 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Sample Assignment for Semantically Coherent Out-of-Distribution Detection
Dec 15, 2025Semantically coherent out-of-distribution detection (SCOOD) is a recently proposed realistic OOD detection setting: given labeled in-distribution (ID) data and mixed in-distribution and out-of-distribution unlabeled data as the training data, SCOOD aims to enable the trained model to accurately identify OOD samples in the testing data. Current SCOOD methods mainly adopt various clustering-based in-distribution sample filtering (IDF) strategies to select clean ID samples from unlabeled data, and take the remaining samples as auxiliary OOD data, which inevitably introduces a large number of noisy samples in training. To address the above issue, we propose a concise SCOOD framework based on predictive sample assignment (PSA). PSA includes a dual-threshold ternary sample assignment strategy based on the predictive energy score that can significantly improve the purity of the selected ID and OOD sample sets by assigning unconfident unlabeled data to an additional discard sample set, and a concept contrastive representation learning loss to further expand the distance between ID and OOD samples in the representation space to assist ID/OOD discrimination. In addition, we also introduce a retraining strategy to help the model fully fit the selected auxiliary ID/OOD samples. Experiments on two standard SCOOD benchmarks demonstrate that our approach outperforms the state-of-the-art methods by a significant margin.
Sharpness-aware Dynamic Anchor Selection for Generalized Category Discovery
Dec 15, 2025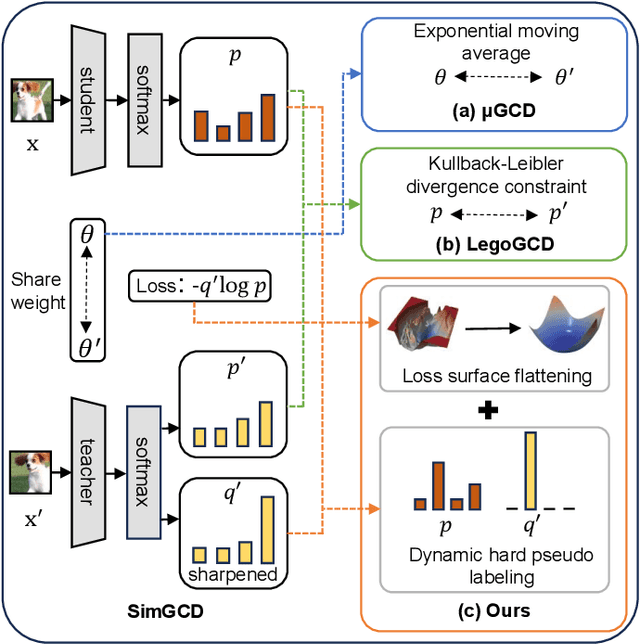
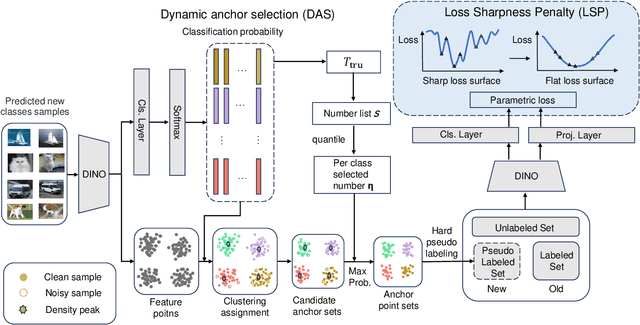
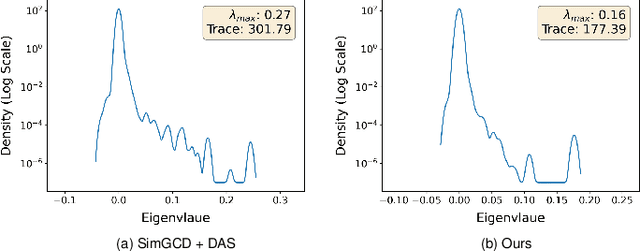
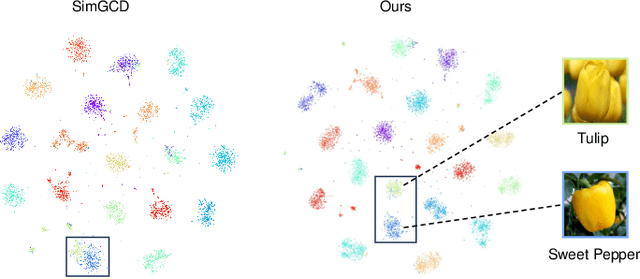
Generalized category discovery (GCD) is an important and challenging task in open-world learning. Specifically, given some labeled data of known classes, GCD aims to cluster unlabeled data that contain both known and unknown classes. Current GCD methods based on parametric classification adopt the DINO-like pseudo-labeling strategy, where the sharpened probability output of one view is used as supervision information for the other view. However, large pre-trained models have a preference for some specific visual patterns, resulting in encoding spurious correlation for unlabeled data and generating noisy pseudo-labels. To address this issue, we propose a novel method, which contains two modules: Loss Sharpness Penalty (LSP) and Dynamic Anchor Selection (DAS). LSP enhances the robustness of model parameters to small perturbations by minimizing the worst-case loss sharpness of the model, which suppressing the encoding of trivial features, thereby reducing overfitting of noise samples and improving the quality of pseudo-labels. Meanwhile, DAS selects representative samples for the unknown classes based on KNN density and class probability during the model training and assigns hard pseudo-labels to them, which not only alleviates the confidence difference between known and unknown classes but also enables the model to quickly learn more accurate feature distribution for the unknown classes, thus further improving the clustering accuracy. Extensive experiments demonstrate that the proposed method can effectively mitigate the noise of pseudo-labels, and achieve state-of-the-art results on multiple GCD benchmarks.
