 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Mixture-of-Agents for Edge Inference with Large Language Models
Dec 30, 2024



Mixture-of-Agents (MoA) has recently been proposed as a method to enhance performance of large language models (LLMs), enabling multiple individual LLMs to work together for collaborative inference. This collaborative approach results in improved responses to user prompts compared to relying on a single LLM. In this paper, we consider such an MoA architecture in a distributed setting, where LLMs operate on individual edge devices, each uniquely associated with a user and equipped with its own distributed computing power. These devices exchange information using decentralized gossip algorithms, allowing different device nodes to talk without the supervision of a centralized server. In the considered setup, different users have their own LLM models to address user prompts. Additionally, the devices gossip either their own user-specific prompts or augmented prompts to generate more refined answers to certain queries. User prompts are temporarily stored in the device queues when their corresponding LLMs are busy. Given the memory limitations of edge devices, it is crucial to ensure that the average queue sizes in the system remain bounded. In this paper, we address this by theoretically calculating the queuing stability conditions for the device queues under reasonable assumptions, which we validate experimentally as well. Further, we demonstrate through experiments, leveraging open-source LLMs for the implementation of distributed MoA, that certain MoA configurations produce higher-quality responses compared to others, as evaluated on AlpacaEval 2.0 benchmark. The implementation is available at: https://github.com/purbeshmitra/distributed_moa.
$r$Age-$k$: Communication-Efficient Federated Learning Using Age Factor
Oct 29, 2024



Federated learning (FL) is a collaborative approach where multiple clients, coordinated by a parameter server (PS), train a unified machine-learning model. The approach, however, suffers from two key challenges: data heterogeneity and communication overhead. Data heterogeneity refers to inconsistencies in model training arising from heterogeneous data at different clients. Communication overhead arises from the large volumes of parameter updates exchanged between the PS and clients. Existing solutions typically address these challenges separately. This paper introduces a new communication-efficient algorithm that uses the age of information metric to simultaneously tackle both limitations of FL. We introduce age vectors at the PS, which keep track of how often the different model parameters are updated from the clients. The PS uses this to selectively request updates for specific gradient indices from each client. Further, the PS employs age vectors to identify clients with statistically similar data and group them into clusters. The PS combines the age vectors of the clustered clients to efficiently coordinate gradient index updates among clients within a cluster. We evaluate our approach using the MNIST and CIFAR10 datasets in highly non-i.i.d. settings. The experimental results show that our proposed method can expedite training, surpassing other communication-efficient strategies in efficiency.
Optimizing Profitability in Timely Gossip Networks
May 01, 2024



We consider a communication system where a group of users, interconnected in a bidirectional gossip network, wishes to follow a time-varying source, e.g., updates on an event, in real-time. The users wish to maintain their expected version ages below a threshold, and can either rely on gossip from their neighbors or directly subscribe to a server publishing about the event, if the former option does not meet the timeliness requirements. The server wishes to maximize its profit by increasing subscriptions from users and minimizing event sampling frequency to reduce costs. This leads to a Stackelberg game between the server and the users where the sender is the leader deciding its sampling frequency and the users are the followers deciding their subscription strategies. We investigate equilibrium strategies for low-connectivity and high-connectivity topologies.
How to Make Money From Fresh Data: Subscription Strategies in Age-Based Systems
Apr 24, 2024



We consider a communication system consisting of a server that tracks and publishes updates about a time-varying data source or event, and a gossip network of users interested in closely tracking the event. The timeliness of the information is measured through the version age of information. The users wish to have their expected version ages remain below a threshold, and have the option to either rely on gossip from their neighbors or subscribe to the server directly to follow updates about the event if the former option does not meet the timeliness requirements. The server wishes to maximize its profit by increasing the number of subscribers and reducing costs associated with the frequent sampling of the event. We model the problem setup as a Stackelberg game between the server and the users, where the server commits to a frequency of sampling the event, and the users make decisions on whether to subscribe or not. As an initial work, we focus on directed networks with unidirectional flow of information and obtain the optimal equilibrium strategies for all the players. We provide simulation results to confirm the theoretical findings and provide additional insights.
