 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuild a SRE Challenge System: Lessons from VoxSRC 2022 and CNSRC 2022
Nov 02, 2022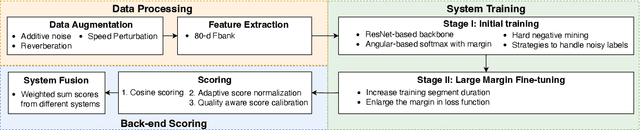

Different speaker recognition challenges have been held to assess the speaker verification system in the wild and probe the performance limit. Voxceleb Speaker Recognition Challenge (VoxSRC), based on the voxceleb, is the most popular. Besides, another challenge called CN-Celeb Speaker Recognition Challenge (CNSRC) is also held this year, which is based on the Chinese celebrity multi-genre dataset CN-Celeb. This year, our team participated in both speaker verification closed tracks in CNSRC 2022 and VoxSRC 2022, and achieved the 1st place and 3rd place respectively. In most system reports, the authors usually only provide a description of their systems but lack an effective analysis of their methods. In this paper, we will outline how to build a strong speaker verification challenge system and give a detailed analysis of each method compared with some other popular technical means.
SJTU-AISPEECH System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022
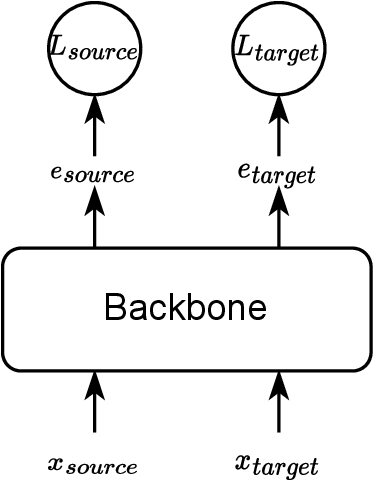
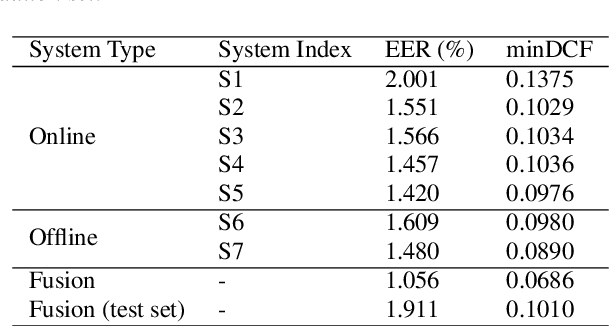

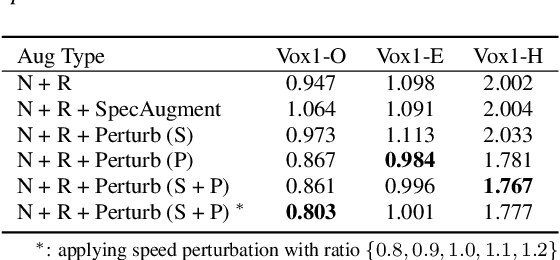
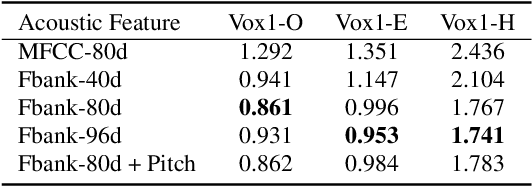
This report describes the SJTU-AISPEECH system for the Voxceleb Speaker Recognition Challenge 2022. For track1, we implemented two kinds of systems, the online system and the offline system. Different ResNet-based backbones and loss functions are explored. Our final fusion system achieved 3rd place in track1. For track3, we implemented statistic adaptation and jointly training based domain adaptation. In the jointly training based domain adaptation, we jointly trained the source and target domain dataset with different training objectives to do the domain adaptation. We explored two different training objectives for target domain data, self-supervised learning based angular proto-typical loss and semi-supervised learning based classification loss with estimated pseudo labels. Besides, we used the dynamic loss-gate and label correction (DLG-LC) strategy to improve the quality of pseudo labels when the target domain objective is a classification loss. Our final fusion system achieved 4th place (very close to 3rd place, relatively less than 1%) in track3.
