 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFind Beauty in the Rare: Contrastive Composition Feature Clustering for Nontrivial Cropping Box Regression
Feb 17, 2023
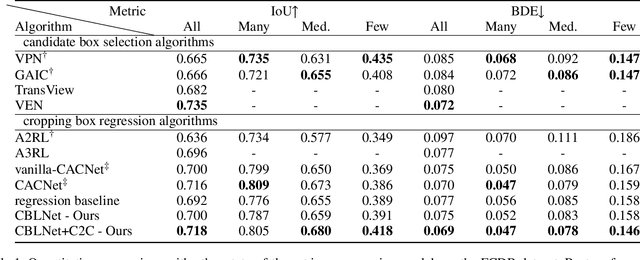


Automatic image cropping algorithms aim to recompose images like human-being photographers by generating the cropping boxes with improved composition quality. Cropping box regression approaches learn the beauty of composition from annotated cropping boxes. However, the bias of annotations leads to quasi-trivial recomposing results, which has an obvious tendency to the average location of training samples. The crux of this predicament is that the task is naively treated as a box regression problem, where rare samples might be dominated by normal samples, and the composition patterns of rare samples are not well exploited. Observing that similar composition patterns tend to be shared by the cropping boundaries annotated nearly, we argue to find the beauty of composition from the rare samples by clustering the samples with similar cropping boundary annotations, ie, similar composition patterns. We propose a novel Contrastive Composition Clustering (C2C) to regularize the composition features by contrasting dynamically established similar and dissimilar pairs. In this way, common composition patterns of multiple images can be better summarized, which especially benefits the rare samples and endows our model with better generalizability to render nontrivial results. Extensive experimental results show the superiority of our model compared with prior arts. We also illustrate the philosophy of our design with an interesting analytical visualization.
DoF-NeRF: Depth-of-Field Meets Neural Radiance Fields
Aug 01, 2022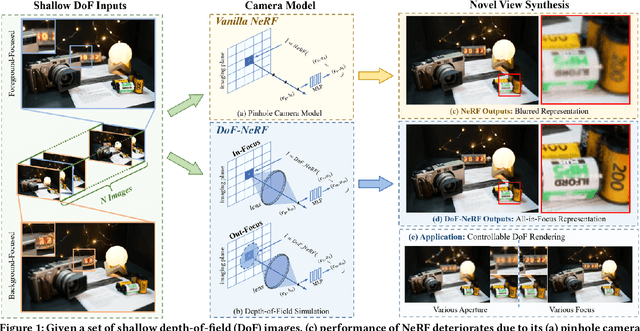
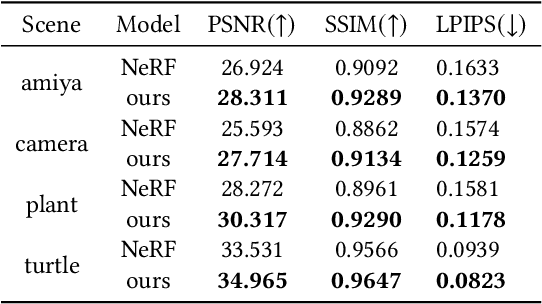
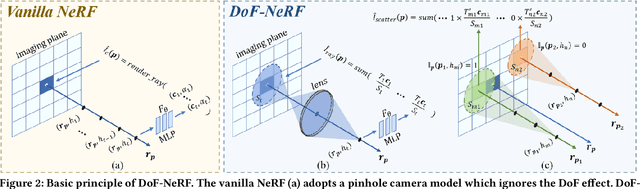
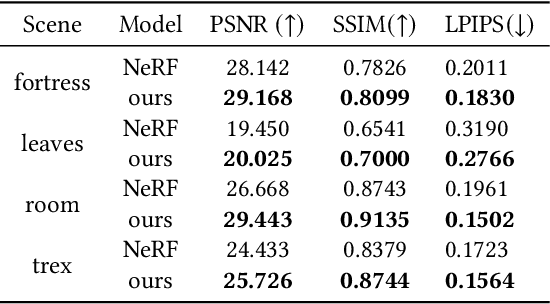
Neural Radiance Field (NeRF) and its variants have exhibited great success on representing 3D scenes and synthesizing photo-realistic novel views. However, they are generally based on the pinhole camera model and assume all-in-focus inputs. This limits their applicability as images captured from the real world often have finite depth-of-field (DoF). To mitigate this issue, we introduce DoF-NeRF, a novel neural rendering approach that can deal with shallow DoF inputs and can simulate DoF effect. In particular, it extends NeRF to simulate the aperture of lens following the principles of geometric optics. Such a physical guarantee allows DoF-NeRF to operate views with different focus configurations. Benefiting from explicit aperture modeling, DoF-NeRF also enables direct manipulation of DoF effect by adjusting virtual aperture and focus parameters. It is plug-and-play and can be inserted into NeRF-based frameworks. Experiments on synthetic and real-world datasets show that, DoF-NeRF not only performs comparably with NeRF in the all-in-focus setting, but also can synthesize all-in-focus novel views conditioned on shallow DoF inputs. An interesting application of DoF-NeRF to DoF rendering is also demonstrated. The source code will be made available at https://github.com/zijinwuzijin/DoF-NeRF.
