 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical and Experimental Study of Distributed Uplink Beamforming in the Presence of Carrier Frequency Offsets
Aug 11, 2025Realizing distributed multi-user beamforming (D-MUBF) in time division duplex (TDD)-based multi-user MIMO (MU-MIMO) systems faces significant challenges. One of the most fundamental challenges is achieving accurate over-the-air (OTA) timing and frequency synchronization among distributed access points (APs), particularly due to residual frequency offsets caused by local oscillator (LO) drifts. Despite decades of research on synchronization for MU-MIMO, there are only a few experimental studies that evaluate D-MUBF techniques under imperfect frequency synchronization among distributed antennas. This paper presents an analytical and experimental assessment of D-MUBF methods in the presence of frequency synchronization errors. We provide closed-form expressions for signal-to-interference-plus-noise ratio (SINR) as a function of channel characteristics and statistical properties of carrier frequency offset (CFO) among AP antennas. In addition, through experimental evaluations conducted with the RENEW massive MIMO testbed, we collected comprehensive datasets across various experimental scenarios. These datasets comprise uplink pilot samples for channel and CFO estimation, in addition to uplink multi-user data intended for analyzing D-MUBF techniques. By examining these datasets, we assess the performance of D-MUBF in the presence of CFO and compare the analytical predictions with empirical measurements. Furthermore, we make the datasets publicly available and provide insights on utilizing them for future research endeavors.
ADMM for Downlink Beamforming in Cell-Free Massive MIMO Systems
Sep 09, 2024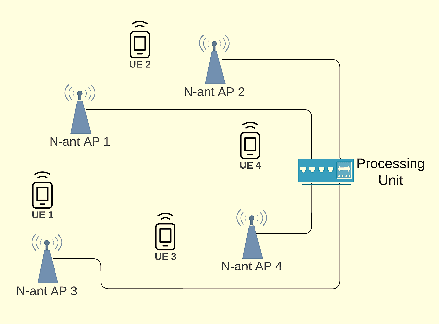

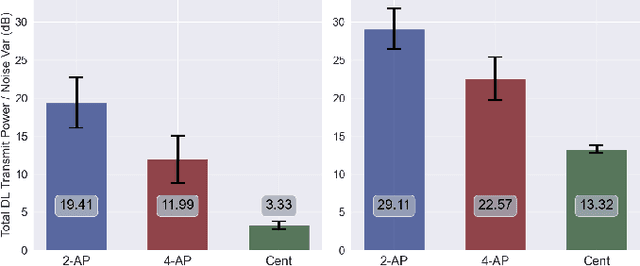
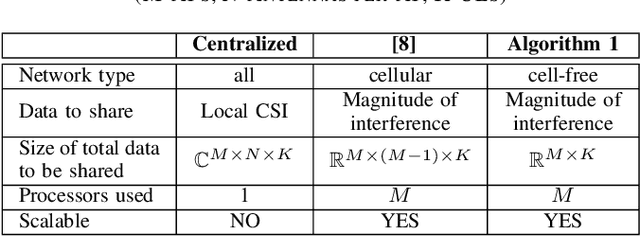
In cell-free massive MIMO systems with multiple distributed access points (APs) serving multiple users over the same time-frequency resources, downlink beamforming is done through spatial precoding. Precoding vectors can be optimally designed to use the minimum downlink transmit power while satisfying a quality-of-service requirement for each user. However, existing centralized solutions to beamforming optimization pose challenges such as high communication overhead and processing delay. On the other hand, distributed approaches either require data exchange over the network that scales with the number of antennas or solve the problem for cellular systems where every user is served by only one AP. In this paper, we formulate a multi-user beamforming optimization problem to minimize the total transmit power subject to per-user SINR requirements and propose a distributed optimization algorithm based on the alternating direction method of multipliers (ADMM) to solve it. In our method, every AP solves an iterative optimization problem using its local channel state information. APs only need to share a real-valued vector of interference terms with the size of the number of users. Through simulation results, we demonstrate that our proposed algorithm solves the optimization problem within tens of ADMM iterations and can effectively satisfy per-user SINR constraints.
ML-Based Feedback-Free Adaptive MCS Selection for Massive Multi-User MIMO
Oct 20, 2023



As wireless communication systems strive to improve spectral efficiency, there has been a growing interest in employing machine learning (ML)-based approaches for adaptive modulation and coding scheme (MCS) selection. In this paper, we introduce a new adaptive MCS selection framework for massive MIMO systems that operates without any feedback from users by solely relying on instantaneous uplink channel estimates. Our proposed method can effectively operate in multi-user scenarios where user feedback imposes excessive delay and bandwidth overhead. To learn the mapping between the user channel matrices and the optimal MCS level of each user, we develop a Convolutional Neural Network (CNN)-Long Short-Term Memory Network (LSTM)-based model and compare the performance with the state-of-the-art methods. Finally, we validate the effectiveness of our algorithm by evaluating it experimentally using real-world datasets collected from the RENEW massive MIMO platform.
