 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Story Frames: Contextual Reasoning about Narrative Intent and Reception
Dec 17, 2025Reading stories evokes rich interpretive, affective, and evaluative responses, such as inferences about narrative intent or judgments about characters. Yet, computational models of reader response are limited, preventing nuanced analyses. To address this gap, we introduce SocialStoryFrames, a formalism for distilling plausible inferences about reader response, such as perceived author intent, explanatory and predictive reasoning, affective responses, and value judgments, using conversational context and a taxonomy grounded in narrative theory, linguistic pragmatics, and psychology. We develop two models, SSF-Generator and SSF-Classifier, validated through human surveys (N=382 participants) and expert annotations, respectively. We conduct pilot analyses to showcase the utility of the formalism for studying storytelling at scale. Specifically, applying our models to SSF-Corpus, a curated dataset of 6,140 social media stories from diverse contexts, we characterize the frequency and interdependence of storytelling intents, and we compare and contrast narrative practices (and their diversity) across communities. By linking fine-grained, context-sensitive modeling with a generic taxonomy of reader responses, SocialStoryFrames enable new research into storytelling in online communities.
What Are You Anxious About? Examining Subjects of Anxiety during the COVID-19 Pandemic
Sep 27, 2022
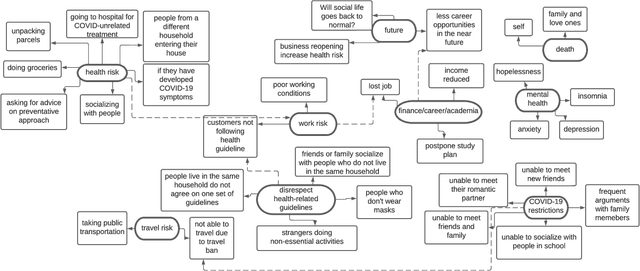


COVID-19 poses disproportionate mental health consequences to the public during different phases of the pandemic. We use a computational approach to capture the specific aspects that trigger an online community's anxiety about the pandemic and investigate how these aspects change over time. First, we identified nine subjects of anxiety (SOAs) in a sample of Reddit posts ($N$=86) from r/COVID19\_support using thematic analysis. Then, we quantified Reddit users' anxiety by training algorithms on a manually annotated sample ($N$=793) to automatically label the SOAs in a larger chronological sample ($N$=6,535). The nine SOAs align with items in various recently developed pandemic anxiety measurement scales. We observed that Reddit users' concerns about health risks remained high in the first eight months of the pandemic. These concerns diminished dramatically despite the surge of cases occurring later. In general, users' language disclosing the SOAs became less intense as the pandemic progressed. However, worries about mental health and the future increased steadily throughout the period covered in this study. People also tended to use more intense language to describe mental health concerns than health risks or death concerns. Our results suggest that this online group's mental health condition does not necessarily improve despite COVID-19 gradually weakening as a health threat due to appropriate countermeasures. Our system lays the groundwork for population health and epidemiology scholars to examine aspects that provoke pandemic anxiety in a timely fashion.
Don't Take it Personally: Analyzing Gender and Age Differences in Ratings of Online Humor
Aug 23, 2022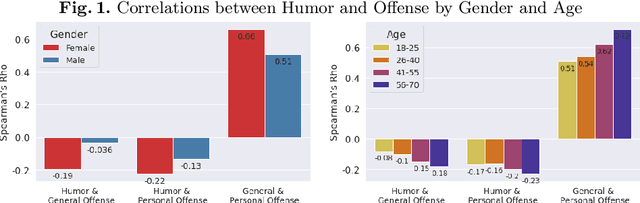

