 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExceeding the Limits of Visual-Linguistic Multi-Task Learning
Jul 27, 2021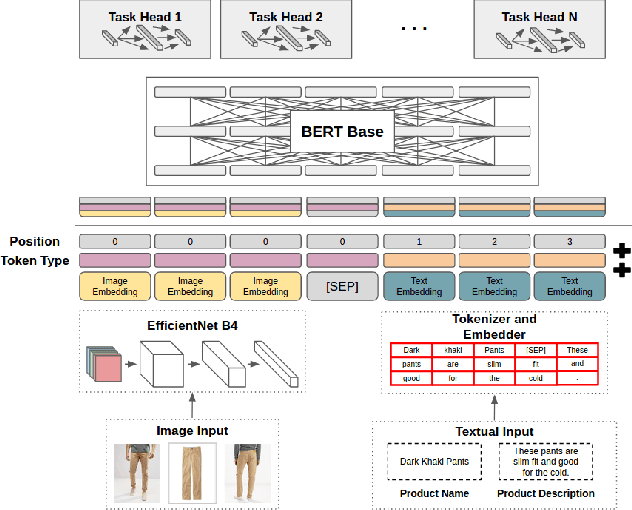
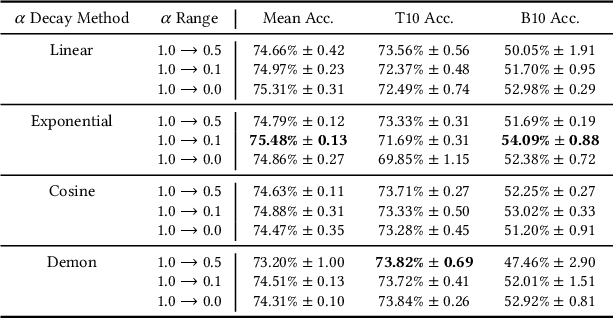
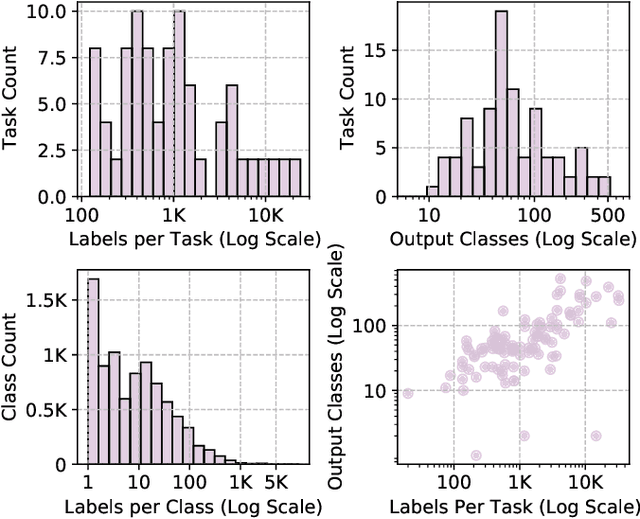
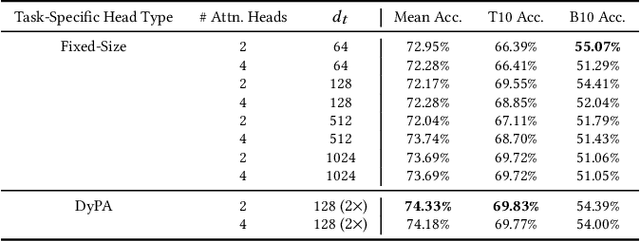
By leveraging large amounts of product data collected across hundreds of live e-commerce websites, we construct 1000 unique classification tasks that share similarly-structured input data, comprised of both text and images. These classification tasks focus on learning the product hierarchy of different e-commerce websites, causing many of them to be correlated. Adopting a multi-modal transformer model, we solve these tasks in unison using multi-task learning (MTL). Extensive experiments are presented over an initial 100-task dataset to reveal best practices for "large-scale MTL" (i.e., MTL with more than 100 tasks). From these experiments, a final, unified methodology is derived, which is composed of both best practices and new proposals such as DyPa, a simple heuristic for automatically allocating task-specific parameters to tasks that could benefit from extra capacity. Using our large-scale MTL methodology, we successfully train a single model across all 1000 tasks in our dataset while using minimal task specific parameters, thereby showing that it is possible to extend several orders of magnitude beyond current efforts in MTL.