Timeliness: A New Design Metric and a New Attack Surface
Dec 28, 2023As the landscape of time-sensitive applications gains prominence in 5G/6G communications, timeliness of information updates at network nodes has become crucial, which is popularly quantified in the literature by the age of information metric. However, as we devise policies to improve age of information of our systems, we inadvertently introduce a new vulnerability for adversaries to exploit. In this article, we comprehensively discuss the diverse threats that age-based systems are vulnerable to. We begin with discussion on densely interconnected networks that employ gossiping between nodes to expedite dissemination of dynamic information in the network, and show how the age-based nature of gossiping renders these networks uniquely susceptible to threats such as timestomping attacks, jamming attacks, and the propagation of misinformation. Later, we survey adversarial works within simpler network settings, specifically in one-hop and two-hop configurations, and delve into adversarial robustness concerning challenges posed by jamming, timestomping, and issues related to privacy leakage. We conclude this article with future directions that aim to address challenges posed by more intelligent adversaries and robustness of networks to them.
Age of Information in Gossip Networks: A Friendly Introduction and Literature Survey
Dec 26, 2023
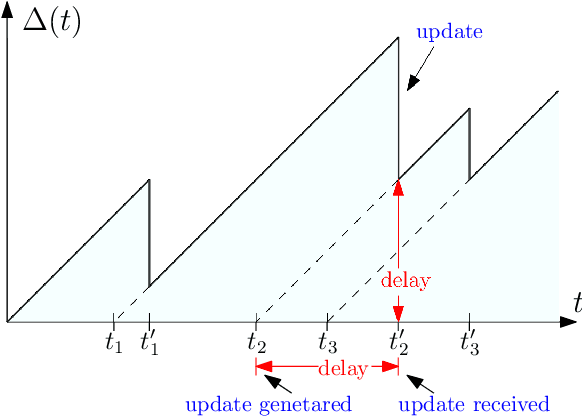
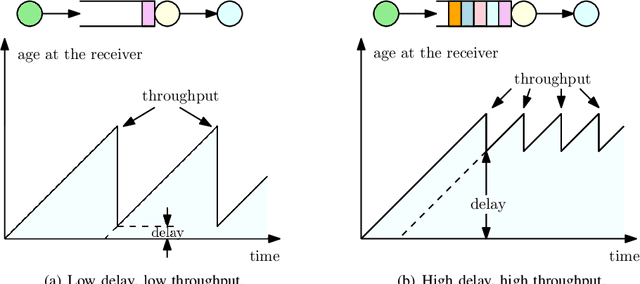
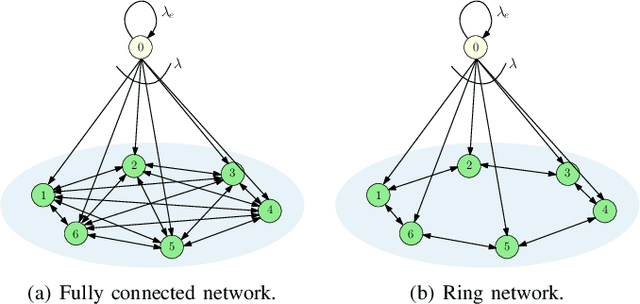
Gossiping is a communication mechanism, used for fast information dissemination in a network, where each node of the network randomly shares its information with the neighboring nodes. To characterize the notion of fastness in the context of gossip networks, age of information (AoI) is used as a timeliness metric. In this article, we summarize the recent works related to timely gossiping in a network. We start with the introduction of randomized gossip algorithms as an epidemic algorithm for database maintenance, and how the gossiping literature was later developed in the context of rumor spreading, message passing and distributed mean estimation. Then, we motivate the need for timely gossiping in applications such as source tracking and decentralized learning. We evaluate timeliness scaling of gossiping in various network topologies, such as, fully connected, ring, grid, generalized ring, hierarchical, and sparse asymmetric networks. We discuss age-aware gossiping and the higher order moments of the age process. We also consider different variations of gossiping in networks, such as, file slicing and network coding, reliable and unreliable sources, information mutation, different adversarial actions in gossiping, and energy harvesting sensors. Finally, we conclude this article with a few open problems and future directions in timely gossiping.