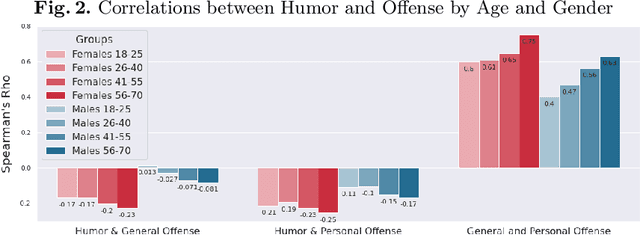

Computational humor detection systems rarely model the subjectivity of humor responses, or consider alternative reactions to humor - namely offense. We analyzed a large dataset of humor and offense ratings by male and female annotators of different age groups. We find that women link these two concepts more strongly than men, and they tend to give lower humor ratings and higher offense scores. We also find that the correlation between humor and offense increases with age. Although there were no gender or age differences in humor detection, women and older annotators signalled that they did not understand joke texts more often than men. We discuss implications for computational humor detection and downstream tasks.
Analyzing Temporal Relationships between Trending Terms on Twitter and Urban Dictionary Activity
May 18, 2020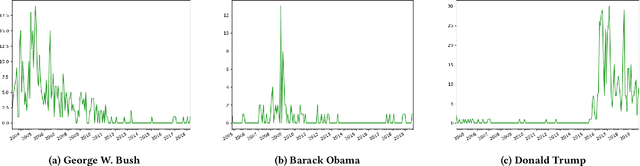
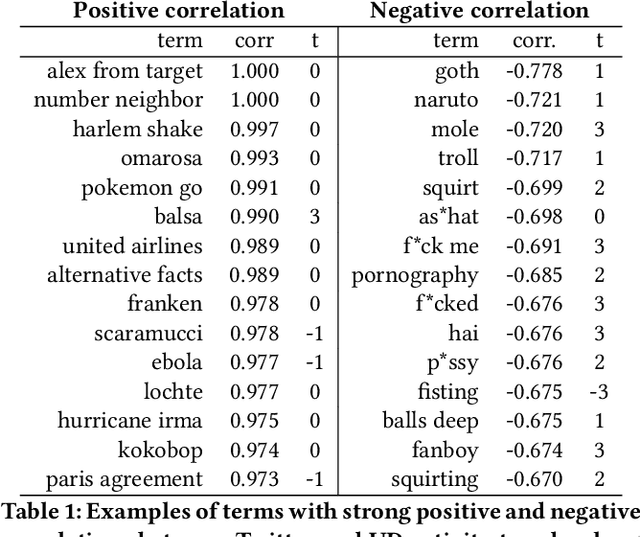

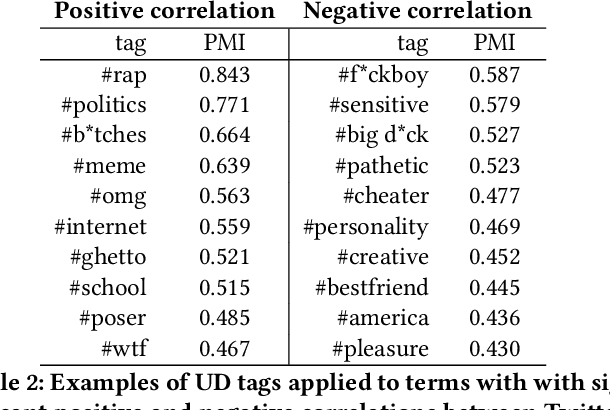
As an online, crowd-sourced, open English-language slang dictionary, the Urban Dictionary platform contains a wealth of opinions, jokes, and definitions of terms, phrases, acronyms, and more. However, it is unclear exactly how activity on this platform relates to larger conversations happening elsewhere on the web, such as discussions on larger, more popular social media platforms. In this research, we study the temporal activity trends on Urban Dictionary and provide the first analysis of how this activity relates to content being discussed on a major social network: Twitter. By collecting the whole of Urban Dictionary, as well as a large sample of tweets over seven years, we explore the connections between the words and phrases that are defined and searched for on Urban Dictionary and the content that is talked about on Twitter. Through a series of cross-correlation calculations, we identify cases in which Urban Dictionary activity closely reflects the larger conversation happening on Twitter. Then, we analyze the types of terms that have a stronger connection to discussions on Twitter, finding that Urban Dictionary activity that is positively correlated with Twitter is centered around terms related to memes, popular public figures, and offline events. Finally, We explore the relationship between periods of time when terms are trending on Twitter and the corresponding activity on Urban Dictionary, revealing that new definitions are more likely to be added to Urban Dictionary for terms that are currently trending on Twitter.
Predicting Human Activities from User-Generated Content
Jul 19, 2019
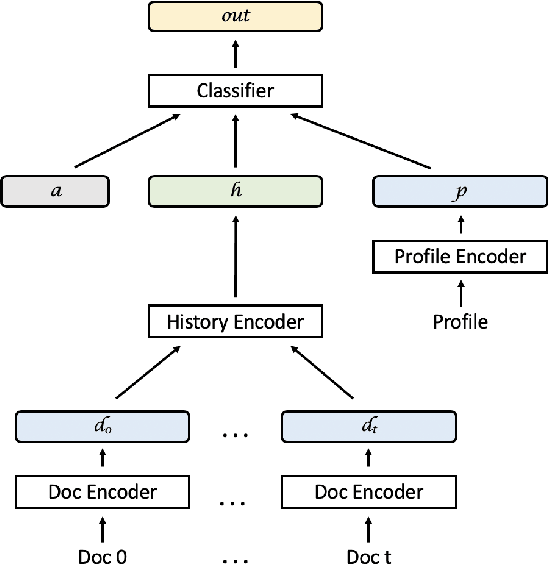
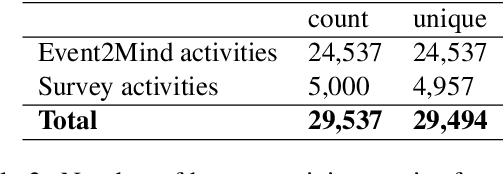

