 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained LLMs Learn Multiple Types of Uncertainty
May 27, 2025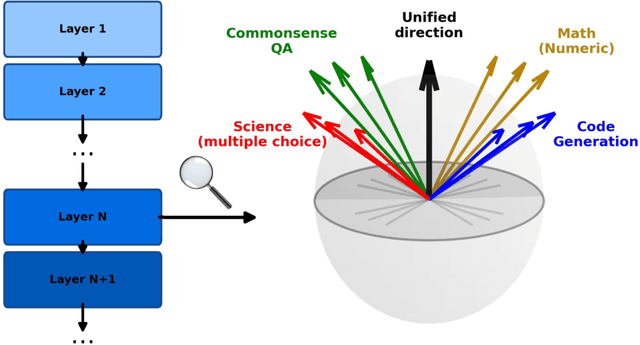

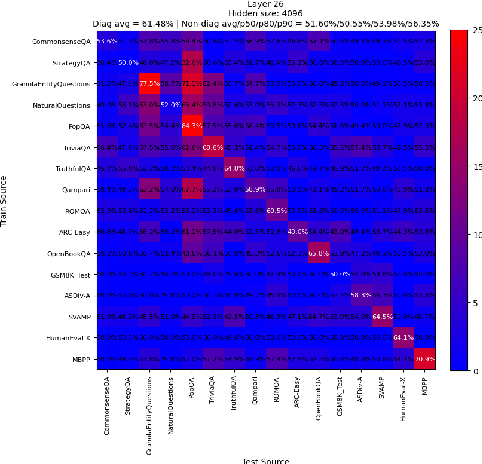
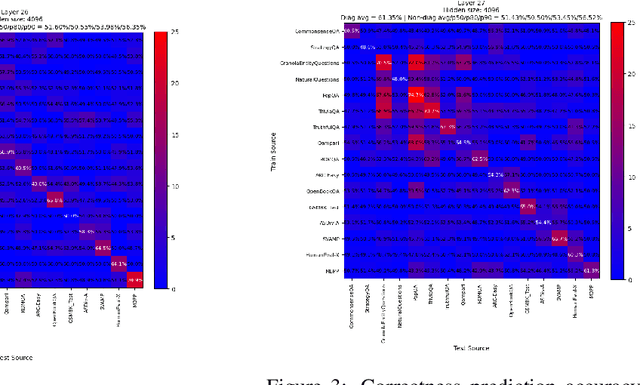
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we study how well LLMs capture uncertainty, without explicitly being trained for that. We show that, if considering uncertainty as a linear concept in the model's latent space, it might indeed be captured, even after only pretraining. We further show that, though unintuitive, LLMs appear to capture several different types of uncertainty, each of which can be useful to predict the correctness for a specific task or benchmark. Furthermore, we provide in-depth results such as demonstrating a correlation between our correction prediction and the model's ability to abstain from misinformation using words, and the lack of impact of model scaling for capturing uncertainty. Finally, we claim that unifying the uncertainty types as a single one using instruction-tuning or [IDK]-token tuning is helpful for the model in terms of correctness prediction.
InFact: Informativeness Alignment for Improved LLM Factuality
May 26, 2025Factual completeness is a general term that captures how detailed and informative a factually correct text is. For instance, the factual sentence ``Barack Obama was born in the United States'' is factually correct, though less informative than the factual sentence ``Barack Obama was born in Honolulu, Hawaii, United States''. Despite the known fact that LLMs tend to hallucinate and generate factually incorrect text, they might also tend to choose to generate factual text that is indeed factually correct and yet less informative than other, more informative choices. In this work, we tackle this problem by proposing an informativeness alignment mechanism. This mechanism takes advantage of recent factual benchmarks to propose an informativeness alignment objective. This objective prioritizes answers that are both correct and informative. A key finding of our work is that when training a model to maximize this objective or optimize its preference, we can improve not just informativeness but also factuality.
I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token
Dec 09, 2024![Figure 1 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Table2-1.png&w=640&q=75)
![Figure 4 for I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F2259fda68905242c4b3e928a7b8751c8cd99956c%2F6-Figure2-1.png&w=640&q=75)
Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations. We add a special [IDK] ("I don't know") token to the model's vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions. This approach allows the model to express uncertainty in its output explicitly. We evaluate our proposed method across multiple model architectures and factual downstream tasks. We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.
Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024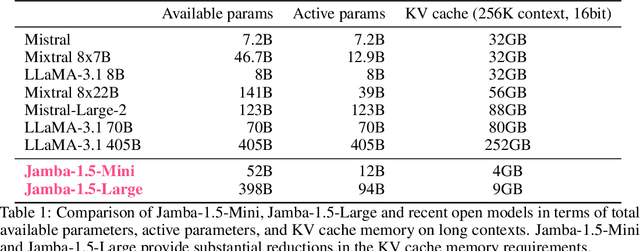
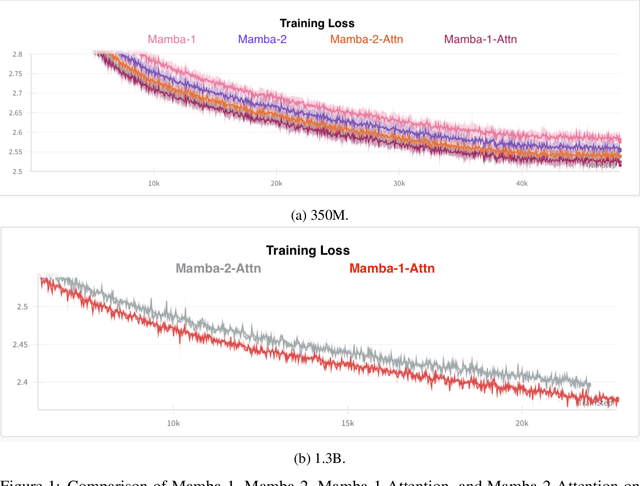
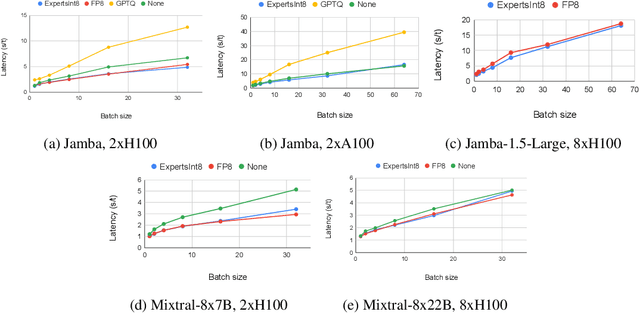
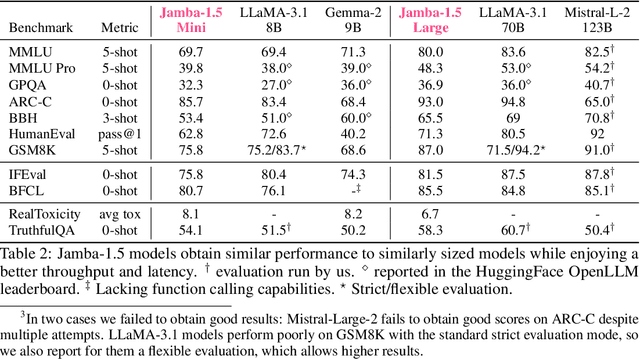
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Evaluating the Ripple Effects of Knowledge Editing in Language Models
Jul 24, 2023Modern language models capture a large body of factual knowledge. However, some facts can be incorrectly induced or become obsolete over time, resulting in factually incorrect generations. This has led to the development of various editing methods that allow updating facts encoded by the model. Evaluation of these methods has primarily focused on testing whether an individual fact has been successfully injected, and if similar predictions for other subjects have not changed. Here we argue that such evaluation is limited, since injecting one fact (e.g. ``Jack Depp is the son of Johnny Depp'') introduces a ``ripple effect'' in the form of additional facts that the model needs to update (e.g.``Jack Depp is the sibling of Lily-Rose Depp''). To address this issue, we propose a novel set of evaluation criteria that consider the implications of an edit on related facts. Using these criteria, we then construct \ripple{}, a diagnostic benchmark of 5K factual edits, capturing a variety of types of ripple effects. We evaluate prominent editing methods on \ripple{}, showing that current methods fail to introduce consistent changes in the model's knowledge. In addition, we find that a simple in-context editing baseline obtains the best scores on our benchmark, suggesting a promising research direction for model editing.
LM vs LM: Detecting Factual Errors via Cross Examination
May 22, 2023A prominent weakness of modern language models (LMs) is their tendency to generate factually incorrect text, which hinders their usability. A natural question is whether such factual errors can be detected automatically. Inspired by truth-seeking mechanisms in law, we propose a factuality evaluation framework for LMs that is based on cross-examination. Our key idea is that an incorrect claim is likely to result in inconsistency with other claims that the model generates. To discover such inconsistencies, we facilitate a multi-turn interaction between the LM that generated the claim and another LM (acting as an examiner) which introduces questions to discover inconsistencies. We empirically evaluate our method on factual claims made by multiple recent LMs on four benchmarks, finding that it outperforms existing methods and baselines, often by a large gap. Our results demonstrate the potential of using interacting LMs for capturing factual errors.
Crawling the Internal Knowledge-Base of Language Models
Jan 30, 2023Language models are trained on large volumes of text, and as a result their parameters might contain a significant body of factual knowledge. Any downstream task performed by these models implicitly builds on these facts, and thus it is highly desirable to have means for representing this body of knowledge in an interpretable way. However, there is currently no mechanism for such a representation. Here, we propose to address this goal by extracting a knowledge-graph of facts from a given language model. We describe a procedure for ``crawling'' the internal knowledge-base of a language model. Specifically, given a seed entity, we expand a knowledge-graph around it. The crawling procedure is decomposed into sub-tasks, realized through specially designed prompts that control for both precision (i.e., that no wrong facts are generated) and recall (i.e., the number of facts generated). We evaluate our approach on graphs crawled starting from dozens of seed entities, and show it yields high precision graphs (82-92%), while emitting a reasonable number of facts per entity.