 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElixir: A system to enhance data quality for multiple analytics on a video stream
Dec 08, 2022



IoT sensors, especially video cameras, are ubiquitously deployed around the world to perform a variety of computer vision tasks in several verticals including retail, healthcare, safety and security, transportation, manufacturing, etc. To amortize their high deployment effort and cost, it is desirable to perform multiple video analytics tasks, which we refer to as Analytical Units (AUs), off the video feed coming out of every camera. In this paper, we first show that in a multi-AU setting, changing the camera setting has disproportionate impact on different AUs performance. In particular, the optimal setting for one AU may severely degrade the performance for another AU, and further the impact on different AUs varies as the environmental condition changes. We then present Elixir, a system to enhance the video stream quality for multiple analytics on a video stream. Elixir leverages Multi-Objective Reinforcement Learning (MORL), where the RL agent caters to the objectives from different AUs and adjusts the camera setting to simultaneously enhance the performance of all AUs. To define the multiple objectives in MORL, we develop new AU-specific quality estimator values for each individual AU. We evaluate Elixir through real-world experiments on a testbed with three cameras deployed next to each other (overlooking a large enterprise parking lot) running Elixir and two baseline approaches, respectively. Elixir correctly detects 7.1% (22,068) and 5.0% (15,731) more cars, 94% (551) and 72% (478) more faces, and 670.4% (4975) and 158.6% (3507) more persons than the default-setting and time-sharing approaches, respectively. It also detects 115 license plates, far more than the time-sharing approach (7) and the default setting (0).
APT: Adaptive Perceptual quality based camera Tuning using reinforcement learning
Nov 15, 2022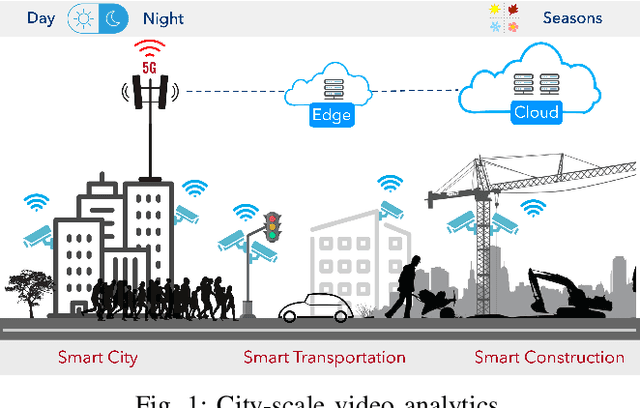
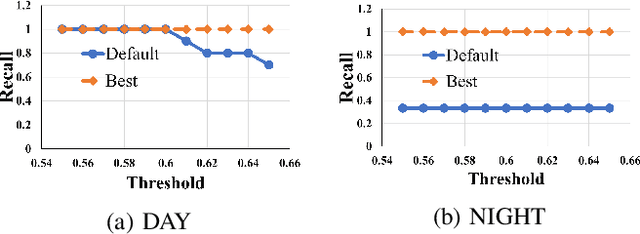
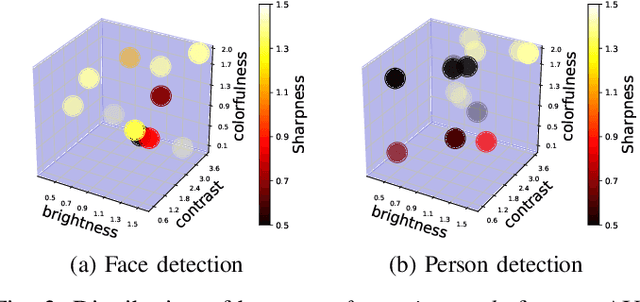
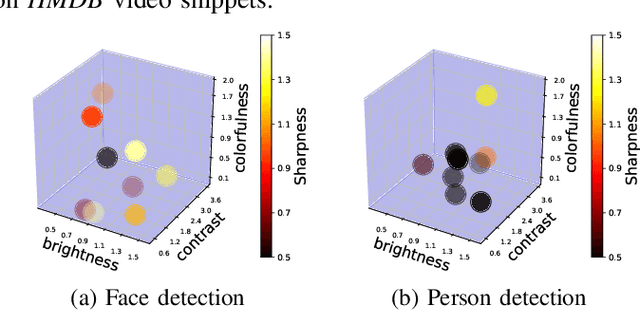
Cameras are increasingly being deployed in cities, enterprises and roads world-wide to enable many applications in public safety, intelligent transportation, retail, healthcare and manufacturing. Often, after initial deployment of the cameras, the environmental conditions and the scenes around these cameras change, and our experiments show that these changes can adversely impact the accuracy of insights from video analytics. This is because the camera parameter settings, though optimal at deployment time, are not the best settings for good-quality video capture as the environmental conditions and scenes around a camera change during operation. Capturing poor-quality video adversely affects the accuracy of analytics. To mitigate the loss in accuracy of insights, we propose a novel, reinforcement-learning based system APT that dynamically, and remotely (over 5G networks), tunes the camera parameters, to ensure a high-quality video capture, which mitigates any loss in accuracy of video analytics. As a result, such tuning restores the accuracy of insights when environmental conditions or scene content change. APT uses reinforcement learning, with no-reference perceptual quality estimation as the reward function. We conducted extensive real-world experiments, where we simultaneously deployed two cameras side-by-side overlooking an enterprise parking lot (one camera only has manufacturer-suggested default setting, while the other camera is dynamically tuned by APT during operation). Our experiments demonstrated that due to dynamic tuning by APT, the analytics insights are consistently better at all times of the day: the accuracy of object detection video analytics application was improved on average by ~ 42%. Since our reward function is independent of any analytics task, APT can be readily used for different video analytics tasks.
Why is the video analytics accuracy fluctuating, and what can we do about it?
Aug 23, 2022

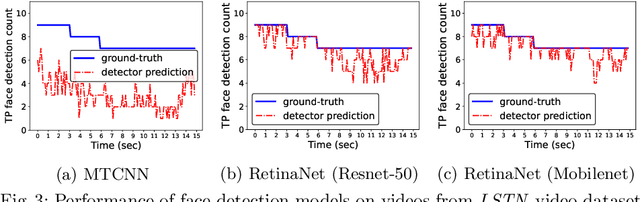
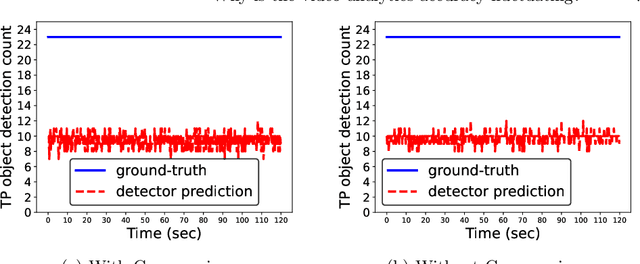
It is a common practice to think of a video as a sequence of images (frames), and re-use deep neural network models that are trained only on images for similar analytics tasks on videos. In this paper, we show that this leap of faith that deep learning models that work well on images will also work well on videos is actually flawed. We show that even when a video camera is viewing a scene that is not changing in any human-perceptible way, and we control for external factors like video compression and environment (lighting), the accuracy of video analytics application fluctuates noticeably. These fluctuations occur because successive frames produced by the video camera may look similar visually, but these frames are perceived quite differently by the video analytics applications. We observed that the root cause for these fluctuations is the dynamic camera parameter changes that a video camera automatically makes in order to capture and produce a visually pleasing video. The camera inadvertently acts as an unintentional adversary because these slight changes in the image pixel values in consecutive frames, as we show, have a noticeably adverse impact on the accuracy of insights from video analytics tasks that re-use image-trained deep learning models. To address this inadvertent adversarial effect from the camera, we explore the use of transfer learning techniques to improve learning in video analytics tasks through the transfer of knowledge from learning on image analytics tasks. In particular, we show that our newly trained Yolov5 model reduces fluctuation in object detection across frames, which leads to better tracking of objects(40% fewer mistakes in tracking). Our paper also provides new directions and techniques to mitigate the camera's adversarial effect on deep learning models used for video analytics applications.
