 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepReduce: A Sparse-tensor Communication Framework for Distributed Deep Learning
Paper and Code
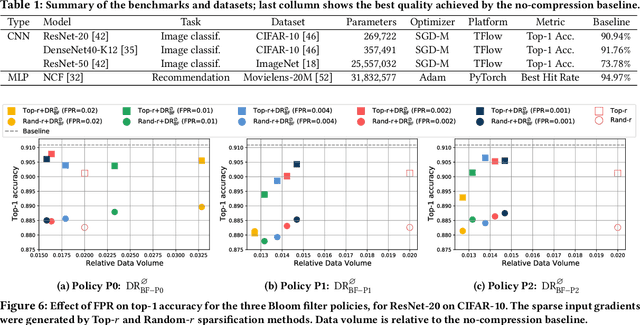
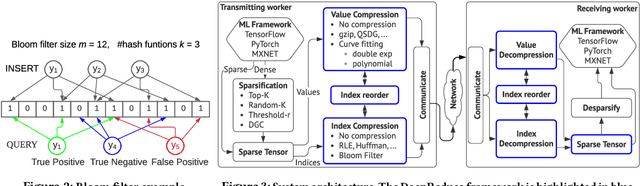
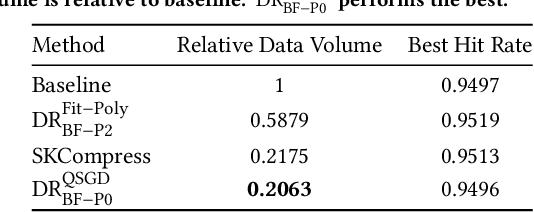
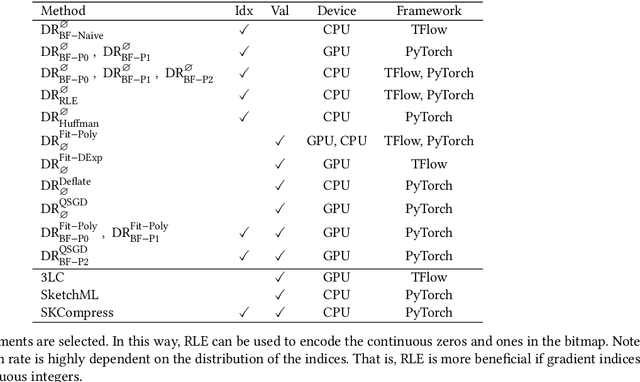
Sparse tensors appear frequently in distributed deep learning, either as a direct artifact of the deep neural network's gradients, or as a result of an explicit sparsification process. Existing communication primitives are agnostic to the peculiarities of deep learning; consequently, they impose unnecessary communication overhead. This paper introduces DeepReduce, a versatile framework for the compressed communication of sparse tensors, tailored for distributed deep learning. DeepReduce decomposes sparse tensors in two sets, values and indices, and allows both independent and combined compression of these sets. We support a variety of common compressors, such as Deflate for values, or run-length encoding for indices. We also propose two novel compression schemes that achieve superior results: curve fitting-based for values and bloom filter-based for indices. DeepReduce is orthogonal to existing gradient sparsifiers and can be applied in conjunction with them, transparently to the end-user, to significantly lower the communication overhead. As proof of concept, we implement our approach on Tensorflow and PyTorch. Our experiments with large real models demonstrate that DeepReduce transmits fewer data and imposes lower computational overhead than existing methods, without affecting the training accuracy.