 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Act: A Two-Stage Framework for Mitigating Gender Bias Towards Vision-Language Tasks
Paper and Code
May 27, 2024
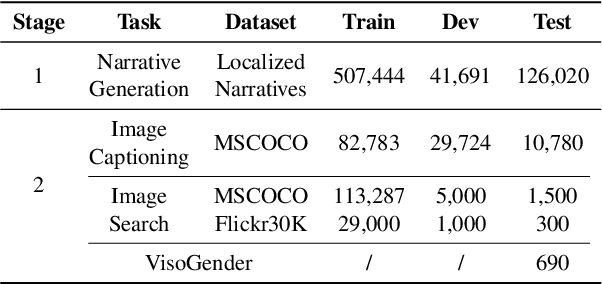
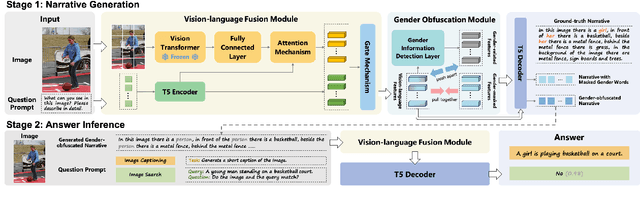
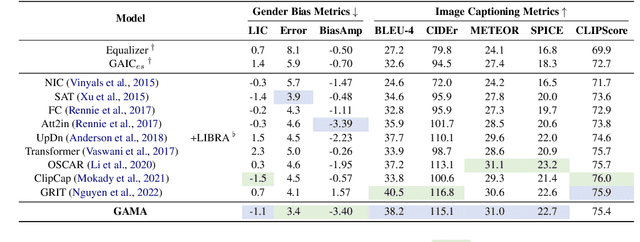
Gender bias in vision-language models (VLMs) can reinforce harmful stereotypes and discrimination. In this paper, we focus on mitigating gender bias towards vision-language tasks. We identify object hallucination as the essence of gender bias in VLMs. Existing VLMs tend to focus on salient or familiar attributes in images but ignore contextualized nuances. Moreover, most VLMs rely on the co-occurrence between specific objects and gender attributes to infer the ignored features, ultimately resulting in gender bias. We propose GAMA, a task-agnostic generation framework to mitigate gender bias. GAMA consists of two stages: narrative generation and answer inference. During narrative generation, GAMA yields all-sided but gender-obfuscated narratives, which prevents premature concentration on localized image features, especially gender attributes. During answer inference, GAMA integrates the image, generated narrative, and a task-specific question prompt to infer answers for different vision-language tasks. This approach allows the model to rethink gender attributes and answers. We conduct extensive experiments on GAMA, demonstrating its debiasing and generalization ability.