 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Semantic Communication
Dec 17, 2025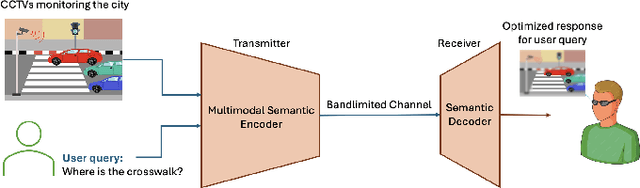
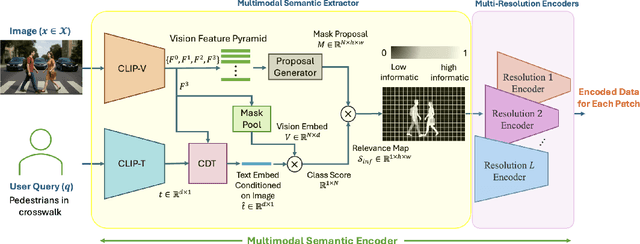
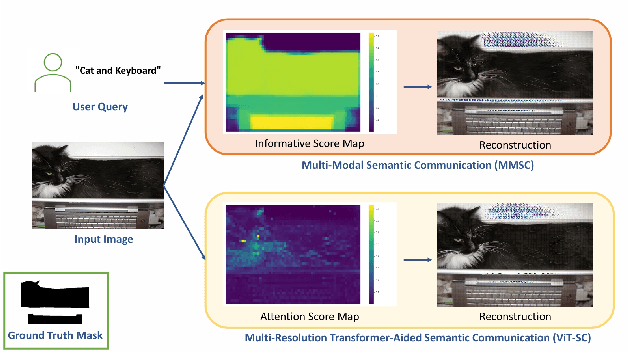
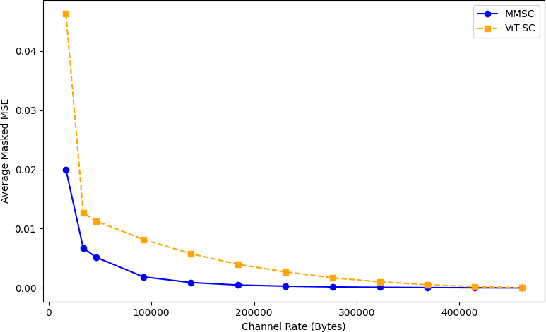
Semantic communication aims to transmit information most relevant to a task rather than raw data, offering significant gains in communication efficiency for applications such as telepresence, augmented reality, and remote sensing. Recent transformer-based approaches have used self-attention maps to identify informative regions within images, but they often struggle in complex scenes with multiple objects, where self-attention lacks explicit task guidance. To address this, we propose a novel Multi-Modal Semantic Communication framework that integrates text-based user queries to guide the information extraction process. Our proposed system employs a cross-modal attention mechanism that fuses visual features with language embeddings to produce soft relevance scores over the visual data. Based on these scores and the instantaneous channel bandwidth, we use an algorithm to transmit image patches at adaptive resolutions using independently trained encoder-decoder pairs, with total bitrate matching the channel capacity. At the receiver, the patches are reconstructed and combined to preserve task-critical information. This flexible and goal-driven design enables efficient semantic communication in complex and bandwidth-constrained environments.
Re-ranking the Context for Multimodal Retrieval Augmented Generation
Jan 08, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge to generate a response within a context with improved accuracy and reduced hallucinations. However, multi-modal RAG systems face unique challenges: (i) the retrieval process may select irrelevant entries to user query (e.g., images, documents), and (ii) vision-language models or multi-modal language models like GPT-4o may hallucinate when processing these entries to generate RAG output. In this paper, we aim to address the first challenge, i.e, improving the selection of relevant context from the knowledge-base in retrieval phase of the multi-modal RAG. Specifically, we leverage the relevancy score (RS) measure designed in our previous work for evaluating the RAG performance to select more relevant entries in retrieval process. The retrieval based on embeddings, say CLIP-based embedding, and cosine similarity usually perform poorly particularly for multi-modal data. We show that by using a more advanced relevancy measure, one can enhance the retrieval process by selecting more relevant pieces from the knowledge-base and eliminate the irrelevant pieces from the context by adaptively selecting up-to-$k$ entries instead of fixed number of entries. Our evaluation using COCO dataset demonstrates significant enhancement in selecting relevant context and accuracy of the generated response.