Learning Part Knowledge to Facilitate Category Understanding for Fine-Grained Generalized Category Discovery
Mar 21, 2025Generalized Category Discovery (GCD) aims to classify unlabeled data containing both seen and novel categories. Although existing methods perform well on generic datasets, they struggle in fine-grained scenarios. We attribute this difficulty to their reliance on contrastive learning over global image features to automatically capture discriminative cues, which fails to capture the subtle local differences essential for distinguishing fine-grained categories. Therefore, in this paper, we propose incorporating part knowledge to address fine-grained GCD, which introduces two key challenges: the absence of annotations for novel classes complicates the extraction of the part features, and global contrastive learning prioritizes holistic feature invariance, inadvertently suppressing discriminative local part patterns. To address these challenges, we propose PartGCD, including 1) Adaptive Part Decomposition, which automatically extracts class-specific semantic parts via Gaussian Mixture Models, and 2) Part Discrepancy Regularization, enforcing explicit separation between part features to amplify fine-grained local part distinctions. Experiments demonstrate state-of-the-art performance across multiple fine-grained benchmarks while maintaining competitiveness on generic datasets, validating the effectiveness and robustness of our approach.
GET: Unlocking the Multi-modal Potential of CLIP for Generalized Category Discovery
Mar 15, 2024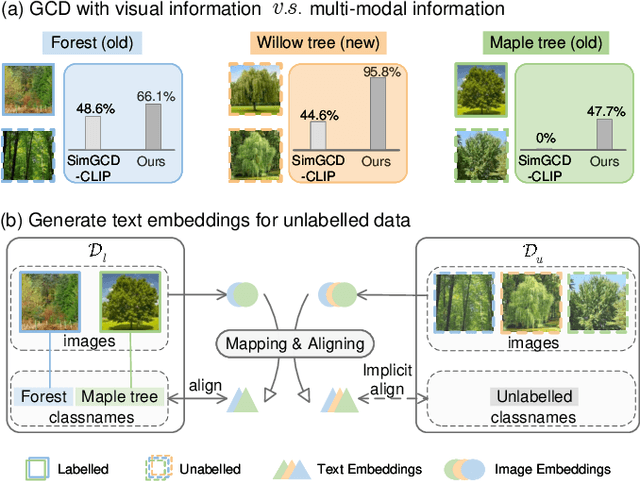
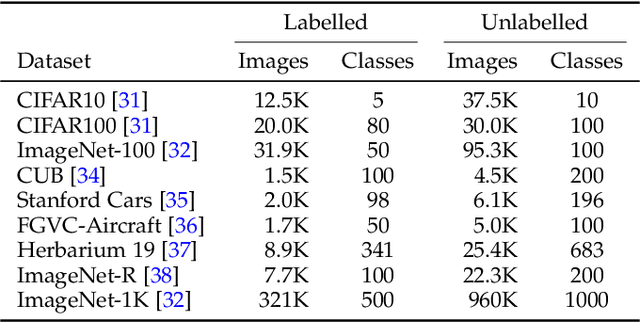
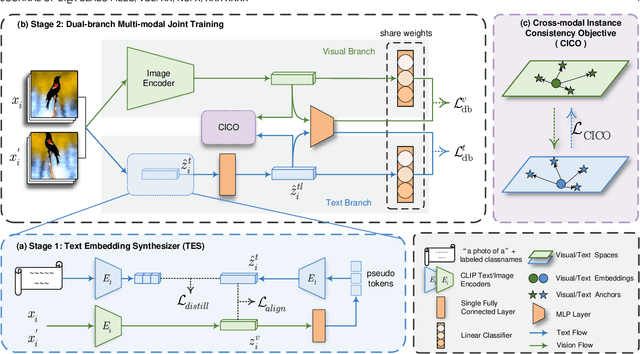

Given unlabelled datasets containing both old and new categories, generalized category discovery (GCD) aims to accurately discover new classes while correctly classifying old classes, leveraging the class concepts learned from labeled samples. Current GCD methods only use a single visual modality of information, resulting in poor classification of visually similar classes. Though certain classes are visually confused, their text information might be distinct, motivating us to introduce text information into the GCD task. However, the lack of class names for unlabelled data makes it impractical to utilize text information. To tackle this challenging problem, in this paper, we propose a Text Embedding Synthesizer (TES) to generate pseudo text embeddings for unlabelled samples. Specifically, our TES leverages the property that CLIP can generate aligned vision-language features, converting visual embeddings into tokens of the CLIP's text encoder to generate pseudo text embeddings. Besides, we employ a dual-branch framework, through the joint learning and instance consistency of different modality branches, visual and semantic information mutually enhance each other, promoting the interaction and fusion of visual and text embedding space. Our method unlocks the multi-modal potentials of CLIP and outperforms the baseline methods by a large margin on all GCD benchmarks, achieving new state-of-the-art. The code will be released at \url{https://github.com/enguangW/GET}.