AISPEECH-SJTU accent identification system for the Accented English Speech Recognition Challenge
Feb 19, 2021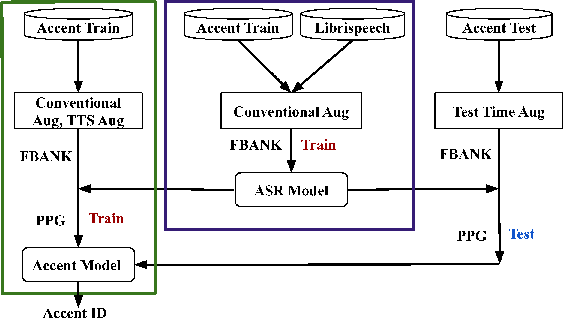
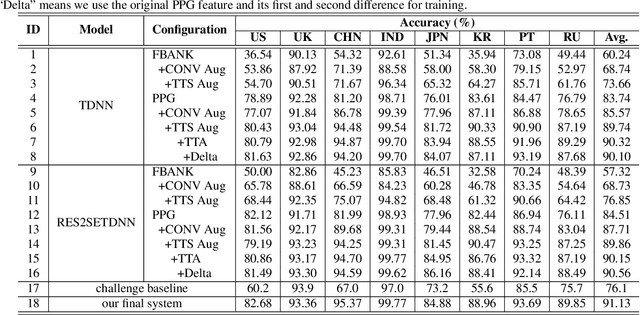
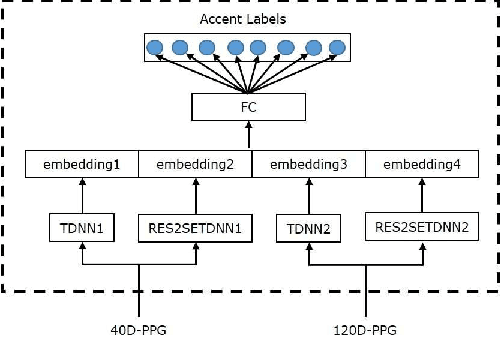
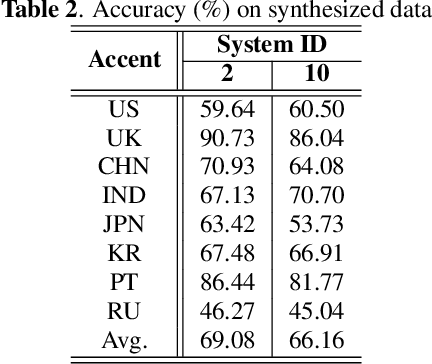
This paper describes the AISpeech-SJTU system for the accent identification track of the Interspeech-2020 Accented English Speech Recognition Challenge. In this challenge track, only 160-hour accented English data collected from 8 countries and the auxiliary Librispeech dataset are provided for training. To build an accurate and robust accent identification system, we explore the whole system pipeline in detail. First, we introduce the ASR based phone posteriorgram (PPG) feature to accent identification and verify its efficacy. Then, a novel TTS based approach is carefully designed to augment the very limited accent training data for the first time. Finally, we propose the test time augmentation and embedding fusion schemes to further improve the system performance. Our final system is ranked first in the challenge and outperforms all the other participants by a large margin. The submitted system achieves 83.63\% average accuracy on the challenge evaluation data, ahead of the others by more than 10\% in absolute terms.