Design What You Desire: Icon Generation from Orthogonal Application and Theme Labels
Jul 31, 2022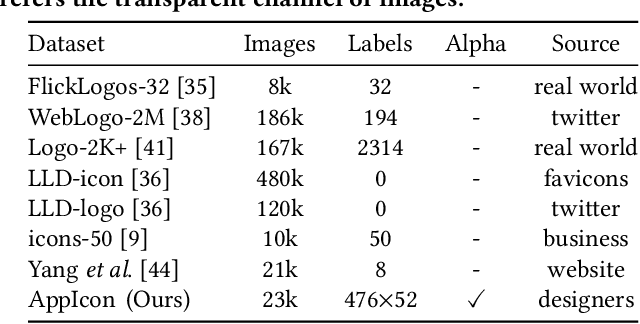
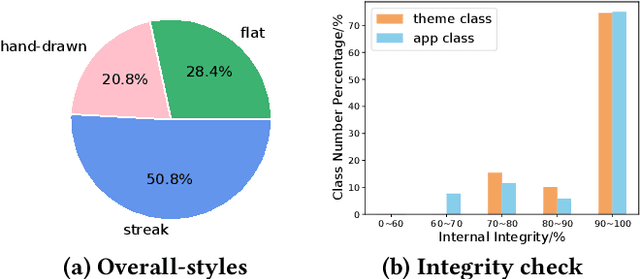
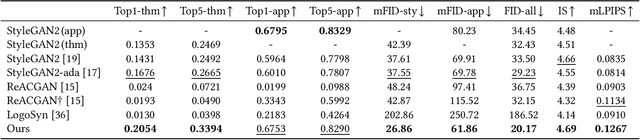
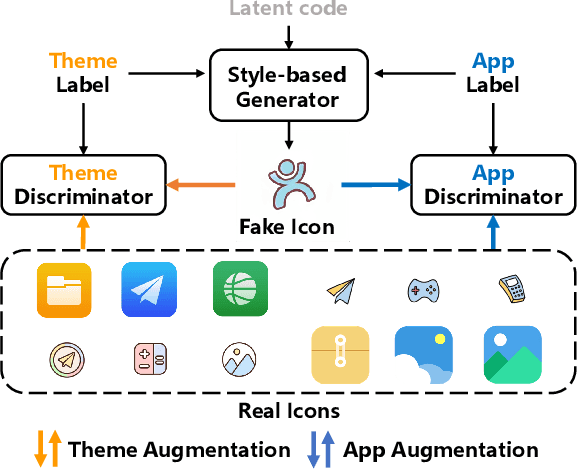
Generative adversarial networks (GANs) have been trained to be professional artists able to create stunning artworks such as face generation and image style transfer. In this paper, we focus on a realistic business scenario: automated generation of customizable icons given desired mobile applications and theme styles. We first introduce a theme-application icon dataset, termed AppIcon, where each icon has two orthogonal theme and app labels. By investigating a strong baseline StyleGAN2, we observe mode collapse caused by the entanglement of the orthogonal labels. To solve this challenge, we propose IconGAN composed of a conditional generator and dual discriminators with orthogonal augmentations, and a contrastive feature disentanglement strategy is further designed to regularize the feature space of the two discriminators. Compared with other approaches, IconGAN indicates a superior advantage on the AppIcon benchmark. Further analysis also justifies the effectiveness of disentangling app and theme representations. Our project will be released at: https://github.com/architect-road/IconGAN.
