 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational valency lexica and Homeric formularity
Paper and Code
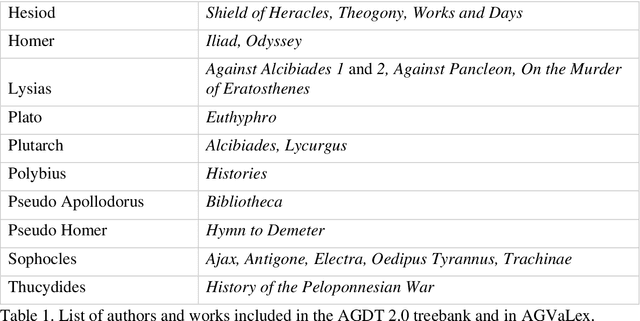


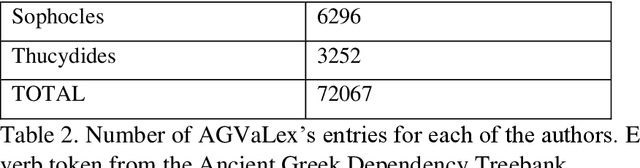
Distributional semantics, the quantitative study of meaning variation and change through corpus collocations, is currently one of the most productive research areas in computational linguistics. The wider availability of big data and of reproducible algorithms for analysis has boosted its application to living languages in recent years. But can we use distributional semantics to study a language with such a limited corpus as ancient Greek? And can this approach tell us something about such vexed questions in classical studies as the language and composition of the Homeric poems? Our paper will compare the semantic flexibility of formulae involving transitive verbs in archaic Greek epic to similar verb phrases in a non-formulaic corpus, in order to detect unique patterns of variation in formulae. To address this, we present AGVaLex, a computational valency lexicon for ancient Greek automatically extracted from the Ancient Greek Dependency Treebank. The lexicon contains quantitative corpus-driven morphological, syntactic and lexical information about verbs and their arguments, such as objects, subjects, and prepositional phrases, and has a wide range of applications for the study of the language of ancient Greek authors.