Unit selection synthesis based data augmentation for fixed phrase speaker verification
Feb 19, 2021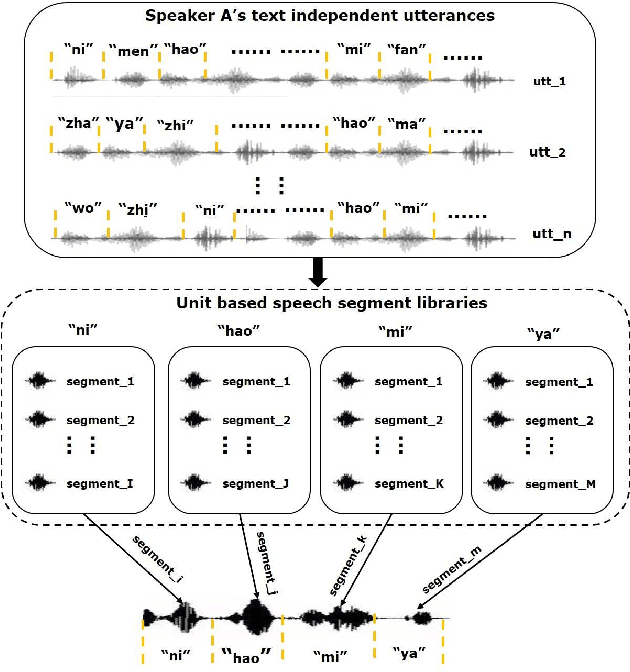
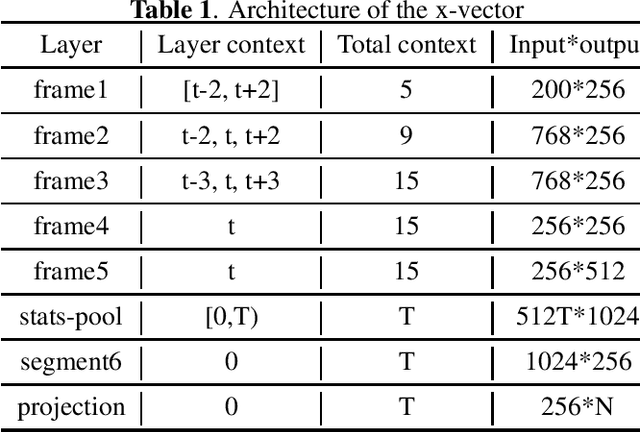
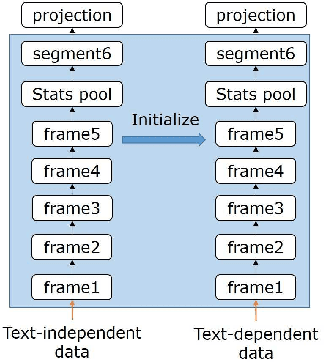
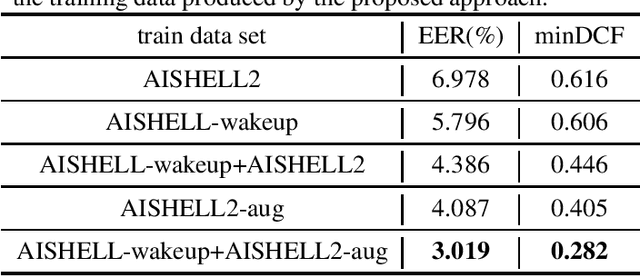
Data augmentation is commonly used to help build a robust speaker verification system, especially in limited-resource case. However, conventional data augmentation methods usually focus on the diversity of acoustic environment, leaving the lexicon variation neglected. For text dependent speaker verification tasks, it's well-known that preparing training data with the target transcript is the most effectual approach to build a well-performing system, however collecting such data is time-consuming and expensive. In this work, we propose a unit selection synthesis based data augmentation method to leverage the abundant text-independent data resources. In this approach text-independent speeches of each speaker are firstly broke up to speech segments each contains one phone unit. Then segments that contain phonetics in the target transcript are selected to produce a speech with the target transcript by concatenating them in turn. Experiments are carried out on the AISHELL Speaker Verification Challenge 2019 database, the results and analysis shows that our proposed method can boost the system performance significantly.