Accelerated massive MIMO detector based on annealed underdamped Langevin dynamics
Oct 26, 2022We propose a multiple-input multiple-output (MIMO) detector based on an annealed version of the \emph{underdamped} Langevin (stochastic) dynamic. Our detector achieves state-of-the-art performance in terms of symbol error rate (SER) while keeping the computational complexity in check. Indeed, our method can be easily tuned to strike the right balance between computational complexity and performance as required by the application at hand. This balance is achieved by tuning hyperparameters that control the length of the simulated Langevin dynamic. Through numerical experiments, we demonstrate that our detector yields lower SER than competing approaches (including learning-based ones) with a lower running time compared to a previously proposed \emph{overdamped} Langevin-based MIMO detector.
Annealed Langevin Dynamics for Massive MIMO Detection
May 11, 2022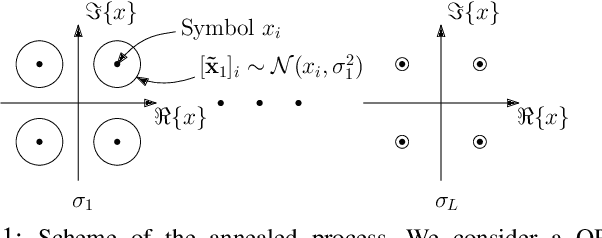
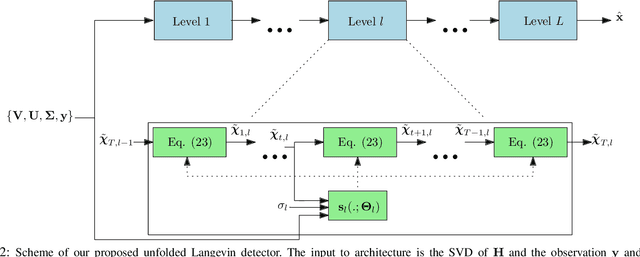
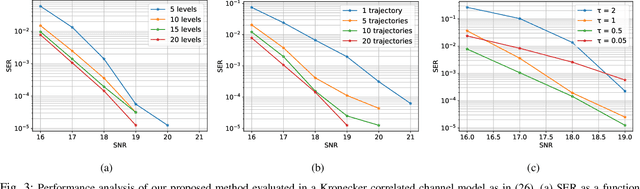
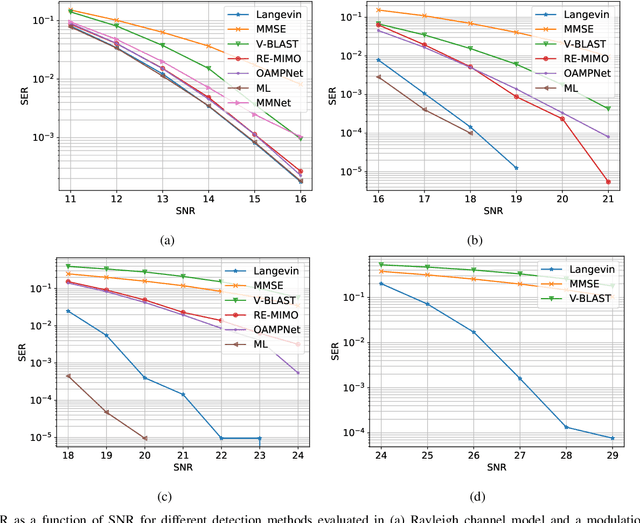
Solving the optimal symbol detection problem in multiple-input multiple-output (MIMO) systems is known to be NP-hard. Hence, the objective of any detector of practical relevance is to get reasonably close to the optimal solution while keeping the computational complexity in check. In this work, we propose a MIMO detector based on an annealed version of Langevin (stochastic) dynamics. More precisely, we define a stochastic dynamical process whose stationary distribution coincides with the posterior distribution of the symbols given our observations. In essence, this allows us to approximate the maximum a posteriori estimator of the transmitted symbols by sampling from the proposed Langevin dynamic. Furthermore, we carefully craft this stochastic dynamic by gradually adding a sequence of noise with decreasing variance to the trajectories, which ensures that the estimated symbols belong to a pre-specified discrete constellation. Based on the proposed MIMO detector, we also design a robust version of the method by unfolding and parameterizing one term -- the score of the likelihood -- by a neural network. Through numerical experiments in both synthetic and real-world data, we show that our proposed detector yields state-of-the-art symbol error rate performance and the robust version becomes noise-variance agnostic.
