 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Token Left Behind: Efficient Vision Transformer via Dynamic Token Idling
Paper and Code
Oct 09, 2023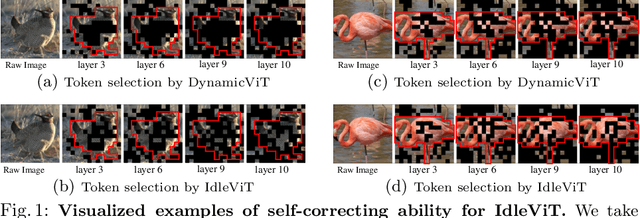
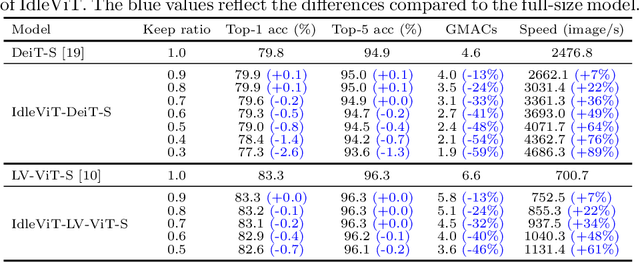
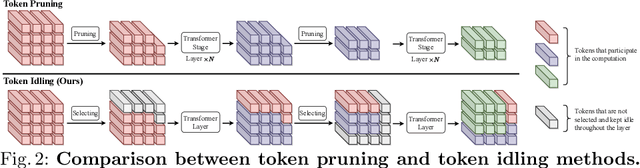

Vision Transformers (ViTs) have demonstrated outstanding performance in computer vision tasks, yet their high computational complexity prevents their deployment in computing resource-constrained environments. Various token pruning techniques have been introduced to alleviate the high computational burden of ViTs by dynamically dropping image tokens. However, some undesirable pruning at early stages may result in permanent loss of image information in subsequent layers, consequently hindering model performance. To address this problem, we propose IdleViT, a dynamic token-idle-based method that achieves an excellent trade-off between performance and efficiency. Specifically, in each layer, IdleViT selects a subset of the image tokens to participate in computations while keeping the rest of the tokens idle and directly passing them to this layer's output. By allowing the idle tokens to be re-selected in the following layers, IdleViT mitigates the negative impact of improper pruning in the early stages. Furthermore, inspired by the normalized graph cut, we devise a token cut loss on the attention map as regularization to improve IdleViT's token selection ability. Our method is simple yet effective and can be extended to pyramid ViTs since no token is completely dropped. Extensive experimental results on various ViT architectures have shown that IdleViT can diminish the complexity of pretrained ViTs by up to 33\% with no more than 0.2\% accuracy decrease on ImageNet, after finetuning for only 30 epochs. Notably, when the keep ratio is 0.5, IdleViT outperforms the state-of-the-art EViT on DeiT-S by 0.5\% higher accuracy and even faster inference speed. The source code is available in the supplementary material.