Margin Matters: Towards More Discriminative Deep Neural Network Embeddings for Speaker Recognition
Jun 18, 2019
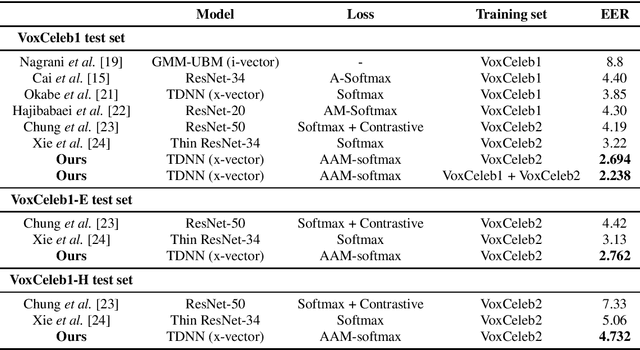
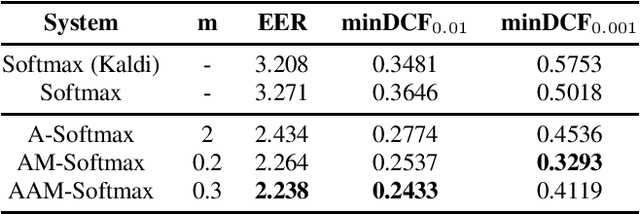
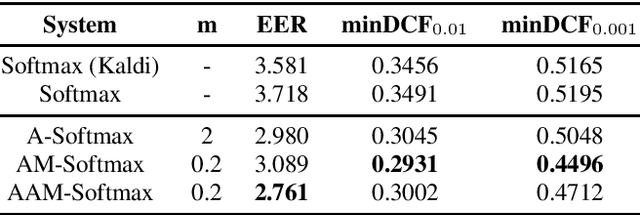
Recently, speaker embeddings extracted from a speaker discriminative deep neural network (DNN) yield better performance than the conventional methods such as i-vector. In most cases, the DNN speaker classifier is trained using cross entropy loss with softmax. However, this kind of loss function does not explicitly encourage inter-class separability and intra-class compactness. As a result, the embeddings are not optimal for speaker recognition tasks. In this paper, to address this issue, three different margin based losses which not only separate classes but also demand a fixed margin between classes are introduced to deep speaker embedding learning. It could be demonstrated that the margin is the key to obtain more discriminative speaker embeddings. Experiments are conducted on two public text independent tasks: VoxCeleb1 and Speaker in The Wild (SITW). The proposed approach can achieve the state-of-the-art performance, with 25% ~ 30% equal error rate (EER) reduction on both tasks when compared to strong baselines using cross entropy loss with softmax, obtaining 2.238% EER on VoxCeleb1 test set and 2.761% EER on SITW core-core test set, respectively.
ICFVR 2017: 3rd International Competition on Finger Vein Recognition
Jan 04, 2018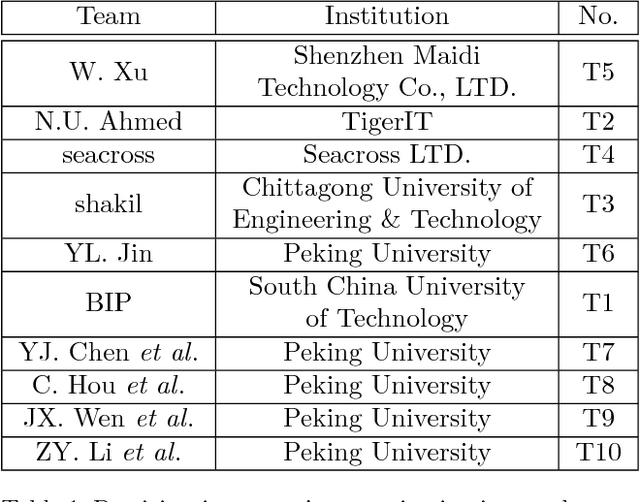
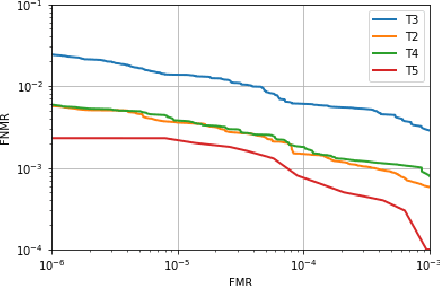
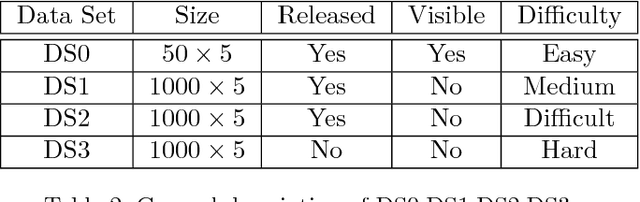
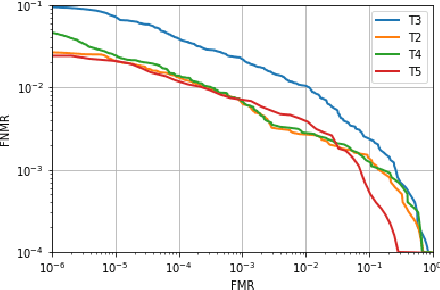
