 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Set-equivariant Functions with SWARM Mappings
Paper and Code
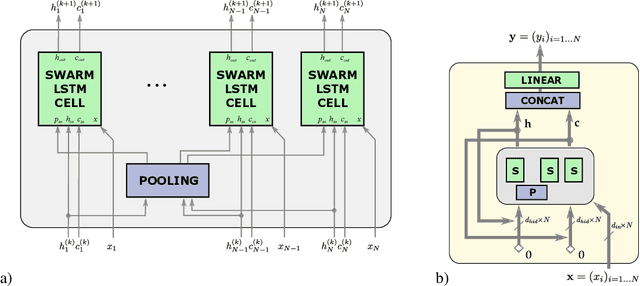
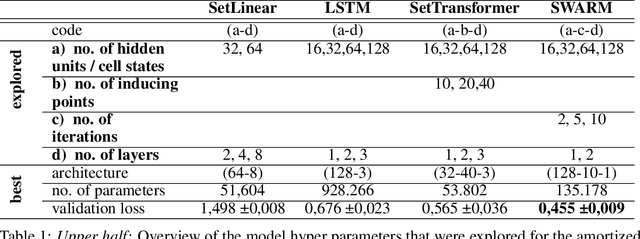


In this work we propose a new neural network architecture that efficiently implements and learns general purpose set-equivariant functions. Such a function $f$ maps a set of entities $x=\left\{ x_{1},\ldots,x_{n}\right\} $ from one domain to a set of same cardinality $y=f\left(x\right)=\left\{ y_{1},\ldots,y_{n}\right\} $ in another domain regardless of the ordering of the entities. The architecture is based on a gated recurrent network which is iteratively applied to all entities individually and at the same time syncs with the progression of the whole population. In reminiscence to this pattern, which can be frequently observable in nature, we call our approach SWARM mapping. Set-equivariant and generally permutation invariant functions are important building blocks for many state of the art machine learning approaches. Even in application where the permutation invariance is not of primary interest, as to be seen in the recent success of attention based transformer models (Vaswani et. al. 2017). Accordingly, we demonstrate the power and usefulness of SWARM mappings in different applications. We compare the performance of our approach with another recently proposed set-equivariant function, the SetTransformer (Lee et.al. 2018) and we demonstrate that transformer solely based on SWARM layers gives state of the art results.