RAG-Check: Evaluating Multimodal Retrieval Augmented Generation Performance
Jan 07, 2025Retrieval-augmented generation (RAG) improves large language models (LLMs) by using external knowledge to guide response generation, reducing hallucinations. However, RAG, particularly multi-modal RAG, can introduce new hallucination sources: (i) the retrieval process may select irrelevant pieces (e.g., documents, images) as raw context from the database, and (ii) retrieved images are processed into text-based context via vision-language models (VLMs) or directly used by multi-modal language models (MLLMs) like GPT-4o, which may hallucinate. To address this, we propose a novel framework to evaluate the reliability of multi-modal RAG using two performance measures: (i) the relevancy score (RS), assessing the relevance of retrieved entries to the query, and (ii) the correctness score (CS), evaluating the accuracy of the generated response. We train RS and CS models using a ChatGPT-derived database and human evaluator samples. Results show that both models achieve ~88% accuracy on test data. Additionally, we construct a 5000-sample human-annotated database evaluating the relevancy of retrieved pieces and the correctness of response statements. Our RS model aligns with human preferences 20% more often than CLIP in retrieval, and our CS model matches human preferences ~91% of the time. Finally, we assess various RAG systems' selection and generation performances using RS and CS.
Efficient Semantic Communication Through Transformer-Aided Compression
Dec 02, 2024



Transformers, known for their attention mechanisms, have proven highly effective in focusing on critical elements within complex data. This feature can effectively be used to address the time-varying channels in wireless communication systems. In this work, we introduce a channel-aware adaptive framework for semantic communication, where different regions of the image are encoded and compressed based on their semantic content. By employing vision transformers, we interpret the attention mask as a measure of the semantic contents of the patches and dynamically categorize the patches to be compressed at various rates as a function of the instantaneous channel bandwidth. Our method enhances communication efficiency by adapting the encoding resolution to the content's relevance, ensuring that even in highly constrained environments, critical information is preserved. We evaluate the proposed adaptive transmission framework using the TinyImageNet dataset, measuring both reconstruction quality and accuracy. The results demonstrate that our approach maintains high semantic fidelity while optimizing bandwidth, providing an effective solution for transmitting multi-resolution data in limited bandwidth conditions.
$r$Age-$k$: Communication-Efficient Federated Learning Using Age Factor
Oct 29, 2024



Federated learning (FL) is a collaborative approach where multiple clients, coordinated by a parameter server (PS), train a unified machine-learning model. The approach, however, suffers from two key challenges: data heterogeneity and communication overhead. Data heterogeneity refers to inconsistencies in model training arising from heterogeneous data at different clients. Communication overhead arises from the large volumes of parameter updates exchanged between the PS and clients. Existing solutions typically address these challenges separately. This paper introduces a new communication-efficient algorithm that uses the age of information metric to simultaneously tackle both limitations of FL. We introduce age vectors at the PS, which keep track of how often the different model parameters are updated from the clients. The PS uses this to selectively request updates for specific gradient indices from each client. Further, the PS employs age vectors to identify clients with statistically similar data and group them into clusters. The PS combines the age vectors of the clustered clients to efficiently coordinate gradient index updates among clients within a cluster. We evaluate our approach using the MNIST and CIFAR10 datasets in highly non-i.i.d. settings. The experimental results show that our proposed method can expedite training, surpassing other communication-efficient strategies in efficiency.