In recent years, finger vein recognition has become an important sub-field in biometrics and been applied to real-world applications. The development of finger vein recognition algorithms heavily depends on large-scale real-world data sets. In order to motivate research on finger vein recognition, we released the largest finger vein data set up to now and hold finger vein recognition competitions based on our data set every year. In 2017, International Competition on Finger Vein Recognition(ICFVR) is held jointly with IJCB 2017. 11 teams registered and 10 of them joined the final evaluation. The winner of this year dramatically improved the EER from 2.64% to 0.483% compared to the winner of last year. In this paper, we introduce the process and results of ICFVR 2017 and give insights on development of state-of-art finger vein recognition algorithms.
A Fusion Method Based on Decision Reliability Ratio for Finger Vein Verification
Dec 17, 2016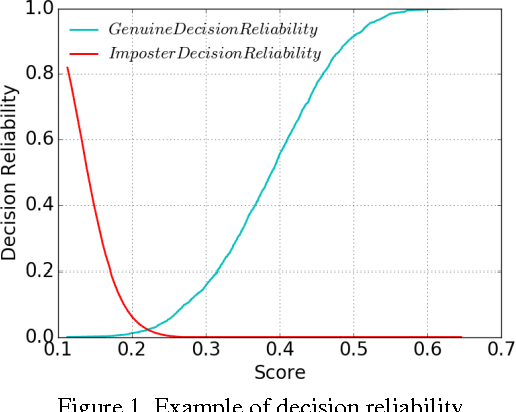

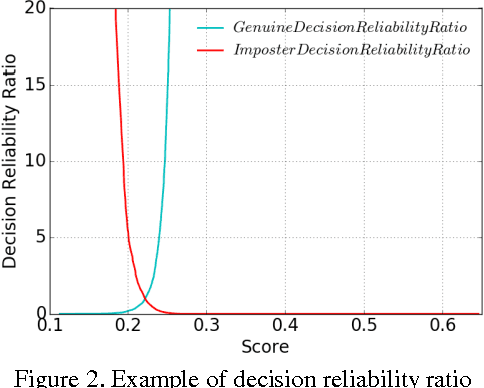
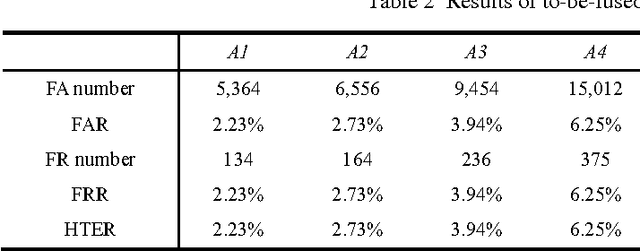
Finger vein verification has developed a lot since its first proposal, but there is still not a perfect algorithm. It is proved that algorithms with the same overall accuracy may have different misclassified patterns. We could make use of this complementation to fuse individual algorithms together for more precise result. According to our observation, algorithm has different confidence on its decisions but it is seldom considered in fusion methods. Our work is first to define decision reliability ratio to quantify this confidence, and then propose the Maximum Decision Reliability Ratio (MDRR) fusion method incorporating Weighted Voting. Experiment conducted on a data set of 1000 fingers and 5 images per finger proves the effectiveness of the method. The classifier obtained by MDRR method gets an accuracy of 99.42% while the maximum accuracy of the original individual classifiers is 97.77%. The experiment results also show the MDRR outperforms the traditional fusion methods as Voting, Weighted Voting, Sum and Weighted Sum.