The activities we do are linked to our interests, personality, political preferences, and decisions we make about the future. In this paper, we explore the task of predicting human activities from user-generated content. We collect a dataset containing instances of social media users writing about a range of everyday activities. We then use a state-of-the-art sentence embedding framework tailored to recognize the semantics of human activities and perform an automatic clustering of these activities. We train a neural network model to make predictions about which clusters contain activities that were performed by a given user based on the text of their previous posts and self-description. Additionally, we explore the degree to which incorporating inferred user traits into our model helps with this prediction task.
Direct Network Transfer: Transfer Learning of Sentence Embeddings for Semantic Similarity
Oct 31, 2018
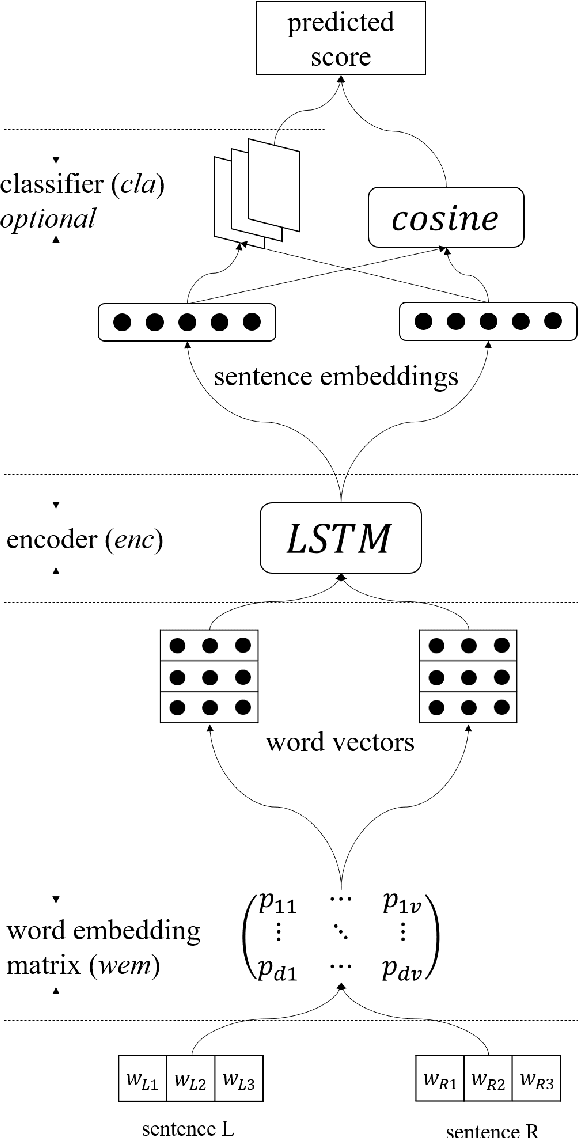
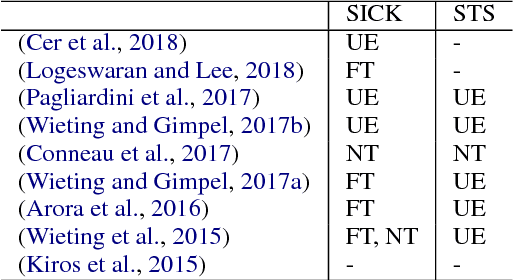
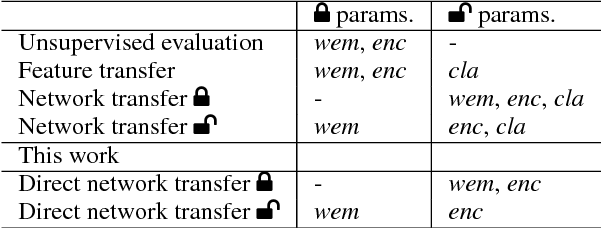
Sentence encoders, which produce sentence embeddings using neural networks, are typically evaluated by how well they transfer to downstream tasks. This includes semantic similarity, an important task in natural language understanding. Although there has been much work dedicated to building sentence encoders, the accompanying transfer learning techniques have received relatively little attention. In this paper, we propose a transfer learning setting specialized for semantic similarity, which we refer to as direct network transfer. Through experiments on several standard text similarity datasets, we show that applying direct network transfer to existing encoders can lead to state-of-the-art performance. Additionally, we compare several approaches to transfer sentence encoders to semantic similarity tasks, showing that the choice of transfer learning setting greatly affects the performance in many cases, and differs by encoder and dataset.
Multi-Label Transfer Learning for Semantic Similarity
May 31, 2018

The semantic relations between two short texts can be defined in multiple ways. Yet, all the systems to date designed to capture such relations target one relation at a time. We propose a novel multi-label transfer learning approach to jointly learn the information provided by the multiple annotations, rather than treating them as separate tasks. Not only does this approach outperform the traditional multi-task learning approach, it also achieves state-of-the-art performance on the SICK Entailment task and all but one dimensions of the Human Activity Phrase dataset.