Age of Gossip in Networks with Multiple Views of a Source
Sep 24, 2024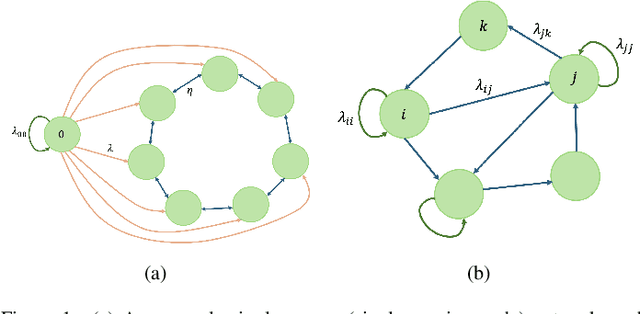
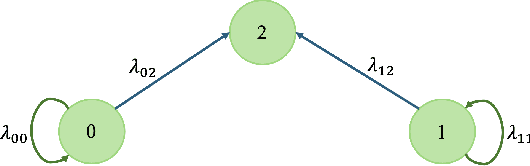
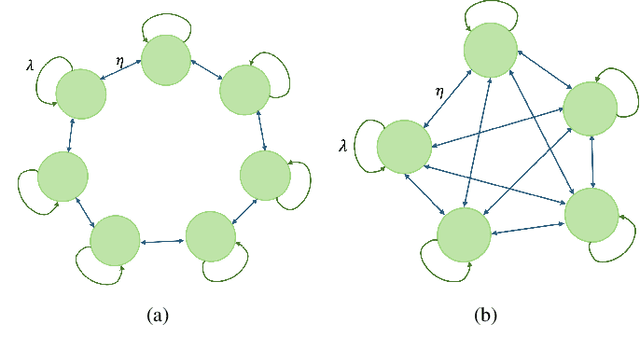
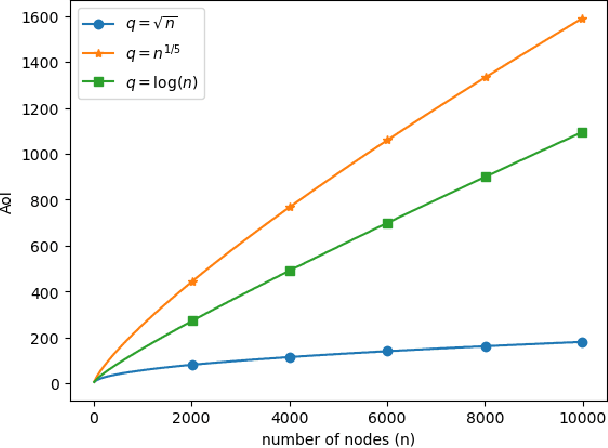
We consider the version age of information (AoI) in a network where a subset of nodes act as sensing nodes, sampling a source that in general can follow a continuous distribution. Any sample of the source constitutes a new version of the information and the version age of the information is defined with respect to the most recent version of the information available for the whole network. We derive a recursive expression for the average version AoI between different subsets of the nodes which can be used to evaluate the average version AoI for any subset of the nodes including any single node. We derive asymptotic behavior of the average AoI on any single node of the network for various topologies including line, ring, and fully connected networks. The prior art result on version age of a network by Yates [ISIT'21] can be interpreted as in our derivation as a network with a single view of the source, e.g., through a Poisson process with rate $\lambda_{00}$. Our result indicates that there is no loss in the average version AoI performance by replacing a single view of the source with distributed sensing across multiple nodes by splitting the same rate $\lambda_{00}$. Particularly, we show that asymptotically, the average AoI scales with $O(\log(n))$ and $O(\sqrt{n})$ for fully connected and ring networks, respectively. More interestingly, we show that for the ring network the same $O(\sqrt{n})$ asymptotical performance on average AoI is still achieved with distributed sensing if the number of sensing nodes only scales with $O(\sqrt{n})$ instead of prior known result which requires $O(n)$. Our results indicate that the sensing nodes can be arbitrarily chosen as long as the maximum number of consecutive non-sensing nodes also scales as $O(\sqrt{n})$.