CamTuner: Reinforcement-Learning based System for Camera Parameter Tuning to enhance Analytics
Jul 08, 2021
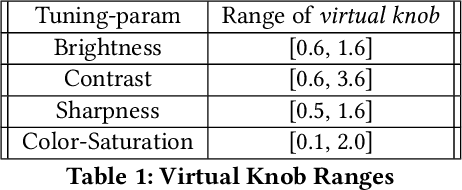
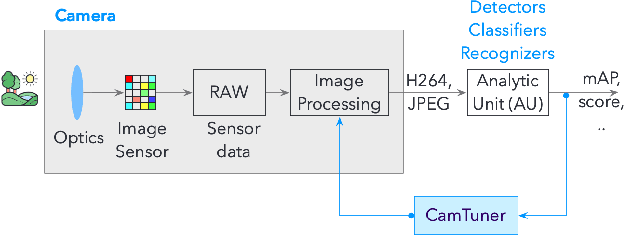
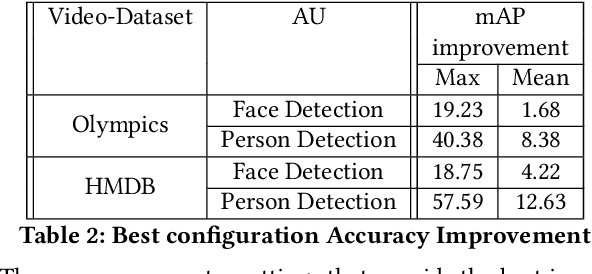
Complex sensors like video cameras include tens of configurable parameters, which can be set by end-users to customize the sensors to specific application scenarios. Although parameter settings significantly affect the quality of the sensor output and the accuracy of insights derived from sensor data, most end-users use a fixed parameter setting because they lack the skill or understanding to appropriately configure these parameters. We propose CamTuner, which is a system to automatically, and dynamically adapt the complex sensor to changing environments. CamTuner includes two key components. First, a bespoke analytics quality estimator, which is a deep-learning model to automatically and continuously estimate the quality of insights from an analytics unit as the environment around a sensor change. Second, a reinforcement learning (RL) module, which reacts to the changes in quality, and automatically adjusts the camera parameters to enhance the accuracy of insights. We improve the training time of the RL module by an order of magnitude by designing virtual models to mimic essential behavior of the camera: we design virtual knobs that can be set to different values to mimic the effects of assigning different values to the camera's configurable parameters, and we design a virtual camera model that mimics the output from a video camera at different times of the day. These virtual models significantly accelerate training because (a) frame rates from a real camera are limited to 25-30 fps while the virtual models enable processing at 300 fps, (b) we do not have to wait until the real camera sees different environments, which could take weeks or months, and (c) virtual knobs can be updated instantly, while it can take 200-500 ms to change the camera parameter settings. Our dynamic tuning approach results in up to 12% improvement in the accuracy of insights from several video analytics tasks.
AQuA: Analytical Quality Assessment for Optimizing Video Analytics Systems
Jan 24, 2021


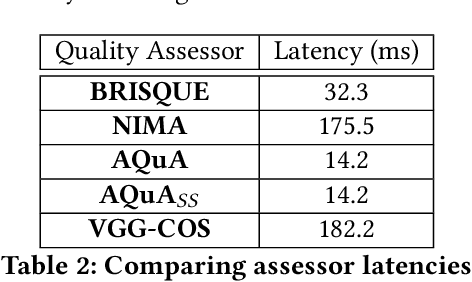
Millions of cameras at edge are being deployed to power a variety of different deep learning applications. However, the frames captured by these cameras are not always pristine - they can be distorted due to lighting issues, sensor noise, compression etc. Such distortions not only deteriorate visual quality, they impact the accuracy of deep learning applications that process such video streams. In this work, we introduce AQuA, to protect application accuracy against such distorted frames by scoring the level of distortion in the frames. It takes into account the analytical quality of frames, not the visual quality, by learning a novel metric, classifier opinion score, and uses a lightweight, CNN-based, object-independent feature extractor. AQuA accurately scores distortion levels of frames and generalizes to multiple different deep learning applications. When used for filtering poor quality frames at edge, it reduces high-confidence errors for analytics applications by 17%. Through filtering, and due to its low overhead (14ms), AQuA can also reduce computation time and average bandwidth usage by 25%.