 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters
Nov 26, 2023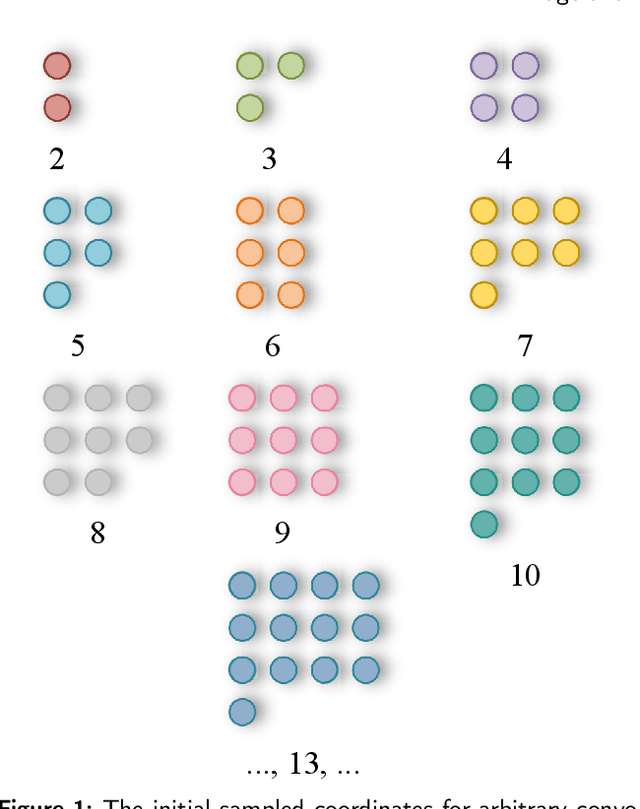



Neural networks based on convolutional operations have achieved remarkable results in the field of deep learning, but there are two inherent flaws in standard convolutional operations. On the one hand, the convolution operation be confined to a local window and cannot capture information from other locations, and its sampled shapes is fixed. On the other hand, the size of the convolutional kernel is fixed to k $\times$ k, which is a fixed square shape, and the number of parameters tends to grow squarely with size. It is obvious that the shape and size of targets are various in different datasets and at different locations. Convolutional kernels with fixed sample shapes and squares do not adapt well to changing targets. In response to the above questions, the Alterable Kernel Convolution (AKConv) is explored in this work, which gives the convolution kernel an arbitrary number of parameters and arbitrary sampled shapes to provide richer options for the trade-off between network overhead and performance. In AKConv, we define initial positions for convolutional kernels of arbitrary size by means of a new coordinate generation algorithm. To adapt to changes for targets, we introduce offsets to adjust the shape of the samples at each position. Moreover, we explore the effect of the neural network by using the AKConv with the same size and different initial sampled shapes. AKConv completes the process of efficient feature extraction by irregular convolutional operations and brings more exploration options for convolutional sampling shapes. Object detection experiments on representative datasets COCO2017, VOC 7+12 and VisDrone-DET2021 fully demonstrate the advantages of AKConv. AKConv can be used as a plug-and-play convolutional operation to replace convolutional operations to improve network performance. The code for the relevant tasks can be found at https://github.com/CV-ZhangXin/AKConv.
RFAConv: Innovating Spatial Attention and Standard Convolutional Operation
Apr 18, 2023



Spatial attention has been widely used to improve the performance of convolutional neural networks. However, it has certain limitations. In this paper, we propose a new perspective on the effectiveness of spatial attention, which is that the spatial attention mechanism essentially solves the problem of convolutional kernel parameter sharing. However, the information contained in the attention map generated by spatial attention is not sufficient for large-size convolutional kernels. Therefore, we propose a novel attention mechanism called Receptive-Field Attention (RFA). Existing spatial attention, such as Convolutional Block Attention Module (CBAM) and Coordinated Attention (CA) focus only on spatial features, which does not fully address the problem of convolutional kernel parameter sharing. In contrast, RFA not only focuses on the receptive-field spatial feature but also provides effective attention weights for large-size convolutional kernels. The Receptive-Field Attention convolutional operation (RFAConv), developed by RFA, represents a new approach to replace the standard convolution operation. It offers nearly negligible increment of computational cost and parameters, while significantly improving network performance. We conducted a series of experiments on ImageNet-1k, COCO, and VOC datasets to demonstrate the superiority of our approach. Of particular importance, we believe that it is time to shift focus from spatial features to receptive-field spatial features for current spatial attention mechanisms. In this way, we can further improve network performance and achieve even better results. The code and pre-trained models for the relevant tasks can be found at https://github.com/Liuchen1997/RFAConv.