3D Instances as 1D Kernels
Jul 18, 2022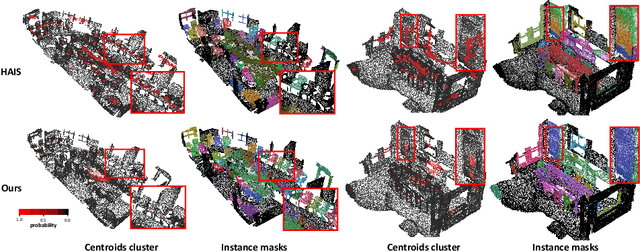
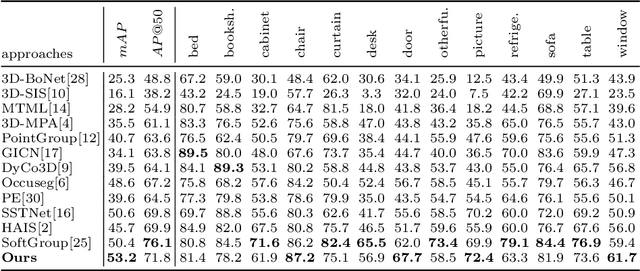
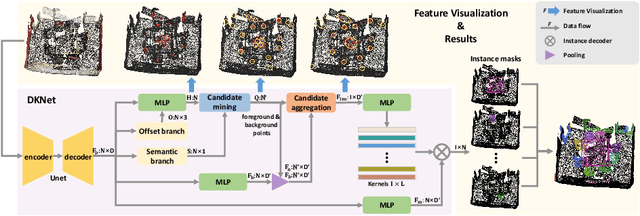
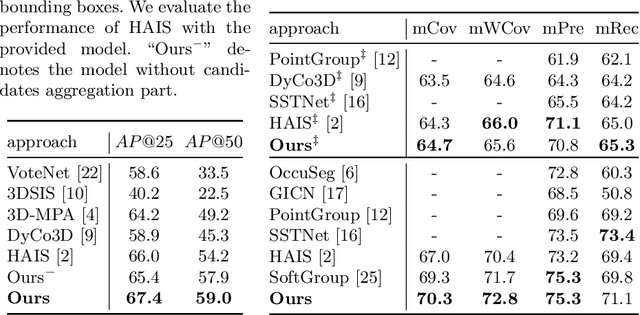
We introduce a 3D instance representation, termed instance kernels, where instances are represented by one-dimensional vectors that encode the semantic, positional, and shape information of 3D instances. We show that instance kernels enable easy mask inference by simply scanning kernels over the entire scenes, avoiding the heavy reliance on proposals or heuristic clustering algorithms in standard 3D instance segmentation pipelines. The idea of instance kernel is inspired by recent success of dynamic convolutions in 2D/3D instance segmentation. However, we find it non-trivial to represent 3D instances due to the disordered and unstructured nature of point cloud data, e.g., poor instance localization can significantly degrade instance representation. To remedy this, we construct a novel 3D instance encoding paradigm. First, potential instance centroids are localized as candidates. Then, a candidate merging scheme is devised to simultaneously aggregate duplicated candidates and collect context around the merged centroids to form the instance kernels. Once instance kernels are available, instance masks can be reconstructed via dynamic convolutions whose weights are conditioned on instance kernels. The whole pipeline is instantiated with a dynamic kernel network (DKNet). Results show that DKNet outperforms the state of the arts on both ScanNetV2 and S3DIS datasets with better instance localization. Code is available: https://github.com/W1zheng/DKNet.