 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingRAG: Real-time Contextual Retrieval and Generation Framework
Jan 23, 2025
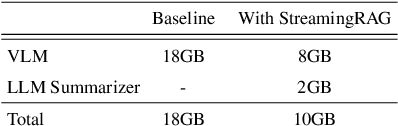


Extracting real-time insights from multi-modal data streams from various domains such as healthcare, intelligent transportation, and satellite remote sensing remains a challenge. High computational demands and limited knowledge scope restrict the applicability of Multi-Modal Large Language Models (MM-LLMs) on these data streams. Traditional Retrieval-Augmented Generation (RAG) systems address knowledge limitations of these models, but suffer from slow preprocessing, making them unsuitable for real-time analysis. We propose StreamingRAG, a novel RAG framework designed for streaming data. StreamingRAG constructs evolving knowledge graphs capturing scene-object-entity relationships in real-time. The knowledge graph achieves temporal-aware scene representations using MM-LLMs and enables timely responses for specific events or user queries. StreamingRAG addresses limitations in existing methods, achieving significant improvements in real-time analysis (5-6x faster throughput), contextual accuracy (through a temporal knowledge graph), and reduced resource consumption (using lightweight models by 2-3x).
Re-ranking the Context for Multimodal Retrieval Augmented Generation
Jan 08, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge to generate a response within a context with improved accuracy and reduced hallucinations. However, multi-modal RAG systems face unique challenges: (i) the retrieval process may select irrelevant entries to user query (e.g., images, documents), and (ii) vision-language models or multi-modal language models like GPT-4o may hallucinate when processing these entries to generate RAG output. In this paper, we aim to address the first challenge, i.e, improving the selection of relevant context from the knowledge-base in retrieval phase of the multi-modal RAG. Specifically, we leverage the relevancy score (RS) measure designed in our previous work for evaluating the RAG performance to select more relevant entries in retrieval process. The retrieval based on embeddings, say CLIP-based embedding, and cosine similarity usually perform poorly particularly for multi-modal data. We show that by using a more advanced relevancy measure, one can enhance the retrieval process by selecting more relevant pieces from the knowledge-base and eliminate the irrelevant pieces from the context by adaptively selecting up-to-$k$ entries instead of fixed number of entries. Our evaluation using COCO dataset demonstrates significant enhancement in selecting relevant context and accuracy of the generated response.
RAG-Check: Evaluating Multimodal Retrieval Augmented Generation Performance
Jan 07, 2025Retrieval-augmented generation (RAG) improves large language models (LLMs) by using external knowledge to guide response generation, reducing hallucinations. However, RAG, particularly multi-modal RAG, can introduce new hallucination sources: (i) the retrieval process may select irrelevant pieces (e.g., documents, images) as raw context from the database, and (ii) retrieved images are processed into text-based context via vision-language models (VLMs) or directly used by multi-modal language models (MLLMs) like GPT-4o, which may hallucinate. To address this, we propose a novel framework to evaluate the reliability of multi-modal RAG using two performance measures: (i) the relevancy score (RS), assessing the relevance of retrieved entries to the query, and (ii) the correctness score (CS), evaluating the accuracy of the generated response. We train RS and CS models using a ChatGPT-derived database and human evaluator samples. Results show that both models achieve ~88% accuracy on test data. Additionally, we construct a 5000-sample human-annotated database evaluating the relevancy of retrieved pieces and the correctness of response statements. Our RS model aligns with human preferences 20% more often than CLIP in retrieval, and our CS model matches human preferences ~91% of the time. Finally, we assess various RAG systems' selection and generation performances using RS and CS.
Deep Learning-Based Real-Time Quality Control of Standard Video Compression for Live Streaming
Nov 21, 2023Ensuring high-quality video content for wireless users has become increasingly vital. Nevertheless, maintaining a consistent level of video quality faces challenges due to the fluctuating encoded bitrate, primarily caused by dynamic video content, especially in live streaming scenarios. Video compression is typically employed to eliminate unnecessary redundancies within and between video frames, thereby reducing the required bandwidth for video transmission. The encoded bitrate and the quality of the compressed video depend on encoder parameters, specifically, the quantization parameter (QP). Poor choices of encoder parameters can result in reduced bandwidth efficiency and high likelihood of non-conformance. Non-conformance refers to the violation of the peak signal-to-noise ratio (PSNR) constraint for an encoded video segment. To address these issues, a real-time deep learning-based H.264 controller is proposed. This controller dynamically estimates the optimal encoder parameters based on the content of a video chunk with minimal delay. The objective is to maintain video quality in terms of PSNR above a specified threshold while minimizing the average bitrate of the compressed video. Experimental results, conducted on both QCIF dataset and a diverse range of random videos from public datasets, validate the effectiveness of this approach. Notably, it achieves improvements of up to 2.5 times in average bandwidth usage compared to the state-of-the-art adaptive bitrate video streaming, with a negligible non-conformance probability below $10^{-2}$.
