 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Answer Similarity for Evaluating Question Answering Models
Aug 13, 2021



The evaluation of question answering models compares ground-truth annotations with model predictions. However, as of today, this comparison is mostly lexical-based and therefore misses out on answers that have no lexical overlap but are still semantically similar, thus treating correct answers as false. This underestimation of the true performance of models hinders user acceptance in applications and complicates a fair comparison of different models. Therefore, there is a need for an evaluation metric that is based on semantics instead of pure string similarity. In this short paper, we present SAS, a cross-encoder-based metric for the estimation of semantic answer similarity, and compare it to seven existing metrics. To this end, we create an English and a German three-way annotated evaluation dataset containing pairs of answers along with human judgment of their semantic similarity, which we release along with an implementation of the SAS metric and the experiments. We find that semantic similarity metrics based on recent transformer models correlate much better with human judgment than traditional lexical similarity metrics on our two newly created datasets and one dataset from related work.
Multi-modal Retrieval of Tables and Texts Using Tri-encoder Models
Aug 09, 2021



Open-domain extractive question answering works well on textual data by first retrieving candidate texts and then extracting the answer from those candidates. However, some questions cannot be answered by text alone but require information stored in tables. In this paper, we present an approach for retrieving both texts and tables relevant to a question by jointly encoding texts, tables and questions into a single vector space. To this end, we create a new multi-modal dataset based on text and table datasets from related work and compare the retrieval performance of different encoding schemata. We find that dense vector embeddings of transformer models outperform sparse embeddings on four out of six evaluation datasets. Comparing different dense embedding models, tri-encoders, with one encoder for each question, text and table, increase retrieval performance compared to bi-encoders with one encoder for the question and one for both text and tables. We release the newly created multi-modal dataset to the community so that it can be used for training and evaluation.
GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval
Apr 26, 2021



A major challenge of research on non-English machine reading for question answering (QA) is the lack of annotated datasets. In this paper, we present GermanQuAD, a dataset of 13,722 extractive question/answer pairs. To improve the reproducibility of the dataset creation approach and foster QA research on other languages, we summarize lessons learned and evaluate reformulation of question/answer pairs as a way to speed up the annotation process. An extractive QA model trained on GermanQuAD significantly outperforms multilingual models and also shows that machine-translated training data cannot fully substitute hand-annotated training data in the target language. Finally, we demonstrate the wide range of applications of GermanQuAD by adapting it to GermanDPR, a training dataset for dense passage retrieval (DPR), and train and evaluate the first non-English DPR model.
German's Next Language Model
Oct 30, 2020
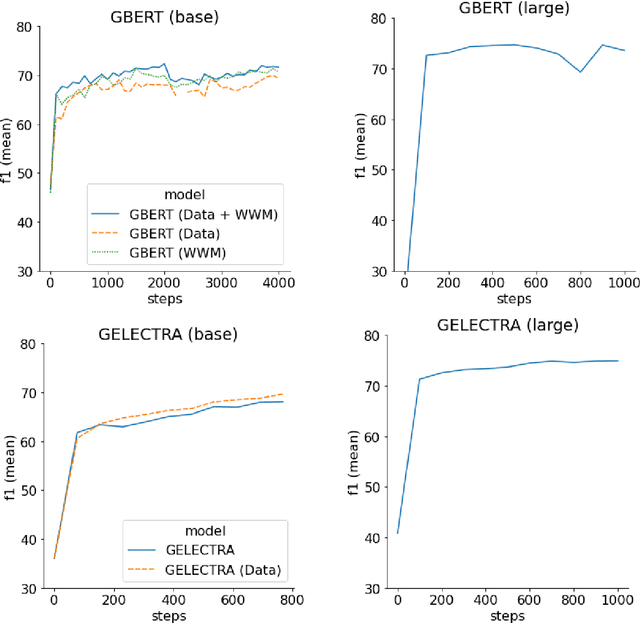
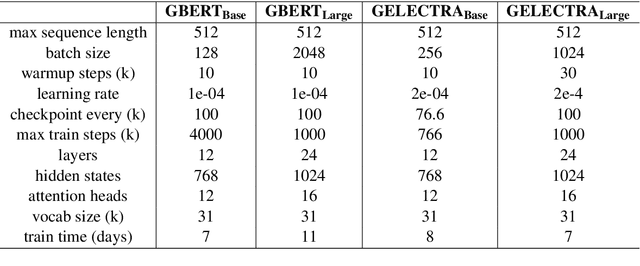

In this work we present the experiments which lead to the creation of our BERT and ELECTRA based German language models, GBERT and GELECTRA. By varying the input training data, model size, and the presence of Whole Word Masking (WWM) we were able to attain SoTA performance across a set of document classification and named entity recognition (NER) tasks for both models of base and large size. We adopt an evaluation driven approach in training these models and our results indicate that both adding more data and utilizing WWM improve model performance. By benchmarking against existing German models, we show that these models are the best German models to date. Our trained models will be made publicly available to the research community.