Detection by Sampling: Massive MIMO Detector based on Langevin Dynamics
Feb 24, 2022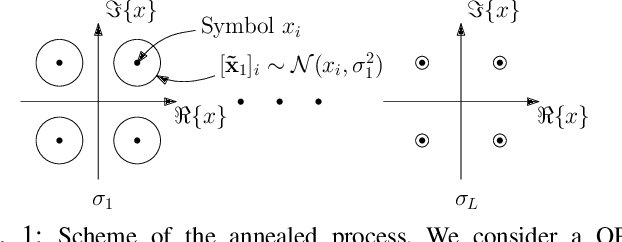
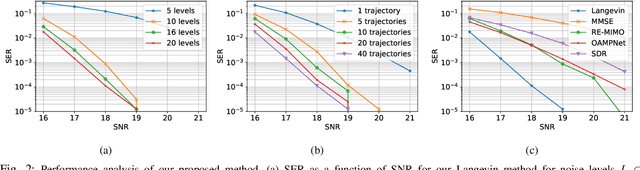
Optimal symbol detection in multiple-input multiple-output (MIMO) systems is known to be an NP-hard problem. Hence, the objective of any detector of practical relevance is to get reasonably close to the optimal solution while keeping the computational complexity in check. In this work, we propose a MIMO detector based on an annealed version of Langevin (stochastic) dynamics. More precisely, we define a stochastic dynamical process whose stationary distribution coincides with the posterior distribution of the symbols given our observations. In essence, this allows us to approximate the maximum a posteriori estimator of the transmitted symbols by sampling from the proposed Langevin dynamic. Furthermore, we carefully craft this stochastic dynamic by gradually adding a sequence of noise with decreasing variance to the trajectories, which ensures that the estimated symbols belong to a pre-specified discrete constellation. Through numerical experiments, we show that our proposed detector yields state-of-the-art symbol error rate performance.
Robust MIMO Detection using Hypernetworks with Learned Regularizers
Oct 13, 2021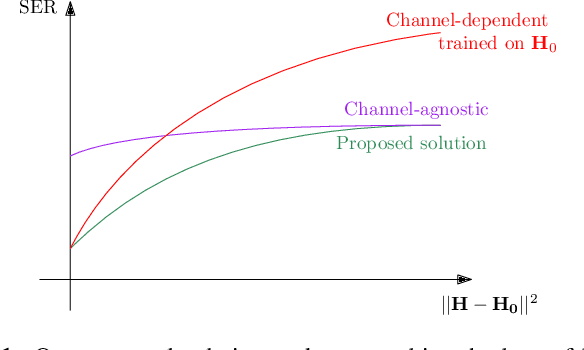
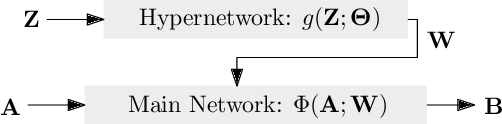
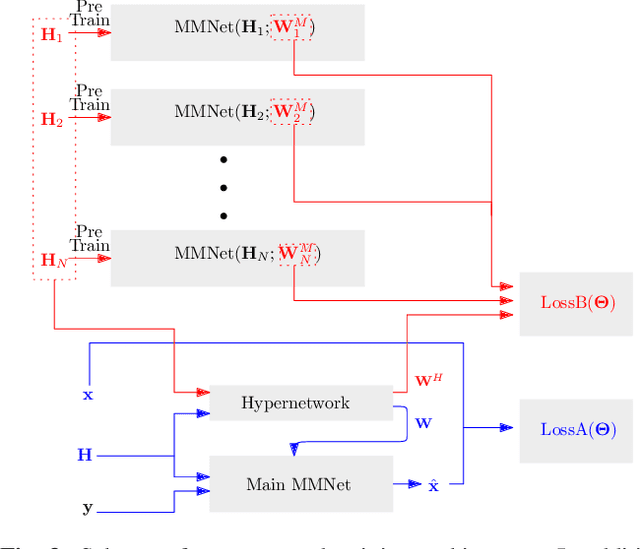
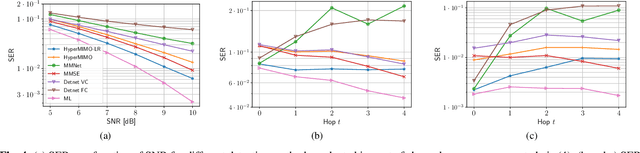
Optimal symbol detection in multiple-input multiple-output (MIMO) systems is known to be an NP-hard problem. Recently, there has been a growing interest to get reasonably close to the optimal solution using neural networks while keeping the computational complexity in check. However, existing work based on deep learning shows that it is difficult to design a generic network that works well for a variety of channels. In this work, we propose a method that tries to strike a balance between symbol error rate (SER) performance and generality of channels. Our method is based on hypernetworks that generate the parameters of a neural network-based detector that works well on a specific channel. We propose a general framework by regularizing the training of the hypernetwork with some pre-trained instances of the channel-specific method. Through numerical experiments, we show that our proposed method yields high performance for a set of prespecified channel realizations while generalizing well to all channels drawn from a specific distribution.