Deep Learning-Based Real-Time Rate Control for Live Streaming on Wireless Networks
Sep 27, 2023Providing wireless users with high-quality video content has become increasingly important. However, ensuring consistent video quality poses challenges due to variable encoded bitrate caused by dynamic video content and fluctuating channel bitrate caused by wireless fading effects. Suboptimal selection of encoder parameters can lead to video quality loss due to underutilized bandwidth or the introduction of video artifacts due to packet loss. To address this, a real-time deep learning based H.264 controller is proposed. This controller leverages instantaneous channel quality data driven from the physical layer, along with the video chunk, to dynamically estimate the optimal encoder parameters with a negligible delay in real-time. The objective is to maintain an encoded video bitrate slightly below the available channel bitrate. Experimental results, conducted on both QCIF dataset and a diverse selection of random videos from public datasets, validate the effectiveness of the approach. Remarkably, improvements of 10-20 dB in PSNR with repect to the state-of-the-art adaptive bitrate video streaming is achieved, with an average packet drop rate as low as 0.002.
Semantic Multi-Resolution Communications
Aug 22, 2023Deep learning based joint source-channel coding (JSCC) has demonstrated significant advancements in data reconstruction compared to separate source-channel coding (SSCC). This superiority arises from the suboptimality of SSCC when dealing with finite block-length data. Moreover, SSCC falls short in reconstructing data in a multi-user and/or multi-resolution fashion, as it only tries to satisfy the worst channel and/or the highest quality data. To overcome these limitations, we propose a novel deep learning multi-resolution JSCC framework inspired by the concept of multi-task learning (MTL). This proposed framework excels at encoding data for different resolutions through hierarchical layers and effectively decodes it by leveraging both current and past layers of encoded data. Moreover, this framework holds great potential for semantic communication, where the objective extends beyond data reconstruction to preserving specific semantic attributes throughout the communication process. These semantic features could be crucial elements such as class labels, essential for classification tasks, or other key attributes that require preservation. Within this framework, each level of encoded data can be carefully designed to retain specific data semantics. As a result, the precision of a semantic classifier can be progressively enhanced across successive layers, emphasizing the preservation of targeted semantics throughout the encoding and decoding stages. We conduct experiments on MNIST and CIFAR10 dataset. The experiment with both datasets illustrates that our proposed method is capable of surpassing the SSCC method in reconstructing data with different resolutions, enabling the extraction of semantic features with heightened confidence in successive layers. This capability is particularly advantageous for prioritizing and preserving more crucial semantic features within the datasets.
Elixir: A system to enhance data quality for multiple analytics on a video stream
Dec 08, 2022



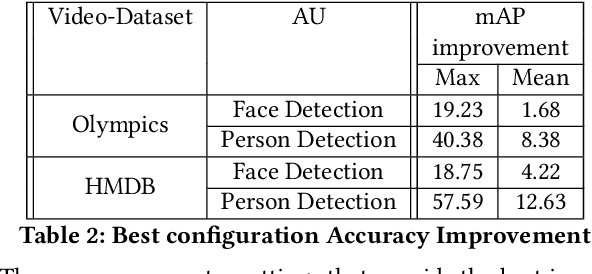
IoT sensors, especially video cameras, are ubiquitously deployed around the world to perform a variety of computer vision tasks in several verticals including retail, healthcare, safety and security, transportation, manufacturing, etc. To amortize their high deployment effort and cost, it is desirable to perform multiple video analytics tasks, which we refer to as Analytical Units (AUs), off the video feed coming out of every camera. In this paper, we first show that in a multi-AU setting, changing the camera setting has disproportionate impact on different AUs performance. In particular, the optimal setting for one AU may severely degrade the performance for another AU, and further the impact on different AUs varies as the environmental condition changes. We then present Elixir, a system to enhance the video stream quality for multiple analytics on a video stream. Elixir leverages Multi-Objective Reinforcement Learning (MORL), where the RL agent caters to the objectives from different AUs and adjusts the camera setting to simultaneously enhance the performance of all AUs. To define the multiple objectives in MORL, we develop new AU-specific quality estimator values for each individual AU. We evaluate Elixir through real-world experiments on a testbed with three cameras deployed next to each other (overlooking a large enterprise parking lot) running Elixir and two baseline approaches, respectively. Elixir correctly detects 7.1% (22,068) and 5.0% (15,731) more cars, 94% (551) and 72% (478) more faces, and 670.4% (4975) and 158.6% (3507) more persons than the default-setting and time-sharing approaches, respectively. It also detects 115 license plates, far more than the time-sharing approach (7) and the default setting (0).
