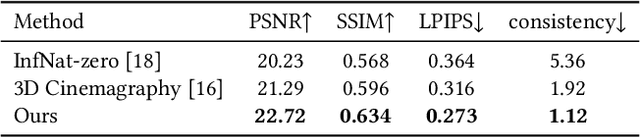
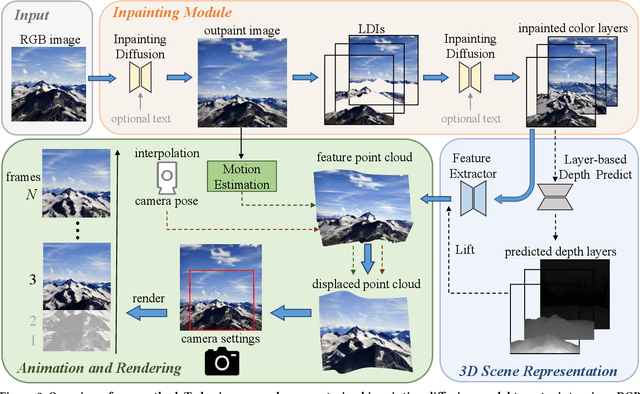
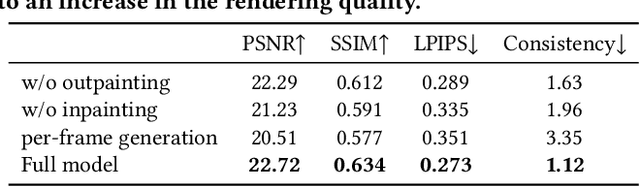
We study the problem of synthesizing a long-term dynamic video from only a single image. This is challenging since it requires consistent visual content movements given large camera motions. Existing methods either hallucinate inconsistent perpetual views or struggle with long camera trajectories. To address these issues, it is essential to estimate the underlying 4D (including 3D geometry and scene motion) and fill in the occluded regions. To this end, we present Make-It-4D, a novel method that can generate a consistent long-term dynamic video from a single image. On the one hand, we utilize layered depth images (LDIs) to represent a scene, and they are then unprojected to form a feature point cloud. To animate the visual content, the feature point cloud is displaced based on the scene flow derived from motion estimation and the corresponding camera pose. Such 4D representation enables our method to maintain the global consistency of the generated dynamic video. On the other hand, we fill in the occluded regions by using a pretrained diffusion model to inpaint and outpaint the input image. This enables our method to work under large camera motions. Benefiting from our design, our method can be training-free which saves a significant amount of training time. Experimental results demonstrate the effectiveness of our approach, which showcases compelling rendering results.