Choosing Outdated Information to Achieve Reliability in Age-Based Gossiping
Nov 14, 2023We consider a system model with two sources, a reliable source and an unreliable source, who are responsible for disseminating updates regarding a process to an age-based gossip network of $n$ nodes. Nodes wish to have fresh information, however, they have preference for packets that originated at the reliable source and are willing to sacrifice their version age of information by up to $G$ versions to switch from an unreliable packet to a reliable packet. We study how this protocol impacts the prevalence of unreliable packets at nodes in the network and their version age. Using a stochastic hybrid system (SHS) framework, we formulate analytical equations to characterize two quantities: expected fraction of nodes with unreliable packets and expected version age of information at network nodes. We show that as $G$ increases, fewer nodes have unreliable packet, however, their version age increases as well, thereby inducing a freshness-reliability trade-off in the network. We present numerical results to support our findings.
Age-Based Cache Updating Under Timestomping
Jul 18, 2023We consider a slotted communication system consisting of a source, a cache, a user and a timestomping adversary. The time horizon consists of total $T$ time slots, such that the source transmits update packets to the user directly over $T_{1}$ time slots and to the cache over $T_{2}$ time slots. We consider $T_{1}\ll T_{2}$, $T_{1}+T_{2} < T$, such that the source transmits to the user once between two consecutive cache updates. Update packets are marked with timestamps corresponding to their generation times at the source. All nodes have a buffer size of one and store the packet with the latest timestamp to minimize their age of information. In this setting, we consider the presence of an oblivious adversary that fully controls the communication link between the cache and the user. The adversary manipulates the timestamps of outgoing packets from the cache to the user, with the goal of bringing staleness at the user node. At each time slot, the adversary can choose to either forward the cached packet to the user, after changing its timestamp to current time $t$, thereby rebranding an old packet as a fresh packet and misleading the user into accepting it, or stay idle. The user compares the timestamps of every received packet with the latest packet in its possession to keep the fresher one and discard the staler packet. If the user receives update packets from both cache and source in a time slot, then the packet from source prevails. The goal of the source is to design an algorithm to minimize the average age at the user, and the goal of the adversary is to increase the average age at the user. We formulate this problem in an online learning setting and provide a fundamental lower bound on the competitive ratio for this problem. We further propose a deterministic algorithm with a provable guarantee on its competitive ratio.
Information Mutation and Spread of Misinformation in Timely Gossip Networks
May 08, 2023We consider a network of $n$ user nodes that receives updates from a source and employs an age-based gossip protocol for faster dissemination of version updates to all nodes. When a node forwards its packet to another node, the packet information gets mutated with probability $p$ during transmission, creating misinformation. The receiver node does not know whether an incoming packet information is different from the packet information originally at the sender node. We assume that truth prevails over misinformation, and therefore, when a receiver encounters both accurate information and misinformation corresponding to the same version, the accurate information gets chosen for storage at the node. We study the expected fraction of nodes with correct information in the network and version age at the nodes in this setting using stochastic hybrid systems (SHS) modelling and study their properties. We observe that very high or very low gossiping rates help curb misinformation, and misinformation spread is higher with moderate gossiping rates. We support our theoretical findings with simulation results which shed further light on the behavior of above quantities.
Timely Tracking of a Remote Dynamic Source Via Multi-Hop Renewal Updates
Apr 04, 2023We study the version age of information in a multi-hop multi-cast cache-enabled network, where updates at the source are marked with incrementing version numbers, and the inter-update times on the links are not necessarily exponentially distributed. We focus on the set of non-arithmetic distributions, which includes continuous probability distributions as a subset, with finite first and second moments for inter-update times. We first characterize the instantaneous version age of information at each node for an arbitrary network. We then explicate the recursive equations for instantaneous version age of information in multi-hop networks and employ semi-martingale representation of renewal processes to derive closed form expressions for the expected version age of information at an end user. We show that the expected age in a multi-hop network exhibits an additive structure. Further, we show that the expected age at each user is proportional to the variance of inter-update times at all links between a user and the source. Thus, end user nodes should request packet updates at constant intervals.