 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersaTune: An Efficient Data Composition Framework for Training Multi-Capability LLMs
Paper and Code
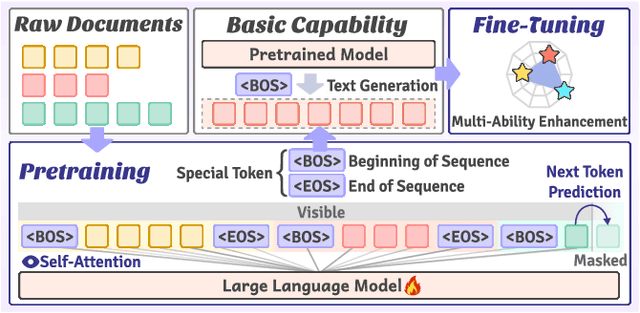



Large-scale pretrained models, particularly Large Language Models (LLMs), have exhibited remarkable capabilities in handling multiple tasks across domains due to their emergent properties. These capabilities are further augmented during the Supervised Fine-Tuning (SFT) phase. Despite their potential, existing work mainly focuses on domain-specific enhancements during fine-tuning, the challenge of which lies in catastrophic forgetting of knowledge across other domains. In this study, we introduce VersaTune, a novel data composition framework designed for enhancing LLMs' overall multi-ability performances during training. We categorize knowledge into distinct domains including law, medicine, finance, science, code, etc. We begin with detecting the distribution of domain-specific knowledge within the base model, followed by the training data composition that aligns with the model's existing knowledge distribution. During the training process, domain weights are dynamically adjusted based on their learnable potential and forgetting degree. Experimental results demonstrate that VersaTune achieves significant improvements in multi-domain performance, with an 35.21% enhancement in comprehensive multi-domain tasks. Additionally, in scenarios where specific domain optimization is required, VersaTune reduces the degradation of performance in other domains by 38.77%, without compromising the target domain's training efficacy.