Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Analysis on the Training Course of DeepSeek Models
Paper and Code
Feb 11, 2025


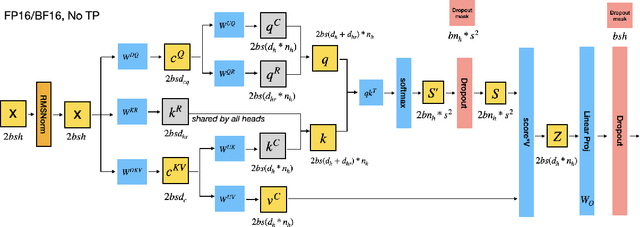
We present a theoretical analysis of GPU memory consumption during the training of DeepSeek models such as DeepSeek-v2 and DeepSeek-v3. Our primary objective is to clarify the device-level memory requirements associated with various distributed training configurations. Specifically, we examine critical factors influencing memory usage, including micro-batch size, activation recomputation policies, 3D parallelism, and ZeRO optimizations. It is important to emphasize that the training policies discussed in this report are not representative of DeepSeek's official configurations. Instead, they are explored to provide a deeper understanding of memory dynamics in training of large-scale mixture-of-experts model.
View paper on