CamTuner: Reinforcement-Learning based System for Camera Parameter Tuning to enhance Analytics
Jul 08, 2021
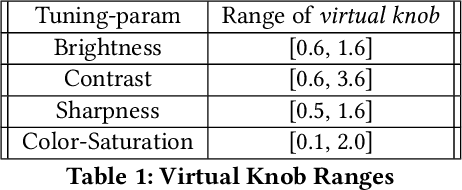
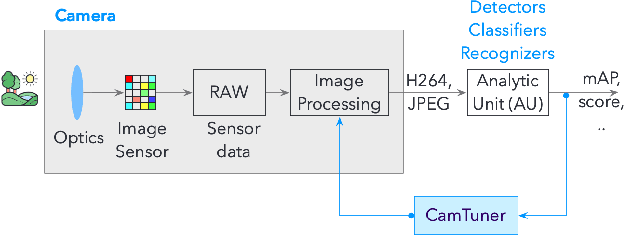
Complex sensors like video cameras include tens of configurable parameters, which can be set by end-users to customize the sensors to specific application scenarios. Although parameter settings significantly affect the quality of the sensor output and the accuracy of insights derived from sensor data, most end-users use a fixed parameter setting because they lack the skill or understanding to appropriately configure these parameters. We propose CamTuner, which is a system to automatically, and dynamically adapt the complex sensor to changing environments. CamTuner includes two key components. First, a bespoke analytics quality estimator, which is a deep-learning model to automatically and continuously estimate the quality of insights from an analytics unit as the environment around a sensor change. Second, a reinforcement learning (RL) module, which reacts to the changes in quality, and automatically adjusts the camera parameters to enhance the accuracy of insights. We improve the training time of the RL module by an order of magnitude by designing virtual models to mimic essential behavior of the camera: we design virtual knobs that can be set to different values to mimic the effects of assigning different values to the camera's configurable parameters, and we design a virtual camera model that mimics the output from a video camera at different times of the day. These virtual models significantly accelerate training because (a) frame rates from a real camera are limited to 25-30 fps while the virtual models enable processing at 300 fps, (b) we do not have to wait until the real camera sees different environments, which could take weeks or months, and (c) virtual knobs can be updated instantly, while it can take 200-500 ms to change the camera parameter settings. Our dynamic tuning approach results in up to 12% improvement in the accuracy of insights from several video analytics tasks.
AQuA: Analytical Quality Assessment for Optimizing Video Analytics Systems
Jan 24, 2021


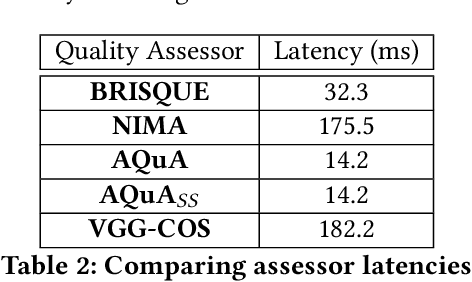
Millions of cameras at edge are being deployed to power a variety of different deep learning applications. However, the frames captured by these cameras are not always pristine - they can be distorted due to lighting issues, sensor noise, compression etc. Such distortions not only deteriorate visual quality, they impact the accuracy of deep learning applications that process such video streams. In this work, we introduce AQuA, to protect application accuracy against such distorted frames by scoring the level of distortion in the frames. It takes into account the analytical quality of frames, not the visual quality, by learning a novel metric, classifier opinion score, and uses a lightweight, CNN-based, object-independent feature extractor. AQuA accurately scores distortion levels of frames and generalizes to multiple different deep learning applications. When used for filtering poor quality frames at edge, it reduces high-confidence errors for analytics applications by 17%. Through filtering, and due to its low overhead (14ms), AQuA can also reduce computation time and average bandwidth usage by 25%.