Data Augmentation for Deep Transfer Learning
Nov 28, 2019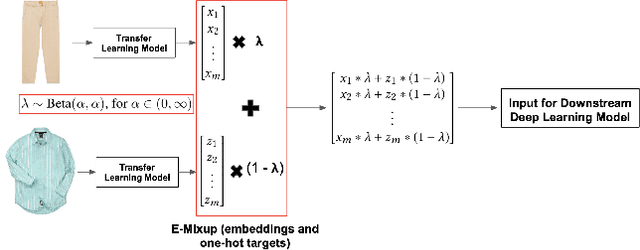
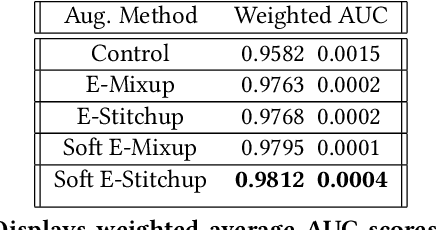
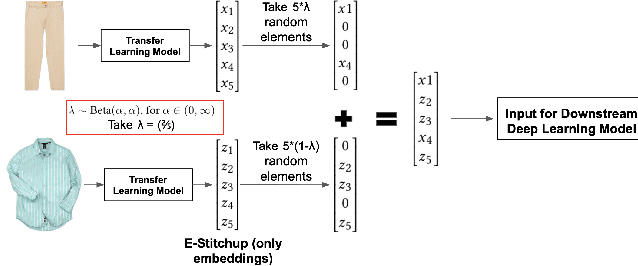
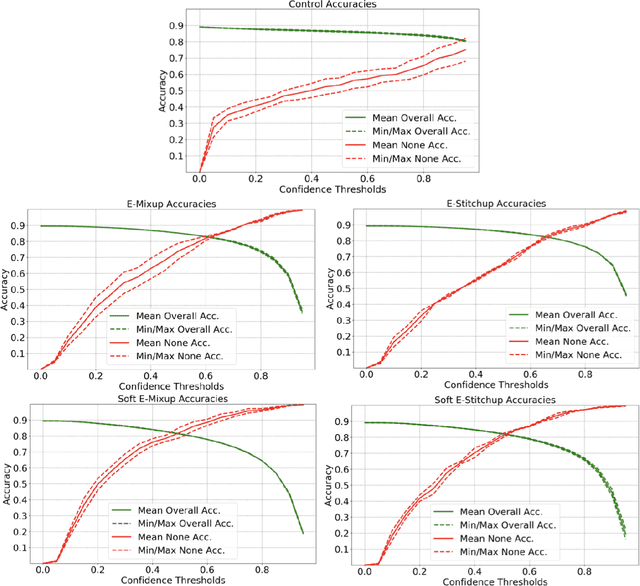
Current approaches to deep learning are beginning to rely heavily on transfer learning as an effective method for reducing overfitting, improving model performance, and quickly learning new tasks. Similarly, such pre-trained models are often used to create embedding representations for various types of data, such as text and images, which can then be fed as input into separate, downstream models. However, in cases where such transfer learning models perform poorly (i.e., for data outside of the training distribution), one must resort to fine-tuning such models, or even retraining them completely. Currently, no form of data augmentation has been proposed that can be applied directly to embedding inputs to improve downstream model performance. In this work, we introduce four new types of data augmentation that are generally applicable to embedding inputs, thus making them useful in both Natural Language Processing (NLP) and Computer Vision (CV) applications. For models trained on downstream tasks with such embedding inputs, these augmentation methods are shown to improve the AUC score of the models from a score of 0.9582 to 0.9812 and significantly increase the model's ability to identify classes of data that are not seen during training.