Transformer-Aided Semantic Communications
May 02, 2024The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
Deep Learning-Based Real-Time Quality Control of Standard Video Compression for Live Streaming
Nov 21, 2023Ensuring high-quality video content for wireless users has become increasingly vital. Nevertheless, maintaining a consistent level of video quality faces challenges due to the fluctuating encoded bitrate, primarily caused by dynamic video content, especially in live streaming scenarios. Video compression is typically employed to eliminate unnecessary redundancies within and between video frames, thereby reducing the required bandwidth for video transmission. The encoded bitrate and the quality of the compressed video depend on encoder parameters, specifically, the quantization parameter (QP). Poor choices of encoder parameters can result in reduced bandwidth efficiency and high likelihood of non-conformance. Non-conformance refers to the violation of the peak signal-to-noise ratio (PSNR) constraint for an encoded video segment. To address these issues, a real-time deep learning-based H.264 controller is proposed. This controller dynamically estimates the optimal encoder parameters based on the content of a video chunk with minimal delay. The objective is to maintain video quality in terms of PSNR above a specified threshold while minimizing the average bitrate of the compressed video. Experimental results, conducted on both QCIF dataset and a diverse range of random videos from public datasets, validate the effectiveness of this approach. Notably, it achieves improvements of up to 2.5 times in average bandwidth usage compared to the state-of-the-art adaptive bitrate video streaming, with a negligible non-conformance probability below $10^{-2}$.
Deep Learning-Based Real-Time Rate Control for Live Streaming on Wireless Networks
Sep 27, 2023Providing wireless users with high-quality video content has become increasingly important. However, ensuring consistent video quality poses challenges due to variable encoded bitrate caused by dynamic video content and fluctuating channel bitrate caused by wireless fading effects. Suboptimal selection of encoder parameters can lead to video quality loss due to underutilized bandwidth or the introduction of video artifacts due to packet loss. To address this, a real-time deep learning based H.264 controller is proposed. This controller leverages instantaneous channel quality data driven from the physical layer, along with the video chunk, to dynamically estimate the optimal encoder parameters with a negligible delay in real-time. The objective is to maintain an encoded video bitrate slightly below the available channel bitrate. Experimental results, conducted on both QCIF dataset and a diverse selection of random videos from public datasets, validate the effectiveness of the approach. Remarkably, improvements of 10-20 dB in PSNR with repect to the state-of-the-art adaptive bitrate video streaming is achieved, with an average packet drop rate as low as 0.002.
Semantic Multi-Resolution Communications
Aug 22, 2023Deep learning based joint source-channel coding (JSCC) has demonstrated significant advancements in data reconstruction compared to separate source-channel coding (SSCC). This superiority arises from the suboptimality of SSCC when dealing with finite block-length data. Moreover, SSCC falls short in reconstructing data in a multi-user and/or multi-resolution fashion, as it only tries to satisfy the worst channel and/or the highest quality data. To overcome these limitations, we propose a novel deep learning multi-resolution JSCC framework inspired by the concept of multi-task learning (MTL). This proposed framework excels at encoding data for different resolutions through hierarchical layers and effectively decodes it by leveraging both current and past layers of encoded data. Moreover, this framework holds great potential for semantic communication, where the objective extends beyond data reconstruction to preserving specific semantic attributes throughout the communication process. These semantic features could be crucial elements such as class labels, essential for classification tasks, or other key attributes that require preservation. Within this framework, each level of encoded data can be carefully designed to retain specific data semantics. As a result, the precision of a semantic classifier can be progressively enhanced across successive layers, emphasizing the preservation of targeted semantics throughout the encoding and decoding stages. We conduct experiments on MNIST and CIFAR10 dataset. The experiment with both datasets illustrates that our proposed method is capable of surpassing the SSCC method in reconstructing data with different resolutions, enabling the extraction of semantic features with heightened confidence in successive layers. This capability is particularly advantageous for prioritizing and preserving more crucial semantic features within the datasets.